화자 인식 및 화자 구분
화자 인식에는 누가 말하고 있는지 식별하고 음성 신호에서 화자의 신원을 확인하는 작업이 포함됩니다. 화자 구분은 화자의 아이덴티티를 기반으로 음성 신호를 분할하는 과정입니다. 다음 예제에서는 다양한 AI 기법을 화자 인식 및 화자 구분 워크플로에 적용하는 방법을 보여줍니다.
함수
speakerEmbeddings | Extract speaker embeddings from speech (R2024b 이후) |
추천 예제
Speaker Diarization Using Pretrained AI Models
Use the speakerEmbeddings function to extract compact speaker
representations and perform speaker diarization.

Speaker Identification Using Pitch and MFCC
Use machine learning to identify people based on features extracted from recorded speech.
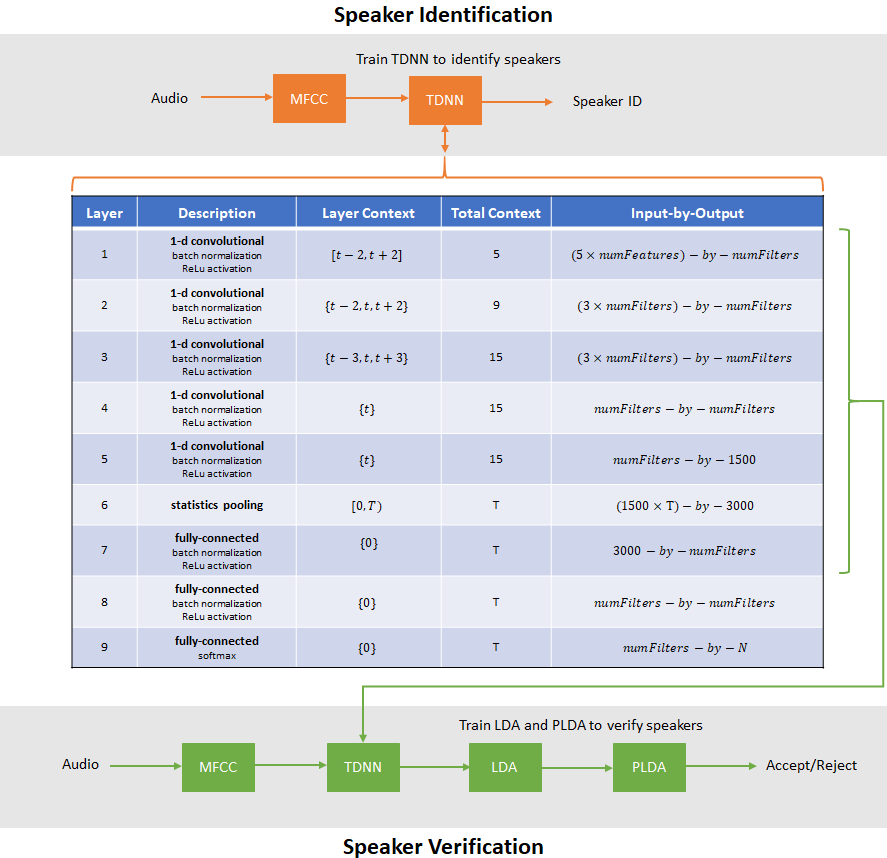
Speaker Recognition Using x-vectors
Develop an x-vector system to perform speaker recognition.
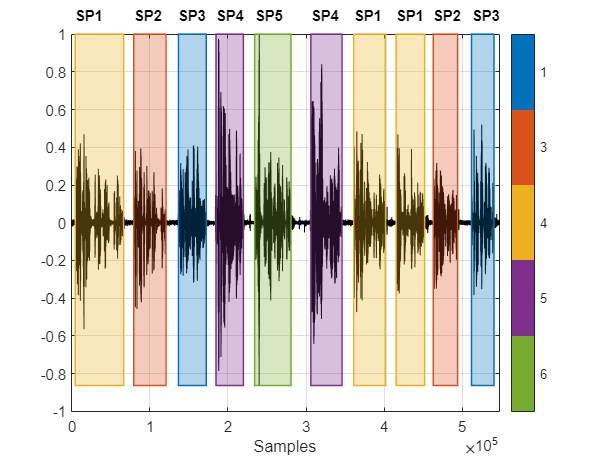
Speaker Diarization Using x-vectors
Speaker diarization is the process of partitioning an audio signal into segments according to speaker identity. It answers the question "who spoke when" without prior knowledge of the speakers and, depending on the application, without prior knowledge of the number of speakers.
