MATLAB里的天籁之音 —— 浅谈 MATLAB 语音与声学应用
作者 : 单博、MathWorks
遥想当年,从霹雳五号到星球大战,都有智能语音助理的身影。而如今,智能语音设备早已从科幻小说电影,走进现实。2014年11月亚马逊的Echo音箱首开先河,随后各大厂商争先恐后的发布自己的智能音箱。
音频和声学这个曾经比较小众的领域,一夜之间从门可罗雀,变得门庭若市。音频和声学领域的应用,也成了技术圈里的热门话题。
主动降噪耳机耳麦,风靡各路达人,幸福感飙升神器;智能音箱绘声绘色的给孩子们讲故事,给老人们念新闻读菜谱;先进的新型人工耳蜗/助听器,帮听障患者“听见光明”;家庭影院,给你足不出户,即可身临其境的震撼影音体验。
MATLAB其实在音频和声学领域已深耕多年,您身边的众多音频设备,背后都有MATLAB的身影。从顶级音响厂商Bower & Wilkins旗舰低音炮,飞利浦的Ambisound Soundbar家庭影院系统,到听力设备翘楚瑞士Sonova的助听器,以及国内和国外一些市占率很高的智能音箱,都受益于MATLAB。
MATLAB到底能为音频设备的研发,带来哪些助益?听我为您娓娓道来。
一、音频算法快速原型
音频工程师可能都有体会,音频算法流程的独有特点,就是在做实际的硬件原型之前,需要首先把设计好的音频算法,进行基于听觉的测试。一般还会分为早期的算法试音,后期的硬件原型试音。
音频算法原型
1. 早期原型——试音(Listen Based Audition )
音频开发通常有一个独特的试音阶段,这个试音的过程(Listen Based Audition ),决定了这个算法是否值得进行产品化。这个过程需要满足三个条件:
1. 实时;必须是对实时的音频流进行处理,并实时的听到算法的效果;
2. 参数可调:在音频算法的实时测试中,算法的很多参数,都需要是可以灵活调节的;
3. 可视化:音频算法调节过程中,还需要实时对调整的效果,可视化。 让算法运行不难,难的是按照上面四条,实时试音。

专业试音环境
过去为了进行这种试音,通常有2种方法,
第一种,是将MATLAB算法挂到第三方的API上,比较流行的就是PortAudio,但这样的方式,仍然会涉及一些底层C代码的编写,而且还需要手工维护PortAudio,比如初始化、打开、关闭音频流的一系列底层操作和维护。另外,有没有小伙伴遇到过系统依赖性和兼容性的问题?嗯,那你不是一个人。
第2种,是手工把MATLAB音频算法转成底层的C/C++代码,然后再转成exe、dll形式,去使用。手写C代码会很耗时,连一个数据包的访问,都得依靠for循环,而且很多时候音频算法,测试完这个C代码也就没用了。
小伙伴们,其实你们手里的MATLAB音频算法,就可以直接支持原型听音测试。惊不惊喜意不意外?而且有两种方式:
1. MATLAB直接进行实时音频数据流的仿真

