VDA SIL Standard: Change in SW and System Development in the Automotive Industry
Amir Sardari, Bosch
Learn about the new VDA software-in-the-loop standard for the continuous and agile development and testing of virtual ECUs and how MathWorks adapts to that.
Published: 7 Aug 2023
Thank you very much, Luigi. And thank you for giving me the stage, for having this chance to be a representative of VDA working group, consisting of-- coworking of 17-- over 17 companies. And MathWorks is also contributing to it very seriously.
So today, we will talk about-- Gernot and me will give you an insight into the software in the loop. We will keep the topic a little bit simple. Why do we need software in the loop? Why do we need the standards for software in the loop? And what is the VDA Automotive SIL architecture? VDA is standing for Verband Automobilindustrie, in German. And its translation is German Association for Automotive Industry.
So we are talking about the very automotive-specific SIL. And after that, we will give you an overview about the management process of SIL in the context of VDA Automotive. And we will talk about a little bit implementation of what we are already doing, not only specification but also a step toward implementation of our work.
And a couple of proof of concepts will be introduced. And after that, I will give it over to Gernot, who will introduce you a proof of concept based on Simulink and FMI 3. At the end, the key takeaways and time for Q&A.
So why do we need software in the loop? We know that in the automotive industry, the functional complexity is already increasing. And the most of the parts which are getting us big revenue are coming from the software-intensive systems. It's also the same in the automotive industry.
We need to reduce the development cycles. The time to market should be reduced. And we have also to deal with the frequent software updates and releases. So in this case, we need a so-called very fast and high scalable feedback in the verification step. And at the same time, we need a very fast feedback from the validation from field-based validation.
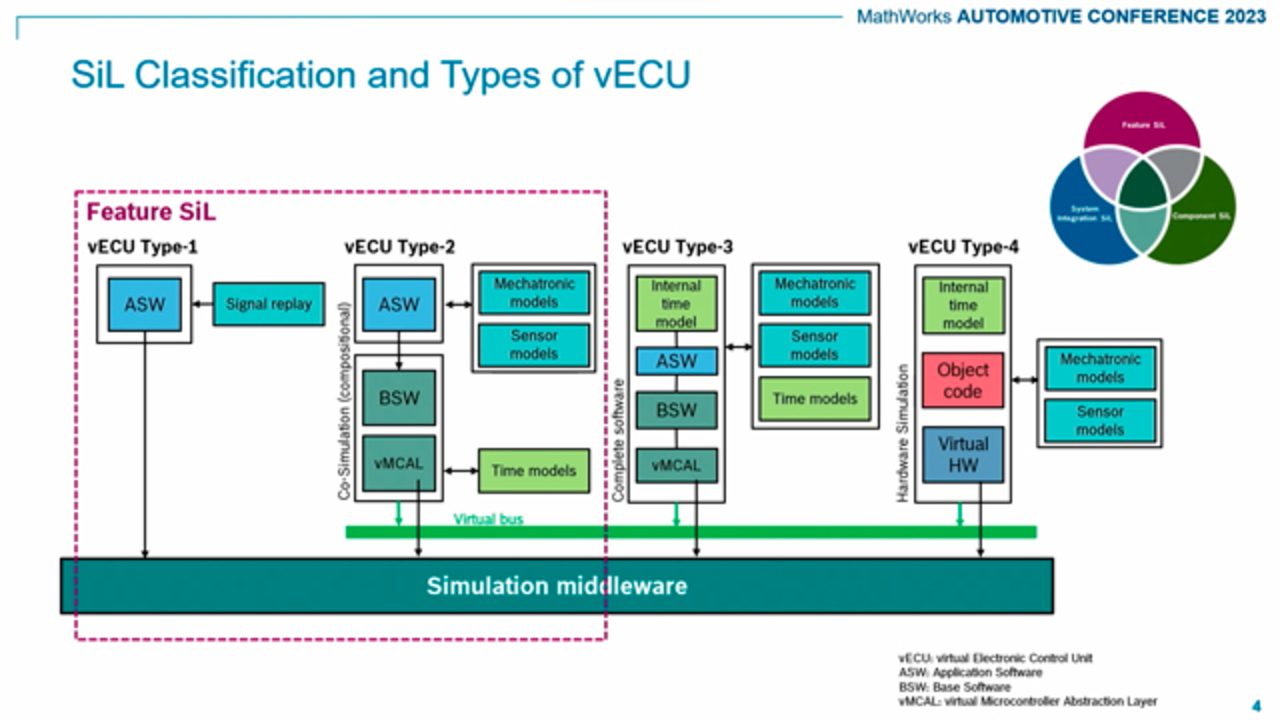
So to bring them both into one cycle, we are dependent on software in the loop. So it means that the software in the loop is a key enabler of the continuous and agile development process. So in order to have an insight into the virtual ECU types, maybe further on, in the next slides, we could understand why are we already going into details.
