Code Generation and Verification Targeting NXP Systems-on-Chip
Daniel Popa, NXP
Learn how to use code generation and verification techniques with MATLAB®, Simulink®, and Stateflow® for targeting NXP systems-on-chip. Using live case studies, explore the capabilities of Embedded Coder®, a product that generates optimized code for mass production devices. Also discover continuous verification capabilities featuring model and test reuse via model-in-the-loop (MIL), software-on-the-loop (SIL), and processor-in-the-loop (PIL) techniques. Together, this Model-Based Design methodology detects specification defects early in design, minimizes the potential for error injection, and accelerates time-to-market for your production application.
Published: 4 Mar 2021
Welcome, everybody. My name is Mauro, application engineer from The MathWorks. And today, I am here with Daniel Popa, model based design toolbox product manager at NXP. Hi, Daniel.
Hi, Mauro. And greetings to everyone out there who's watching this. And thank you for having me here and for giving me the chance to discuss about these topics with you today.
You are welcome, Daniel. On my side, today we will have a deeper look at how to generate code targeting NXP systems on chip. We will see how Simulink models can be reused, optimizing, customizing, and verifying code across all code generation and verification stages.
Daniel, can you explain what you are going to show us today?
Yes, of course. So let's see what we have for today. Let's start very quickly on how we can leverage the model based design principle for prototyping and production with NXP microcontrollers and evaluation boards. First, we start by playing with ideas in a virtual environment, like Model-in-the-Loop. We can create models and perform various simulations in a PC-enabled environment to check for the feasibility of our ideas.
Once we are satisfied with those simulation results, we can move to automatic code generation. These steps allow us to perform functional testing of the system components, define the scenarios, and use values test to stress the design.
The next step is to test the various modules directly on the microcontrollers. Part of our application will be executed on the personal computer, while others will be running on the actual target.
The last stage is to build the final application from the module that you have previously tested and validated. And as you can see, we can use the NXP model based design tool box at any of these stages by leveraging its functionalities for mathematical function simulations, code generation, and of course, microcontrollers, drivers, configurations, and control.
So why do we need a tool box from NXP? Why can't we just use the MATLAB and Simulink directly with the NXP microcontrollers? First of all, we need to highlight that MATLAB and Simulink are not enough to get the application running on the microcontrollers. Besides the MATLAB and Simulink, we also need to get these three toolboxes that transforms the model and scripts into the C code.
The toolbox that is critical to be able to generate the C code for the microcontroller is the embedded coder, in this case. But a part of these three toolboxes, three coders, you might need additional ones from MathWorks in order to improve your productivity. As you can see, there is an entire ecosystem of toolboxes that are linked together and helps you to move quickly from idea to the application C codes.
But all these tool boxes need a final link: the specific target support to be able to use, customize, and deploy algorithm on specific hardware. And this is where the NXP model based design tool box comes into the picture. With all its modules and functionalities, it helps Simulink users to deploy their embedded applications into the NXP microcontrollers. The NXP model based design toolbox contains flux in various MathWorks toolboxes, controls the configuration of the microcontroller peripherals via the standard NXP SDK drivers, enable the cross compilation of the generated code, and it handles the actual deployment to the microcontrollers.
So all in one, this kind of toolbox from NXP can help you to do rapid prototyping. The entire application can be automatically generated from Simulink and downloaded to the actual target.
Now, please let me hand it over to Mauro. He is going to showcase a couple of examples and how you can use the NXP model based design toolbox in conjunction with NXP development kit. You will see a couple of very interesting demos using this kind of hardware. And towards the end, we will have a chance again to discuss the main feature of this tool box. Mauro, take it away.
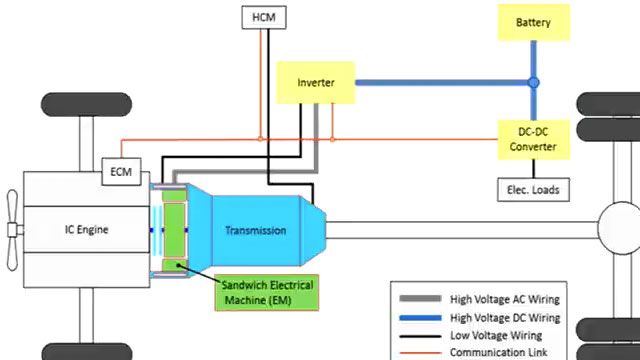
Thank you, Daniel. First of all, I would like to give you an overview on what we will see today. Here we have what we call a Simulink model on the left. And on top is an NXP board. This is an S32K. And here, this is an application that could be done by NXP, or by a customer of NXP working on autonomous driving.