MATLAB的Audio Toolbox可以提供了一个神奇的APP——Audio TestBench。可以直接加载你的MATLAB音频算法,还可直接访问你的底层音频硬件作为音频的输入/输出,比如音频信号源、信号发生器、音频采集卡、MIDI Key、音频功放等等,你要的它都支持。话不多说,给你看看这个小伙伴:
2. 另一种方式,就是利用MATLAB的C代码生成功能,直接把MATLAB音频算法自动转化成C代码,打包成各种插件(Plugin)。
这样很多音频工程师,就可以仍然在他们心爱的音频工作站上,方便的直接以插件形式,加载音频算法,实时完成算法的早期试音了。话不多说,请看下面视频,看到视频中演示的实时试音过程了吧?加载自动生成的音频算法插件,可以实时调整算法参数,实时显示调解效果,还可以回传给MATLAB做时域和频域的分析和显示。元芳,你怎么看?MATLAB可远不只是用来纯算法仿真的吧?
2. 后期硬件原型
刚才我们介绍的是,音频算法早期的试音阶段,MATLAB能够支持的两种快速原型,而到了项目开发的后期,我们还需要将算法变成嵌入式代码,实时运行在嵌入式硬件上,这时就是非常接近最后实际产品的硬件原型了。
此时考察的除了有我们的音频算法,还有在特定嵌入式处理器、操作系统以及麦克风阵列的的平台中,联合在一起运行的实际效果了。
你是不是以为,要心事重重的开始手写底层C/C++代码了?且慢。
项目后期的硬件原型固然重要,但是到了这个阶段,其实产品的很多细节还有待完善,甚至还有可能出现算法的反复调整和迭代,如果每次都需要手工完成全套算法的底层C代码的编写和调试,那项目周期一定会变得漫长,调试过程一定会变得痛苦。
其实近些年很多领先的声学厂商,都在采用另一种新方式,来快速得到实际的硬件原型了。比如飞利浦快速开发高保真家庭影院环绕立体声系统,比如顶级音响厂商Bower & Wilkins的旗舰级重低音扬声器DB1D、DB2D、DB3D。
这是借助MATLAB的嵌入式C代码生成功能,直接将您的算法生成嵌入式的C代码,实时运行在嵌入式硬件上。直接所见即所得的,得到您算法的硬件原型,在实际硬件运行对实际效果进行测试和评估。而只有在快速反复尝试各种算法和配置,得到最优方案后,才会在嵌入式硬件上进行底层代码实现,这是不是效率高了很多?飞利浦的开发团队,一天内即完成快速原型试音演示,可以在几天内完成新算法的验证而非几周。
iLab DSP工程师Jan Tielen表示:“没有Simulink,我们可能需要两到三周的时间来编写新算法并对其进行测试,以测试其是否具有所需的声学效果。” “使用Simulink,我们可以非常快速地测试评估创新想法,有时甚至只需要几个小时。” 嗯~Nice!

再举一个例子,关于主动降噪的。主动降噪的应用既有普通消费品耳机耳麦,也有很多车辆把静谧性作为卖点,比如JVC公司意大利团队,就是基于MATLAB进行从原始音频算法开发、到前期算法仿真,一直到后期的硬件原型实车测试、验证的。实车测试,不必再急三火四、挥汗如雨;工程师们可以气定神闲的调好算法,自动生成底层代码,实时进行算法优化迭代效果测评。生活可以更美好!