From the technical point of view, we are dividing the virtual ECUs into four or five types. And when we say, OK, virtual ECUs, we want to test only the controller functionality. We could take a MATLAB model, a Simulink model, and take it as type zero.
And if we want to say, OK, we are talking about a product software, application software, only for some kind of functional testing, we go to the type 1. So we don't have to deal with the low cuts, I would say. We are only dealing with the high cuts, only dealing with this signals and the functionality itself.
And we then, in this context, we could bring one topic, the horizontal virtualization and the vertical virtualization, which is a two-dimensional virtualization. The horizontal virtualization or horizontal test or this test width would be the scope of the test. And the test depth would be the abstraction level of the test-- so abstraction level of the virtual ECUs we need.
So from this point of view, when we say only-- we want to test only one single E/E component, we say component SIL. And if we want to test a composition of virtual ECUs together, we are talking about system SIL.
From the type 2 on, we will have to do with the virtual bus. It means we have a deeper cut in the software. So we need a very high-performance simulation there in this case. So in the VDA working group, still, standardization, we are dealing with mainly with the type 3 virtual ECUs, where we have to do with the virtual bus simulation.
So why do we need standards? So we want to say, OK, when the components which are already having a role in the simulation coming from different domains, it means the functionality is already divided over different nodes. So nodes should be integrated into one platform, one integration platform. This is a X-domain compatibility.
At the same time, the companies are giving us a suppliers of some models. The OEMs are giving us, for example, any kind of plant models or controllers. Everything should be actually standardized. And it should be also platform independent.
So why do we need the standards? So to put everything together, and it should work. So the goals of our project group SIL standardization are. At the end of the day, a kind of recommendation, a publication will be existed. And at the end of the day, in this documentation, this publication, we recommend which standards should be taken for which purposes.
So we don't want to reinvent any existing standards. We just want to enhance or extend them-- so if required. So at the end of the day, the proprietary solutions should be replaced by these standardized solutions.
And here is a flowchart. We will have a proof of concepts. We will take a look into that later on. Based on our proof of concepts, we will identify some gaps in somehow-- in some standards. And then we will address them, try to cover them.
If there is any standard, existing standard, as I said before, we want to address them, identifying the gaps and fill them. So by anyhow specification, more specification, or if there is already something which is already enough, then just only recommendation.
So the project has started 2019. So at the moment, we are in the phase two of the project. And the phase two will be ended end of September this year. So about 17 companies are already contributing. MathWorks is also very important contributor. The Porsche is already in lead of the project.
And we could say we have a bunch of companies, OEMs, suppliers, and tool vendors. The OEMs are supplying us by some kind of use cases. Tool vendors are supporting by integration of our solutions in the tools. And the suppliers, the same way, like OEMs, by use cases.
And MathWorks is already, I said before, dealing in contributing not only as integration platform but also in the context of generation of virtual ECUs, for example, and so on. And we have also ETAs as a subsidiary of Bosch, which is supplying us with the solutions of virtual bus.
So this is a little bit too detailed picture. But we don't want to go into details-- very, very detailed information. Just give you an insight why-- what do we have in the SIL infrastructure?
In the center of the picture, you can see, in the green block, the platform, the integration platform, which is a middleware. In this case, we have a proof of concept based on Simulink. We will see that afterward.
And we have to do with some kind of plant models, physical models, and also, we have to do with the virtual ECUs, I said before. We need virtual buses for the data bus communication. And we have also test automation on the right side.