So what is happening here is that we have an architecture with complex software. So here, there are deception algorithms, control algorithms, and vehicle dynamics. And part of these algorithms are actually running on this NXP board. When there is a cutting of a vehicle in front here, you see that this eco vehicle is braking, as is commanded by this NXP board.
And as Daniel mentioned before, with the embedded code you can generate code for this board, and then also using the model based design tool box designed by NXP, you can do a full application deployment and run this type of simulations.
Let me start with model-based design. So model based design is a workflow that you can see here on the left. And it is all around models. So now, when you start with this workflow, you want to start with the research and requirements. To do that, you can use very simple models. For example, here, I have a double integrator that could represent the relation between acceleration and position and speed of a vehicle. And this could be used to get a quantitative feeling of safety requirements, or it could be used to start off with your research.
When you do this in model based design, you get that your specifications become executable. So basically, you have a play button, a Simulink simulation, that you can use, as I said, to understand quantitatively better the consequences of your choices.
This is also a bridge to the next phase of design. Because design can be done based on simulations. And you can, based on your objective, starting the populating the model of your simulations with more details on your design.
So for example, the C code that you've seen before, represented as a double integrator, could be actually populated with an entire architecture. And this architecture can contain engine, battery, electrical machine, drive train. So all the components that can be in a vehicle. And that you may need to represent. And those components are all containing models that have the right level of accuracy that is needed for your design of algorithms.
Once your algorithms are designed at the level that you think it's sufficient for your application, then you can go to implementation. This phase can be done by re-using those models, because we can automatically generate code. In this case here, you have a snippet of C code.
But this really depends on your board. So at this stage, you decide which board you want to target. It could be an MCU or a DSP, or maybe you want to program a GPU.
And then you define your model, targeting that board, and automatically generate the code. So you can see that actually model based design allow us to separate our concerns. And start wondering about the
efficiency and, let's say, the memory occupancy and a number of aspects that are relevant for the code generation only at the time of implementation.
Finally, you may do some integration. And we will see today the different type of integration that you may want to do. And all along these stages, you have continuous test and verification. That means that the artifacts that you produce at each stage can be tested with samples.
Today we will focus on this implementation part. And in particular, we will see the C code generation for the S32K board of NXP that I introduced at the beginning, which has a microcontroller unit on it. And then we will go to integration as a second step. And finally, we will see how we can continuously verify and test the code that is generated in these stages.
Let's start with this very simple model for the new world Simulink users. Simulink can be seen as an integration platform of multiple languages and software. This is just an example where we have three different programming starts. The first one is Simulink blocks, where we use a gain to multiply value of signal, division, and some logical operations.
The second programming style is with MATLAB functions. Here the inputs are simply divided and the value of the result of this division is given in the output.
And finally, we have a set flowchart that is highly graphical language, where we see that here on the left, there is a simple If As statement that is expressed by this graph. The output on the first branch of this flowchart is the division between the two inputs. While on the other branch, we simply give the second input and the output.
To generate code from this simple model, we can open the Embedded Code app. We can hit the big button, and then Simulink will generate code from this model, based on the settings that we have. Here we are using just the default settings, and so embedded code will generate C code for this model.
Once this is done, the Embedded Code will show us the generated code in the code view that is visible here on the right. There is full testability between the model and the code. If we click on a block in the Simulink model, we see that the corresponding part of the generated code is highlighted. So here for example, we see the gain that is in the model. This is true also for the MATLAB functions and for said flowcharts.
Viceversa, if we click on a certain component variable here in the code, we can see it highlighted in the model.
Furthermore, a report has being generated by Embedded Code. And from this report, we can both explore the generated code, the source file, the header files. And also we have an example main file that tell us how to use the generated code. We have information on the subsystems, on the entry points of the code.
And we can also customize this report adding static code metrics. To do that, we can go to the Settings of the code generation. And in the report section, we can check the generate static code metrics. We can also include the model as a web view within the report. By changing the options and generating the code again, we will see that this report has been customized. It contains the web view of the model, and also here in the report, we have testability between the model and the code and vice versa.
What happened in the background is that the model was translated into a text file, this model.rtw from a code generation interpreter. And then, there is a target language compiler. This target language compiler, in the case of the embedded code, is the EFT. And basically, a target language compiler that you can customize to a number of settings to get the desired generated C code.