下面这段视频,为您演示直接把MATLAB主动降噪算法,生成代码并实时运行在speedgoat设备。这样您就可以测试和评估,您的创新算法在实际硬件环境中的真实效果。
您可以看到这上面这段视频之初,管路左侧代表噪声源,右侧模拟人耳,左侧的蓝色噪声到达右侧时,如红色部分模拟出来的主动降噪声波,恰好以同样幅度和反相的形式到达。那么就会恰好峰谷相消,达到去除噪声的目的。在48秒您会看到打开噪声源之初,右侧测得的噪声是将近90dB,而54秒是用Simulink将主动降噪算法自动生成代码,部署到speedgoat中,实时运行我们的算法,您将看到此时测得噪声直线下降,一直降到70dB左右,也就实际下降了20dB左右。
您也可以借助MATLAB Support Package For Android或Simulink Support Package For Android,将算法部署在您的Android设备上进行运行,算法执行中可以直接访问设备上的摄像头、麦克风以及加速计等等传感器。
简要总结:
对于音频研发过程中至关重要的前期算法试音和后期硬件原型试音,您都可以将手中的MATLAB算法,自如的进行实时试音,对您创新性的奇思妙想,所见即所得的进行原型测试评估。
二、混乱中的秩序——浅谈声源分离
首先,有很多初步尝试过语音指令识别的童鞋,觉得看似黑科技的智能音箱也不过如此云云。其实关键词唤醒或者指令识别,仅是智能音箱设计工作的一小部分。一个粗略的构成图如下所示。
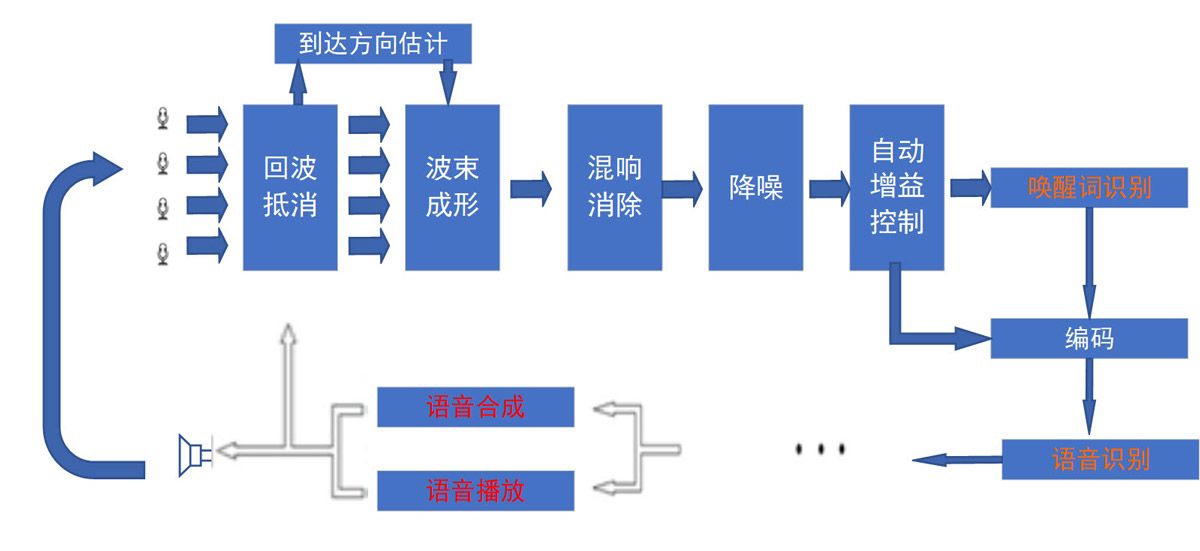
声源分离
实际使用场景中,往往会有多个声源,比如客厅里的电视、空调、聊天的家人、吵闹的小朋友,还有声音在墙壁和玻璃发生反射的回波,如果希望在这样典型的使用环境中,正常使用语音唤醒和指令识别,那么就需要从这一些列采集到的声音中提取出,我们需要的那路声音,这里介绍两种方法:波束成形和基于掩模的深度学习音频分离。
1. 波束成形
从麦克风阵列得到的多通道音频信号,需要依次完成回声抵消,将音箱自己扬声器播放出去的声音抵消掉。而后进行波束成形,估计说话人的空间方向,再针对说话人的方向进行波束成形,这样就只有特定方向的语音进入系统;接下来还要进行去混响、降噪、自动增益控制(AGC),然后才是您觉得简单的关键词唤醒等等,您可以看到关键词识别、语音识别的深度学习仅仅是一小部分。
我们首先来聊聊这个麦克风阵列的波束成形。
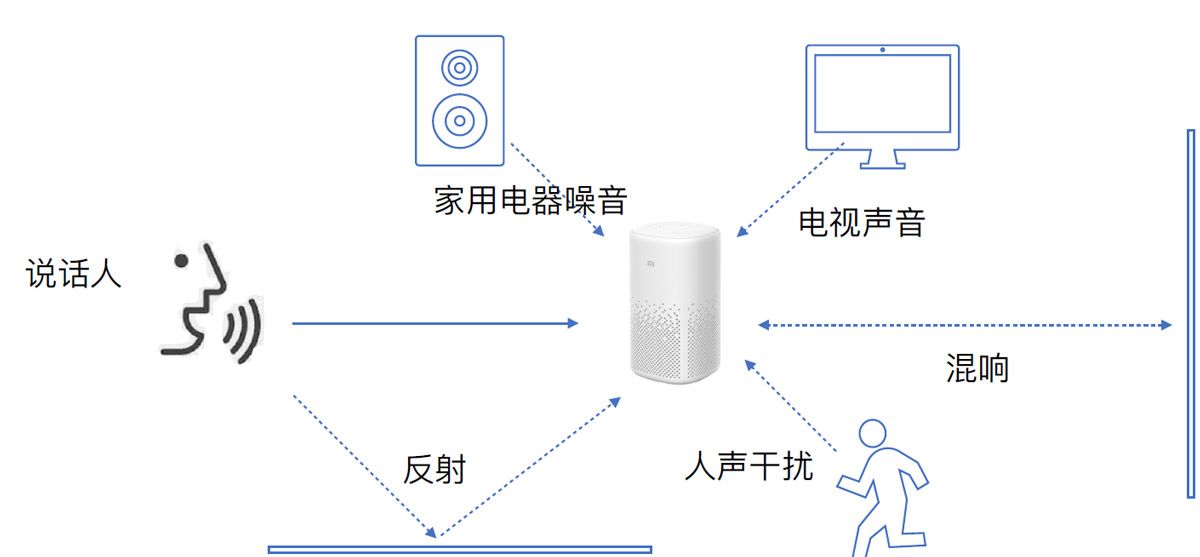
因为,我们知道实际使用场景中,往往会有多个声源,比如客厅里的电视、空调、聊天的家人、吵闹的小朋友,还有声音在墙壁和玻璃发生反射的回波,如果希望在这样典型的使用环境中,正常使用语音唤醒和指令识别,就需要借助麦克风阵列进行声源定位,也就是DoA估计(Direction of Arrival Estimate),而后对从麦克风阵列得到的多通道音频,进行特定方向的波束成形,以尽量只对说话人方向的声音进行拾音,而抑制其他方向声音的干扰。
这里的麦克风阵列的设计和构成对声源的分离至关重要,MATLAB的相控阵工具箱可以对麦克风阵列进行设计与仿真,比如下图,你可以方便的设计和仿真,这些常见的线阵、面阵,甚至于共形阵的麦克风阵列排布,也可以尝试采用不同的麦克风阵元带来的影响。