So everything should be clear, could be clear. Everybody say, OK, FMI standard could cover everything which is needed here in the integration of the models into the complete infrastructure. But it's not the case because the FMI started 2010. And the focus, the initial scope, of this standard was in order to exchange the software models and physical models between the tools.
And it was not so completely concentrated on some kind of virtual ECU virtualization. So with the newest version of FMI, FMI 3, we could say, OK, we have some lessons learned from other topics. And we are able to improve it. We have still some problems regarding the virtualization of the bus.
It means, when we say we want to simulate the type three virtual ECUs, we need to have a deep cut in the software. And we want to simulate the complete frames, for example, the canvas or Ethernet communication. And there, the simulation wouldn't be possible by using FMI.
So in this manner, we need some kind of a side channel. And the button which is connecting the virtual ECUs to each other, and so it will be controlled by FMI connection-- FMI interface to the platform, to the middleware. So I will come to that again.
So before going to that, we could see, on the right side, the ASAM SIL standard, which is standing for-- which is dealing with the connection between the test automation tool and the test-- and the framework and the integration platform. So it's responsible for parameterization, control, and some kind of monitoring aspects, execution of tests, and so on.
Coming back to VDA SiLVI, it's the product of our working group. It is very fast serialization of data based on the FlatBuffer schema, which is already developed and already supported by many tool vendors. And there, we have a very high-performance simulation virtualization of virtual bus, I said before, for type three and-- so virtual buses.
So coming to the SIL management process based on ISO29119-2, this standard is dealing with the test system, testing of software, generally. And based on this standard, we are extending the topic test environment data management process and the dynamic test process. The dynamic test process is a particular testing phase, the execution.
And in that case, it is already this block, which is already in yellow color. We will deal with this. So going into details, we don't want to read everything here. Just keep in mind that from left to right, we are dealing with the requirements which are coming to the test system design. We go through this kind of checklists.
And the detailed information will be published in the recommendation. So everyone who want to set up a SIL infrastructure could go through these points. And everything which is needed to be standardized is already taken over by us.
So going to the implementation phase, as said before, this VDA SiLVI interface, as shown before on the infrastructure, under the architectural picture, we have, at the moment, three or four kind of proof of concepts. The first proof of concept is with the use case adaptive cruise control. And we have a bunch of tool vendors and companies which are already contributing to this proof of concepts.
As you can see, the integration platform is an open-source circuit made by Vector, generally. And also, MathWorks is contributing by delivering some kind of models and also virtual ECUs. And we are having so FMI 3 standard in it. And also, virtual bus is implemented by ETAS COSYM vNET.
As you can see, the blue lines are exactly these high-performance serialization based on FlatBuffer schema, so which could accelerate the simulation very good. And the test automation is also provided by the PROVEtech. Is it PROVEtech, the tool from Akka Akkodis?
We have the same setup also by-- for FMI 2, based on this space [? vBus ?] and also by Simulink. And so going to the next implementation of proof of concept, we have the kind of window lifter. And there, we are having another kind of composition of virtual bus, which is already a part of this SIL kit, open-source packet, package. And it is the SiL Kit NetSim, in this case.
So and now, I would like to give the presentation over to Gernot.
Thank you, Amir. Well, there was, of course, also the motivation for MathWorks because we participated in this project to position Simulink as an integration platform, because these FMU modules for the single components were there. So we had FMUs for the plant models, for the vECUs. And there was also the SiLVI interface that was mentioned just before, that was for the communication between vECUs and the virtual vehicle bus, as mentioned here.
And VDA has decided-- or the partners have decided-- to use FMI 3.0 as a better fitting standard for these kind of problems. And there was a question, well, how can we support FMI 3.0? I think there was one presentation right before from Mani, where he already mentioned that it will come in 23b version. And we have got import/export capabilities.
And how will that look like if Simulink is an integration platform? We use, typically, a different form of presenting that. We have blocks here for the plant model, for the vECUs, also for the virtual vehicle bus. Some of the components, like virtual vehicle bus, typically is coming from a partner. And other components can come from the Simulink environment.