If there is some legacy code included in your Simulink model, for example some C file that was already there and you want to reuse and is also present in your model, for example, YRS functions or by linking some library, then this will be included in the final executable via a makefile that is associated with the model. And then a Make mechanism will combine all these artifacts into the executable that can run on your board.
Normally, we hear that there are some concerns from our customers about this process. So it's like, is the generated code something that is actually efficient? Is it speedy enough? Or what about the memory occupancy?
If we look into the report, we have a section that is the static code metrics report. This section contains some quantitative information, for example on the memory occupancy. We can see that there are global variables in this model that are input, output, and status of the model, and they are occupying 72 bytes of memory.
So imagine that you have done the modeling, and you see that the behavior in simulation of your model is correct. And now you want to improve the performances. One easy way to do it is to use the Code Generation Advisor. This is a tool that is provided with the Embedded Coder that you can run on the full model of a subcomponent of the model. And we select the full model, and that is called simple_model.
And then when you start this, some checks are being loaded. Those checks are basically corresponding to objectives that we may have. So the Code Generation Advisor has a section with objectives. For example, here we can select that I want to have better RAM efficiency, ROM efficiency, and then I care about execution efficiency in the oDev. So if we care more about the ROM, then we could put it on top.
And when you run checks, then the Code Generation Advisor will scan our model, and will tell us if it is already configured to achieve optimal results in terms of the objectives that we specified. Or we can improve something. For example, here we have a warning. And this warning is affecting our RAM efficiency and ROM efficiency. And here we have a list of links that help us to, let's say, change the configuration of our model to achieve those objectives.
For example, here I have a warning about the default parameter behavior. That is currently tunable, that it recommends to be inlined. In fact, if I click on this link, then the confirmation parameters of the Code Generation Advisor pops up. And you can see that, indeed, this is tunable.
What this means is that basically if we go, for example, to this gain, we see that this gain corresponds in the generated code to a variable. And of course, this is taking some space in our memory.
So if we want to reduce the memory occupancy, we can set this one back to inlined, and then we can build again the code. And then we should see a different type of generated code, and we should see an effect on the memory occupancy.
So here the code is being generated again. We can bring up the report. So we see that, indeed, with the newly generated code that appeared now also in this window, we are occupying not anymore 72, but 48 bytes of memory. And what has happened is that you see that that gain, that before was a variable, is now being hard coded. This is just an example. There are more customizations that you can do.
For example, how often it happens that with some dedicated board, you also get some optimized library to implement operations. For example, in this model, we have a division here. We also have a division within this MATLAB function. And we have a division within this branch of this If As condition implemented as a flow chart.
So what if we could optimize this operation for a certain target? The way to do that is, again, going to the settings. And then the Embedded Code has an interface section. And here you can select a code replacement library. For example, there are some replacement libraries available by default.
But you can also customize and create such a library. If you want to do that, you can go to the Additional Options. And then you can click on Custom code replacement library. When you do that, this window pops up, and then you can create a library. And, for example, you can add a mathematical operation, a function, or another type of operation.
For example, a mathematical operation could be in our case, the division. And there we can customize this division. If you have some C code that you want to append to implement this division, then you can do that in this section.
Let me actually open a customized library that I already prepared for this example. So you can do File, Open. And then if you already created one, you can load it in this environment. And so, here, I have just a divide operation that is called My Division, _MDiv.
So as we do that, we want to select this option from our configuration parameters. So I first need to refresh the configuration parameters. And so I will go in MATLAB and do a refresh of the voice of Simulink. So this means Simulink refresh customizations. And when the refresh is made, we can go back to the model, and again go to the C code tab, go to the settings.
So basically we go back to this interface, and here, now, we see that the custom replacement has appeared. We can apply this and then generate the code again. We see now that the division has been replaced with my custom division. So this is visible in the C file here and is also visible in this window.
So you have seen some ways to optimize our code. And now, after we have generated code that is optimized, we want to basically integrate it in our platform. And for this, we have different options. So the first case is that in the matter of Simulink model, we have only implemented the algorithm. On a system on chip of course, there are other components, for example, the drivers. But also a schedulers or an operating system.
And so the way to integrate is to generate the code and then do basically export of our algorithm by using another tool to interface the code with the peripherals and the operating system.