那么设计好麦克风阵列的基本设计后,我们还要涉及与之相对应的声源定位和波束成形算法,并进行硬件在环的验证……是不是有点麻烦?
MATLAB提供了一系列DoA估计和波束成形的算法模块,如下视频所示您可以快速在MATLAB内,设计和尝试不同的DoA估计和波束成形的算法。视频中演示了有三路声源,男声、女声以及一群人大笑,混在一起难舍难分。而后演示了,可以方便的通过波束成形,提取出需要的目标声源。
还可以直接实时连接麦克风阵列硬件,方便的在MATLAB内,直接进行声源定位和波束成形算法调试与硬件原型测试。
2. 采用深度学习的方式进行语音提取
以上介绍的方法是,采用传统的波束成形的方式,利用麦克风阵列的空间方向选择性,只选择性的接受特定方向上的语音指令。然而在实际应用场景中,经常有多个说话人相距很近的情况,而麦克风阵列又由于尺寸、成本等多方面原因,只能提供比较有限的空间选择性(为获得高的方向选择性,就要尽量降低麦克风阵列的主瓣宽度,而这通常需要更多阵元,更大更复杂的麦克风阵列)。
于是,就有人想到了深度学习。那有没有可能借助深度学习让算法自主从声音中提取出想要的那路语音信号呢?因为,我们自身都有过这样的经历,就是即使在很嘈杂的环境中,人是可以轻松做到,只听一个人交谈的声音的,而人类的双耳,根本无法执行波束成形对吧?
这里,为大家介绍一种基于掩模(mask)的深度学习声源提取方式【1】。
这里使用的方法,其实就是将每一路的声音信号转化为对应的声谱图(spectrogram),而后基于深度学习对每一路声音去估计出其对应的掩模(mask),这个掩模其实就是某个人语音的特定音色属性,而后用这个掩模从混合以后的信号中提取出对用的目标音频信号。篇幅关系就不展开了,详细方法,大家可以去看对应的参考论文。
那么在实际应用中的多声源竞争问题,其实还会更难解决,尤其是远场拾音,目标音频位于远场,声音很容易被近处的说话人遮蔽,而这是恰是一个行业内公认的难点,令人兴奋的是,一家位于波士顿的音频初创公司Yobe,
基于MATLAB所提供的平台以及快速原型验证的方式,对这个问题给出了很不错的解决方法。请看下面的视频,前半段视频中,是麦克风接收到的远近两路声音来源,声音很大的来自近处的干扰源,而声音很小的,才是位于远处的目标声源。后半段视频,则演示的是经过深度学习的音频特征提取,从接收到的音频中提取出,远处那个目标声源的效果,明显把之前被近处干扰掩盖的声音,提取得非常清晰完整。
这里Yobe综合采用了三种方法

