confusionmat
분류 문제에 대한 혼동행렬 계산
구문
설명
예제
분류 문제에 대한 예측 레이블과 실제 레이블의 샘플을 불러옵니다. trueLabels는 영상 분류 문제에 대한 실제 레이블이고 predictedLabels는 컨벌루션 신경망의 예측입니다.
load('Cifar10Labels.mat','trueLabels','predictedLabels');
숫자형 혼동행렬을 계산합니다. order는 혼동행렬의 클래스 순서입니다.
[m,order] = confusionmat(trueLabels,predictedLabels)
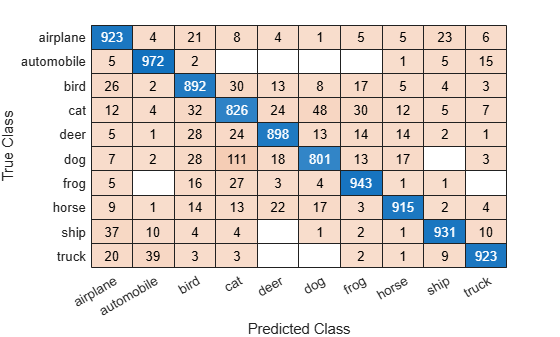
m = 10×10
923 4 21 8 4 1 5 5 23 6
5 972 2 0 0 0 0 1 5 15
26 2 892 30 13 8 17 5 4 3
12 4 32 826 24 48 30 12 5 7
5 1 28 24 898 13 14 14 2 1
7 2 28 111 18 801 13 17 0 3
5 0 16 27 3 4 943 1 1 0
9 1 14 13 22 17 3 915 2 4
37 10 4 4 0 1 2 1 931 10
20 39 3 3 0 0 2 1 9 923
order = 10×1 categorical
airplane
automobile
bird
cat
deer
dog
frog
horse
ship
truck
confusionchart를 사용하여 혼동행렬을 혼동행렬 차트로 플로팅할 수 있습니다.
figure cm = confusionchart(m,order);
혼동행렬을 먼저 계산한 다음 플로팅할 필요가 없습니다. 대신, 실제 레이블과 예측 레이블에서 직접 혼동행렬 차트를 플로팅합니다. 열과 행의 요약과 제목도 추가할 수 있습니다.
figure cm = confusionchart(trueLabels,predictedLabels, ... 'Title','My Title', ... 'RowSummary','row-normalized', ... 'ColumnSummary','column-normalized');
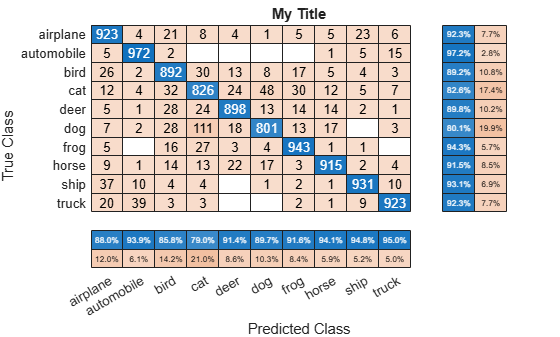
ConfusionMatrixChart 객체는 NormalizedValues 속성에 숫자형 혼동행렬을 저장하고 ClassLabels 속성에 클래스를 저장합니다.
cm.NormalizedValues
ans = 10×10
923 4 21 8 4 1 5 5 23 6
5 972 2 0 0 0 0 1 5 15
26 2 892 30 13 8 17 5 4 3
12 4 32 826 24 48 30 12 5 7
5 1 28 24 898 13 14 14 2 1
7 2 28 111 18 801 13 17 0 3
5 0 16 27 3 4 943 1 1 0
9 1 14 13 22 17 3 915 2 4
37 10 4 4 0 1 2 1 931 10
20 39 3 3 0 0 2 1 9 923
cm.ClassLabels
ans = 10×1 categorical
airplane
automobile
bird
cat
deer
dog
frog
horse
ship
truck
입력 인수
출력 인수
대체 기능
confusionchart를 사용하여 혼동행렬을 계산하고 플로팅할 수 있습니다. 또한confusionchart는 데이터에 대한 요약 통계량을 표시하고 클래스별 정밀도(양성예측도), 클래스별 재현율(참양성률) 또는 올바르게 분류된 총 관측값 개수에 따라 혼동행렬의 클래스를 정렬합니다.