이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
featureInputLayer
특징 입력 계층
설명
특징 입력 계층은 신경망에 특징 데이터를 입력하고 데이터 정규화를 적용합니다. 특징을 나타내는, 숫자형 스칼라로 구성된 데이터 세트(공간 차원 또는 시간 차원이 없는 데이터)가 있는 경우 이 계층을 사용하십시오.
영상 입력의 경우 imageInputLayer를 사용하십시오.
생성
설명
layer = featureInputLayer(numFeatures)InputSize 속성을 지정된 특징 개수로 설정합니다.
layer = featureInputLayer(numFeatures,Name=Value)
입력 인수
이름-값 인수
속성
예제
이름이 "input"이고 21개의 특징으로 구성된 관측값을 갖는 특징 입력 계층을 만듭니다.
layer = featureInputLayer(21,Name="input")layer =
FeatureInputLayer with properties:
Name: 'input'
InputSize: 21
SplitComplexInputs: 0
Hyperparameters
Normalization: 'none'
NormalizationDimension: 'auto'
Layer 배열에 특징 입력 계층을 포함시킵니다.
numFeatures = 21;
numClasses = 3;
layers = [
featureInputLayer(numFeatures)
fullyConnectedLayer(numClasses)
softmaxLayer]layers =
3×1 Layer array with layers:
1 '' Feature Input 21 features
2 '' Fully Connected 3 fully connected layer
3 '' Softmax softmax
입력 영상의 크기, 각 관측값의 특징 개수, 클래스 개수, 컨벌루션 계층의 필터 크기와 개수를 정의합니다.
imageInputSize = [28 28 1]; numFeatures = 1; numClasses = 10; filterSize = 5; numFilters = 16;
두 개의 입력값이 있는 신경망을 만들려면 신경망을 두 부분으로 정의한 다음 두 부분을 합칩니다. 예를 들어 결합 계층을 사용할 수 있습니다.
dlnetwork 객체를 만듭니다.
net = dlnetwork;
신경망의 첫 번째 부분을 정의합니다. 영상 분류 계층을 정의하고 마지막 완전 연결 계층 앞에 평탄화 계층과 결합 계층을 포함합니다.
layers = [
imageInputLayer(imageInputSize,Normalization="none")
convolution2dLayer(filterSize,numFilters,Name="conv")
reluLayer
fullyConnectedLayer(50)
flattenLayer
concatenationLayer(1,2,Name="concat")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = addLayers(net,layers);신경망의 두 번째 부분에서는 특징 입력 계층을 추가하고 이를 결합 계층의 두 번째 입력에 연결합니다.
featInput = featureInputLayer(numFeatures,Name="features"); net = addLayers(net,featInput); net = connectLayers(net,"features","concat/in2")
net =
dlnetwork with properties:
Layers: [9×1 nnet.cnn.layer.Layer]
Connections: [8×2 table]
Learnables: [6×3 table]
State: [0×3 table]
InputNames: {'imageinput' 'features'}
OutputNames: {'softmax'}
Initialized: 0
View summary with summary.
신경망을 시각화합니다.
plot(net)

숫자형 특징으로 구성된 데이터 세트(예: 공간 차원 또는 시간 차원이 없는 테이블 형식 데이터)가 있는 경우, 특징 입력 계층을 사용하여 심층 신경망을 훈련시킬 수 있습니다.
CSV 파일 "transmissionCasingData.csv"에서 변속기 케이싱 데이터를 읽어 들입니다.
filename = "transmissionCasingData.csv"; tbl = readtable(filename,TextType="String");
convertvars 함수를 사용하여 예측을 위한 레이블을 categorical형으로 변환합니다.
labelName = "GearToothCondition"; tbl = convertvars(tbl,labelName,"categorical");
범주형 특징을 사용하여 신경망을 훈련시키려면 먼저 범주형 특징을 숫자형으로 변환해야 합니다. 먼저 모든 범주형 입력 변수의 이름을 포함하는 string형 배열을 지정하여 convertvars 함수를 사용해서 범주형 예측 변수를 categorical형으로 변환합니다. 이 데이터 세트에는 이름이 "SensorCondition"과 "ShaftCondition"인 범주형 특징이 2개 있습니다.
categoricalPredictorNames = ["SensorCondition" "ShaftCondition"]; tbl = convertvars(tbl,categoricalPredictorNames,"categorical");
범주형 입력 변수를 루프를 사용해 순환합니다. 각 변수에 대해 onehotencode 함수를 사용하여 categorical형 값을 one-hot 형식으로 인코딩된 벡터로 변환합니다.
for i = 1:numel(categoricalPredictorNames) name = categoricalPredictorNames(i); tbl.(name) = onehotencode(tbl.(name),2); end
테이블의 처음 몇 개 행을 봅니다. 범주형 예측 변수가 여러 개의 열로 분할된 것을 볼 수 있습니다.