Yobe对于MATLAB有下面这样的评价:
“在我们将其商业化之前,MATLAB就为我们刚起步的概念,提供了绝佳的演示环境。 MATLAB使我们能够在研发的每个阶段进行演示,从而帮助我们分享我们的进步,并为正在创造的东西增添激情。 这对于我们持续获得风险投资至关重要。”
对于拓展智能语音应用,很重要的一方面就是声源竞争的问题,多个方向、多种来源、高噪声环境下的场景,如何提取目标信号,是进行可靠语音识别的前提。
三、 语音关键词识别
深度学习的语音识别,目前以家用智能音箱、语音导航等首当其冲。语音操控,本来就是人与人沟通最便捷的方式,只是过去技术水平限制,被迫用按键、遥控器、触摸屏,而今语音操控已自然而然成了新一代的人机接口。所有空调、电视、净化器这所有家电,甚至各处的灯光,都可以方便的采用语音指令进行控制,是不是很美好?

很多小伙伴,可能一提到语音识别,第一反应就是深度学习。确实会用到深度学习不假,然而,想设计好实际工程化实现的语音识别模型,需要考虑的远不只是深度学习本身。工程化实现与在科研探索,最大的区别在于,科研只是单点突破即可,比如可以是仅仅优化某个损失函数改进某个层的算法,就可以发表论文,算作成果了。
而工程化实现,其实是一个完整的链条,任何一个环节出问题,都无法得到满足工程化实现要求的产品。
如下图所示,实际的工程化实现,需要完成如下所示的从左到右四个阶段,首先要采集数据,不仅需要获得足够大的高质量样本集,并且如果是有监督的学习,那你的标注也需要足够的精确;接下来就是预处理和特诊提取,这个步骤对获得轻量化的模型,适合进行嵌入式低功耗、小型化设备进行产品工程化实现至关重要;接下来是模型训练和开发;最后还需要在嵌入式设备或者云端上,产品化实现我们的算法。
而之前我们开发人员的大多数精力,是不是基本都只关注在第三个阶段呢?我们模型的整体性能其实是由这个链条里四个阶段,整体决定的,而非单一环节。
这也就解释了,为什么很多时候,若模型精度欠佳,如果希望只在第三个阶段努力,即仅通过模型优化和超参调解,通常很难得到有效改善的。反而可能使模型变得复杂,得到一个臃肿不适合产品化的模型。

深度学习开发基本流程
首先在音频采集阶段,就需要考虑到回声消除、去混叠、降噪等一系列的预处理算法,而且在准备数据时,还需要根据自己的实际需要和训练平台的情况,来选择合适算法对音频数据进行预处理,这里可能涉及采样率变换、感兴趣频带的提取,也可能涉及感兴趣特征的提取。
接下来,我们以语音指令识别为例【2】,介绍如何在MATLAB中,快速完成产品化的整个链条。
我们的目标是将识别以下的十个英文指令,将采用Google随如下论文一同刚发表的语音指令数据集。

首先,我们导入数据集,数据集通常会比较庞大,若同时加载很可能占用大量内存使运算卡顿。MATLAB提供了一系列的datastore,对数据集进行管理和操作,datastore仅记录数据集的索引和标签,而只在需要时,才会去加载对应的样本。如下所示,采用音频专用的audioDatastore,自动把样本文件夹下的各个子文件夹中数据建立索引数据集,而后自动以每个子文件夹名字作为其中各样本的标签。

这里,其实Google 提供了一个显然由高手,精心加工的高水准的音频指令数据集。而你的实际工程中,通常采集到的原始数据还需要进行一系列的预处理,如前面提到的去回声、去混叠、降噪等一系列操作,通常还会有滤波、采样率变换,然后才会得到这样一个理想的数据集。这个部分恰恰是很多大牛都会重视去做,却很少谈及的。
敲黑板~划重点~高质量的数据集,才能产生高质量的模型。
Notes: 大多数实际的工程应用,都需要自己动手准备这个至关重要的数据集,音频样本的采集的质量与标签的质量,同样重要。这个过程是非常耗时费力的,往往需要人工一段一段的音频反复听,反复手工标注。MATLAB提供了对应于音频和信号领域的快捷标注工具,Audio Labeler 和Signal Labeler。请看以下操作视频,可以看到您可以自动标注,快捷准确的完成这个过程。
以上我们介绍了,导入了整个数据集和标注。接下来,我们把数据集分成训练集、验证集和测试集。