But in general, they can be integrated or will be integrated as FMUs with a 3.0 standard, or, in case of virtual vehicle bus, we also have an option for FMI 2.0. You see, in orange lines here, the physical connection between the blocks which are shown in Simulink as signal lines. We have sensor actuator connections here, also represented in Simulink in the traditional form.
And the SiLVI connection, that blue dotted connection, is a virtual connection not seen directly in Simulink. It's something communicating in the background over a RAM area, where these two components are communicating.
The main message I want to give you is that we are supporting FMI. That you might know. We do that since several years. And we do it for the standard 1.0 and 2.0. And FMI 3.0 will come in 23b. So be prepared, and have a look to that if you need that standard for your use cases.
Let me give you a little bit more information what's included there. If we focus only on FMI 3.0, the question might be, well, what's the difference to 2.0? And the main difference is that support for specific data types that are typically used on the software side or on the algorithmic side.
And these are data types like binary, like all the different integer data types, signed and unsigned. We have single-precision, floating-point data type supported there, which was not directly supported in FMI 2.0 standard. You needed to cast and type cast, which was a little bit complicated.
Another thing is direct support for arrays. And arrays means vectors, matrices, or even higher dimensional matrices, where you can handle parameters, for example, in an easier way. Or it's also used for I/Os. What does it mean handling in an easier way? That you can specify direct metrics, like in MATLAB, and it's taking over, and you don't have to hand over single elements of a matrix, which was really complicated if you had huge matrices for maps, for example.
Another thing is the direct feedthrough support. Direct feedthrough is supported now for cosimulation if the Event Mode is on, on the importing platform. So if the importing platform supports Event Mode, we have no-- we have direct feedthrough and no delay. If the importing platform is not supporting the Event Mode yet, then it will behave like in the FMI 2.0 standard, with an additional delay, because the standard does not allow direct feedthrough in 2.0.
If we compare now FMI 3.0 with 2.0 on some of the most important features, which other features do we support that were already there in 2.0? That's, for example, source code FMU export that not only the DLL is exported as a binary that can be executed but also C source code exported. And that can be used for cross-platform compilations, for example.
Another thing is logging of internal variables. If you want to debug something, that can be helpful. Internal variables are logged and seen as outputs when you import the FMU-- on both sides, FMU 2.0, 3.0.
Other features-- and it's also important we've seen it in the project-- is the unit description or unit definition and the description general of the single parameters, inputs, and outputs, and a specific parameter selection for the export because I think units is clear. If you have an FMU don't know the units, it's quite difficult to work with that. Very often, there might be a misunderstanding that different units have been used for specific physical entities.
Last thing I want to mention here is the support also of variants. You might know variants from the Simulink environment. You can generate also FMU in 3.0 or 2.0 with the variants. You will have a variable to control the variants later on if you have once imported the FMU.
I think that's all from my side. Now we come to the summary. I think we don't have to forward.
OK. We have already said that SIL is the main enabler for our continuous and agile developments because of the DevOps activity, DevOps cycle, and because we need actually very fast feedback from the field-based validation. And there we are also dependent on the very fast verification on the SIL side on the CI side and CD.
So the SIL component needs to be compatible and standardized because we want to be as much as flexible as possible. Regarding also tool selection, the tool selection means at least it should support our standard.
And at the end, the standardization is the basis of scalable cloud-based CX integration platform because-- so there, this is also-- this is already a kind of another level. We have kind of backlog in our current phase of working group. And as soon as we have finished it, we could go to the next phase of the project. It will be possible. It would be possible from the October this year on. Yeah.
Well, the main message from the MathWorks side is we are collaborating here with the VDA in the SIL standardization group. And we have demonstrated-- or we demonstrate a proof of concept for SIL workflow. That's still undergoing. And an important vehicle, therefore, is the support for FMI 3.0. And we support both 2.0, 3.0. Well, I think that's it from our side. If you should have questions, please ask them.
[APPLAUSE]
웹사이트 선택
번역된 콘텐츠를 보고 지역별 이벤트와 혜택을 살펴보려면 웹사이트를 선택하십시오. 현재 계신 지역에 따라 다음 웹사이트를 권장합니다: United States
또한 다음 목록에서 웹사이트를 선택하실 수도 있습니다.
미주
- América Latina (Español)
- Canada (English)
- United States (English)
유럽
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)