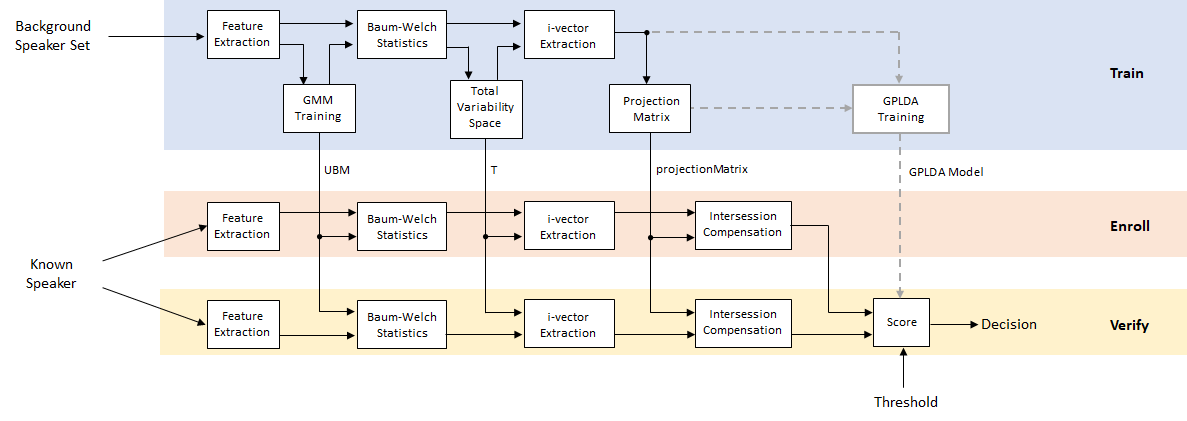
Speaker Verification Using i-vectors
Speaker verification, or authentication, is the task of confirming that the identity of a speaker is who they purport to be. Speaker verification has been an active research area for many years. An early performance breakthrough was to use a Gaussian mixture model and universal background model (GMM-UBM) [1] on acoustic features (usually mfcc). For an example, see Speaker Verification Using Gaussian Mixture Model. One of the main difficulties of GMM-UBM systems involves intersession variability. Joint factor analysis (JFA) was proposed to compensate for this variability by separately modeling inter-speaker variability and channel or session variability [2] [3]. However, [4] discovered that channel factors in the JFA also contained information about the speakers, and proposed combining the channel and speaker spaces into a total variability space. Intersession variability was then compensated for by using backend procedures, such as linear discriminant analysis (LDA) and within-class covariance normalization (WCCN), followed by a scoring, such as the cosine similarity score. [5] proposed replacing the cosine similarity scoring with a probabilistic LDA (PLDA) model. [11] and [12] proposed a method to Gaussianize the i-vectors and therefore make Gaussian assumptions in the PLDA, referred to as G-PLDA or simplified PLDA. While i-vectors were originally proposed for speaker verification, they have been applied to many problems, like language recognition, speaker diarization, emotion recognition, age estimation, and anti-spoofing [10]. Recently, deep learning techniques have been proposed to replace i-vectors with d-vectors or x-vectors [8] [6].
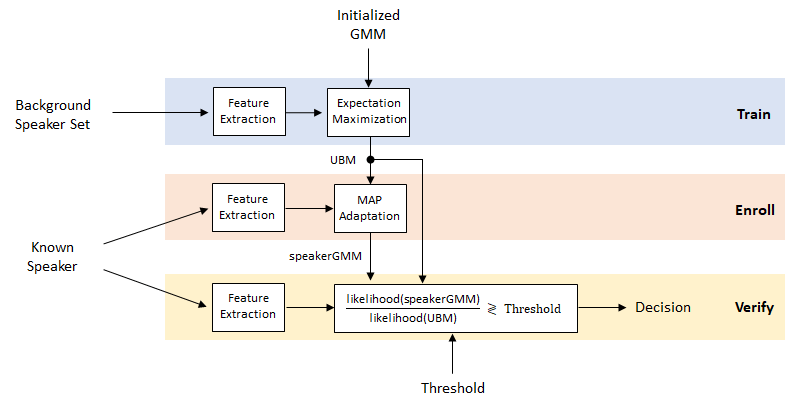
Speaker Verification Using Gaussian Mixture Model
Speaker verification, or authentication, is the task of verifying that a given speech segment belongs to a given speaker. In speaker verification systems, there is an unknown set of all other speakers, so the likelihood that an utterance belongs to the verification target is compared to the likelihood that it does not. This contrasts with speaker identification tasks, where the likelihood of each speaker is calculated, and those likelihoods are compared. Both speaker verification and speaker identification can be text dependent or text independent. In this example, you create a text-dependent speaker verification system using a Gaussian mixture model/universal background model (GMM-UBM).

Speaker Identification Using Custom SincNet Layer and Deep Learning
Perform speech recognition using a custom deep learning layer that implements a mel-scale filter bank.