接下来我们讲选择用哪种网络进行指令识别,如图所示,是常见的两种对时间序列进行分类或者检测的网络,上面一种是借助卷积神经网络对二维图像的检测能力,所不同的是需要先将音频序列转换成时频图。

下面这种,采用的是LSTM长短周期记忆网络,虽然也可以直接把时间序列作为其输入,但通常效果欠佳。所以我们一般会在每一个时间拍,提取一个特征向量,把它作为LSTM网络的输入。
这里我们采用上面这种方法,即首先对信号进行时频变换,得到每个时间拍上的时频图作为特征,输入进后面的卷积神经网络。音频中有许多可用的特征,这里过去我们需要自己手写函数,选择提取哪些特征,这个过程经常需要反复尝试。目标是用尽量少的特征,来达到可以接受的模型精度。恰到好处的特征选择,可以使后序的神经网络模型搭建和调优,得以大大简化,轻量级网络即可达到惊艳的效果,并不是每个做得漂亮的项目,都需要在在模型训练阶段,死磕超参优化的。
Notes: 特征的选择,需要针对您的特定使用环境,巧妙选择,比如识别人类语音,则需要了解人耳对于语音的选择性,比如在几百赫兹以下,成线性分布,这部分其实是语音的主要传递信号的部分。从几百赫兹到20K,成对数分布,而对其他频点的声音。而如果您要识别的是乐音,那么您最好花点时间了解十二平均律,以及对应的有效特征,如恒Q变换等。

这里MATLAB提供了一个专用的音频特征提取工具,即audioFeatureExtractor。他把音频常见的特征都统一集成在一个模块,你只要按需求,选择即可使用。

特征提取时,因为需要提取特征的样本量很大,以滑动窗口逐帧计算特征,通常计算很耗时,这里我们采用了如下所示的并行计算方式进行加速。MATLAB代码,仅需要使用关键词稍作修改,即可轻松扩展到多节点,并行执行,使我们的算法执行速度大幅提高。如果您想利用GPU加速,却不想手写CUDA代码怎么办?Parallel Computing Toolbox也可以支持无缝的使用底层的GPU加速。您也可以方便的使用gpuArray对数组声明,底层就会自动使用您的GPU进行加速。