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ______________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0 No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 0 1 1 0 No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 0 1 0 1 No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 0 1 0 1 No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 0 1 0 1 No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1 No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 0 1 0 1 No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
데이터 세트의 클래스 이름을 봅니다.
classNames = categories(tbl{:,labelName})classNames = 2×1 cell
{'No Tooth Fault'}
{'Tooth Fault' }
테스트를 위해 데이터를 남겨 둡니다. 데이터의 85%가 포함된 훈련 세트와 데이터의 나머지 15%가 포함된 테스트 세트로 데이터를 분할합니다. 데이터를 분할하려면 이 예제에 지원 파일로 첨부된 trainingPartitions 함수를 사용합니다. 이 파일에 액세스하려면 이 예제를 라이브 스크립트로 여십시오.
numObservations = size(tbl,1); [idxTrain,idxTest] = trainingPartitions(numObservations,[0.85 0.15]); tblTrain = tbl(idxTrain,:); tblTest = tbl(idxTest,:);
데이터를 trainnet 함수가 지원하는 형식으로 변환합니다. 예측 변수와 목표값을 각각 숫자형 배열과 categorical형 배열로 변환합니다. 특징 입력값의 경우, 신경망은 행이 관측값에 대응하고 열이 특징에 대응하도록 구성된 데이터가 필요합니다. 데이터가 이러한 레이아웃이 아니라면 데이터를 전처리해서 이러한 레이아웃을 갖도록 만들거나 데이터 형식을 사용하여 레이아웃 정보를 제공할 수 있습니다. 자세한 내용은 Deep Learning Data Formats 항목을 참조하십시오.
predictorNames = ["SigMean" "SigMedian" "SigRMS" "SigVar" "SigPeak" "SigPeak2Peak" ... "SigSkewness" "SigKurtosis" "SigCrestFactor" "SigMAD" "SigRangeCumSum" ... "SigCorrDimension" "SigApproxEntropy" "SigLyapExponent" "PeakFreq" ... "HighFreqPower" "EnvPower" "PeakSpecKurtosis" "SensorCondition" "ShaftCondition"]; XTrain = table2array(tblTrain(:,predictorNames)); TTrain = tblTrain.(labelName); XTest = table2array(tblTest(:,predictorNames)); TTest = tblTest.(labelName);
특징 입력 계층을 갖는 신경망을 정의하고 특징 개수를 지정합니다. 또한, Z-점수 정규화를 사용하여 데이터를 정규화하도록 입력 계층을 구성합니다.
numFeatures = size(XTrain,2);
numClasses = numel(classNames);
layers = [
featureInputLayer(numFeatures,Normalization="zscore")
fullyConnectedLayer(16)
layerNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];다음과 같이 훈련 옵션을 지정합니다.
L-BFGS 솔버를 사용하여 훈련시킵니다. 이 솔버는 신경망이 작고 데이터가 메모리에 들어가는 정도의 크기인 작업에 적합합니다.
CPU를 사용하여 훈련시킵니다. 신경망과 데이터가 작으므로 CPU가 더 적절합니다.
훈련 진행 상황을 플롯으로 표시합니다.
세부 정보가 출력되지 않도록 합니다.
options = trainingOptions("lbfgs", ... ExecutionEnvironment="cpu", ... Plots="training-progress", ... Verbose=false);
trainnet 함수를 사용하여 신경망을 훈련시킵니다. 분류에는 교차 엔트로피 손실을 사용합니다.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
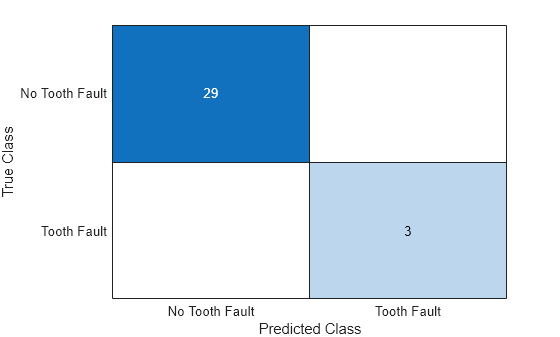
레이블이 지정된 테스트 세트를 사용하여 신경망을 테스트합니다. 단일 레이블 분류의 경우 정확도를 평가합니다. 정확도는 신경망이 올바르게 예측하는 레이블의 비율입니다.
accuracy = testnet(net,XTest,TTest,"accuracy")accuracy = 100
훈련된 신경망을 사용하여 테스트 데이터의 레이블을 예측합니다. 훈련된 신경망을 사용하여 분류 점수를 예측한 다음 scores2label 함수를 사용하여 예측값을 레이블로 변환합니다.
scoresTest = minibatchpredict(net,XTest); YTest = scores2label(scoresTest,classNames);
예측값을 혼동행렬 차트로 시각화합니다.
confusionchart(TTest,YTest)