上面代码中,numPar即本机可访问的并行节点数,若numPar=16,则特征提取的计算将被自动在底层分配到这16个节点上并行完成,大幅提高计算速度。你的代码只需把for循环,换成parfor循环。不必再硬着头皮去学习并行编程语言了,所有底层的map-reduce、Hadoop之类的繁文缛节,MATLAB都会为你自动搞定。
接下来我们看一下,提取到的特征。
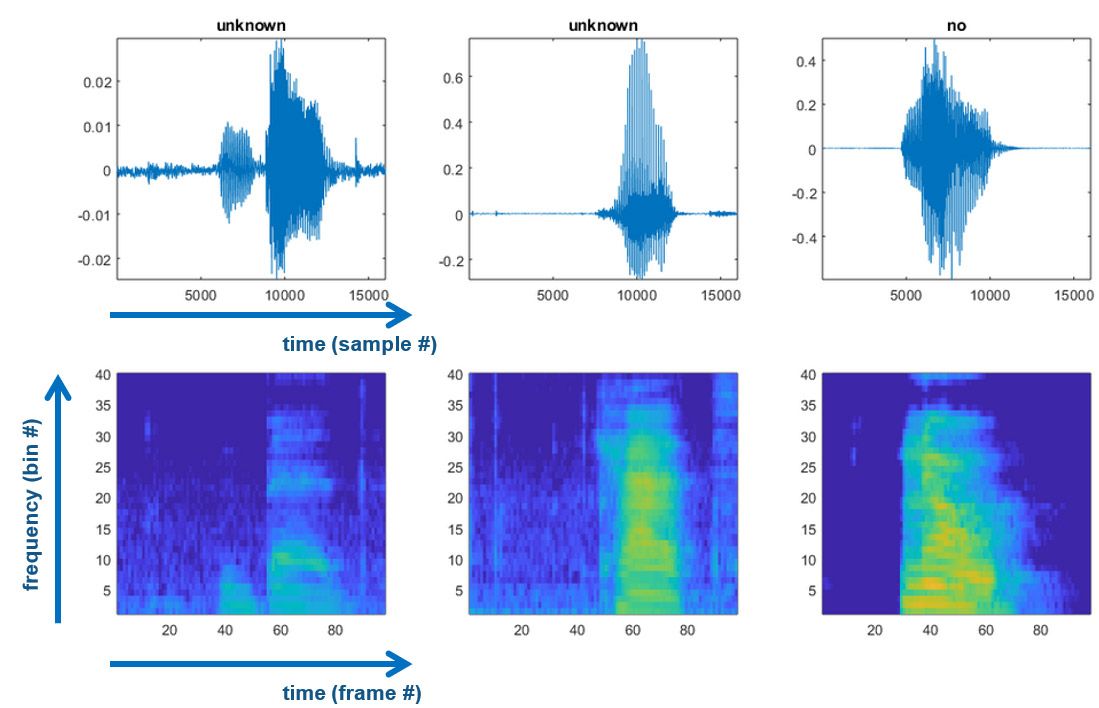
上图中上面一行是原音频波形,16000个采样点,而下图中是其对应的时频图,可以看到横轴和纵轴的点数明显减少了,也就是特征提取起到了明显压缩数据量的作用。恰到好处的选择特征,不仅会大大提高识别精度,而且可以使后面的卷积神经网络只需要一个轻量级的模型,即可达到很理想的精度。这对于产品化实现至关重要。
准备好了训练用的时频图数据集,我们就可以着手搭建神经网络了,我们不必记住指令敲代码,而是可以直接使用如下的Deep Network Designer以拖拽模块和连接的方式,快速完成。

接下来,设置好训练参数后,我们开始对模型进行训练。只要指定训练环境,他会自动在底层使用你所指定的多核CPU或者GPU进行加速。

训练完成后,我们可以对训练结果,进行评估。得到如下的混淆矩阵。

那么我们还可以在MATLAB中,直接访问底层的麦克风,采集实时音频流,来测试我们的模型识别精度,请看下面的视频。
上边,我们实现的其实还只是一个算法原型,那么我们如果想在嵌入式硬件上,实际做一下硬件原型测试怎么办?难道还需要把所有算法都手工用底层代码敲出来吗?显然不必如此,您可以用MATLAB Coder很方便的把这一整套算法(包含预处理、特征提取和深度学习模型),一起打包生成嵌入式处理器如ARM,可运行的高性能C++代码。在这个阶段,仍然保持快速的硬件原型测试和调试迭代的优势。这个语音指令识别的案例,其对应的嵌入式硬件实现的demo,我们也一并在Shipping Demo中提供了,感兴趣的童鞋可以找来试试看【3】。
简单总结一下:
我们介绍了基于深度学习的语音识别在实际工程化实现时,需要完成如下所示的从左到右四个阶段。而之前我们中大多数注意力,往往只关注第三个阶段呢,然而实际上,我们模型的性能其实是由这个链条里四个阶段,整体决定的,而非单一环节。

而MATLAB是面向工程化实现的平台,完整覆盖全部这四个阶段的内容。
首先要采集数据,不仅需要获得足够大的高质量样本集,并且也需要高质量的标签,这部分MATLAB提供了一系列能够快速自动完成标注APP;接下来就是预处理和特诊提取,MATLAB提供大量方便易用的信号处理和预处理的APP,以及音频信号特征提取器,可以方便的尝试需要的预处理和特征提取;接下来是模型训练和开发;最后还支持嵌入式设备或者云端上,自动生成代码或者部署实现我们的算法。
参考文献
[1] "Probabilistic Binary-Mask Cocktail-Party Source Separation in a Convolutional Deep Neural Network,” Andrew J.R. Simpson, 2015.
[2] Speech Command Recognition Using Deep Learning
[3] Speech Command Recognition Code Generation on Raspberry Pi
2022 年发布