So this technique is called algorithm export, and of course, it's more flexible because it doesn't matter what is the other code you need to integrate with. You can always take out the generated code for MATLAB Simulink and then do this operation.
The other technique is called full executable. So basically, if in the Simulink model, not only we integrated the algorithms, but also the blocks that allow us to interface with peripherals, and also scheduler of the operating system that we need, then we can do a full executable generation. So we can generate from the MATLAB Simulink model all the code. And as Daniel Popa said at the beginning, this is an operation that can be facilitated by the tools provided with the algorithm. So the model based design toolbox of NXP allow us to actually do this full operation.
The two techniques we see that are used for different purposes. Normally mass production, it is more common to see algorithm export. While full executable allow you to do rapid prototyping and low volume production. And of course, these techniques is easier because it allows you to use the models directly. And so system engineers can already do a full application development, while algorithm export is something that can be done more by software engineers. And it's also nice that full executable works out of the box, while here you need to do some customization because of this integration effort.
So now that we have seen some implementation techniques, and we have achieved, let's say, some code that is optimized, let's see how we can continuously verify and test our algorithms in these stages.
So first of all, let me say that with model based design, you have different stages, from requirements, to a software architecture, to a model that is an executable specification, to a model that is the one that we use for code generation. So basically, with the example that we have seen before, we already focused on this part. So we took a model, we developed it for code generation, adding some library, optimizing for the memory occupancy. And then we got generated code with this press of button that can be integrated on a board.
So we are interested now to see which verifications we can do at these stages. But of course, there are verifications that we can do before. We can even do system requirements verifications by linking those to a software architecture. But let's focus on this.
So on this part, the three verification steps that I want to show are Model-in-the-Loop, that regards the model used for production code generation, Software-in-the-Loop, that regards the generated code, and finally integrated object code verification with Processor-in-the-Loop. So let's see those three.
So Model-in-the-Loop means that basically we take the model and we start inputting some test vectors. We just play simulation with the play button of Simulink. And we get results. Those results already should match our requirements. So this is the first verification step. And it tells us that our model implementation is doing what we want.
The second step will be to generate code by hitting the generate code button. We can customize this code, as we have seen. And then we got an object file that the is suitable to run this code on our PC. So if we use the PC compiler, then we can run the code on our PC. We can input. So we use also the test vectors. And then do a equivalence test between these results and the one that we got from the model.
The only difference, given that this is the same, is that here, we are adding this intermediate step of generating the code. And so if there is some discrepancy here, this is the place where we should look at.
So this is the Software-in-the-Loop. But if we change the compiler and we also change the hardware, then we can do Processor-in-the-Loop. And we can actually use at this stage a board, like an NXP board. And by repeating these tests with the test vectors, we will see if the fact that we are running on a board, and the fact that we are using a compiler for that board, introduces some mistake. And so this is a Processor-in-the-Loop test.
Now I want to show you an example of this Processor-in-the-Loop. Before we start using the model based designed tool box of NXP. and this is a configuration block that allow us to select a certain platform. For example, the S32K, but there are more platforms supported.
And then we can establish a certain connection with the target. For example here, I select Processor-in-the-Loop. There are a few more things to select, like your board is attached to computer, in my case it's COM4. And this is the drive on it.
So this model has some simple logic that is commanding the call of a LED. And I put this caller in output. I also connected to the real board. This is not necessary for Processor-in-the-Loop, but it's something that you can do. Because with the model based design toolbox of NXP, we can do full application deployment. So we can also add here basically the interface to the hardware. In this case a simple LED.
So once this model is set up, we can do a test. So we can associate the test harness to this model. So this is another Simulink model that is linked with this one. Basically, our algorithm is in this reference model, and then here we have test vectors, and we read the results. In this case, in a scope, but also in
some dashboard of Simulink. Simulink has some tools, like dashboard LEDs, or some inputs that you can manipulate here. It changes some constants.
But here we have our test sequence that is the test vector. It represents a right button and a left button that is present on the board. Those are two signals that we can explode. Basically, they can be one or zero, and by selecting them, we can see that they are one and zero at different places. So we have all the combinations, 1 and 0, 0 and 0, 0 and 1, and so on.
The signal is about 35 seconds. So we can set up a Processor-in-the-Loop test. Basically, we can open the app and we can select the SIL/PIL Manager. This is an app that is available with the embedded coder. You can do an automated verification, which means a Simulink will run automatically a Model-in-the-Loop test. Then it will run a Processor-in-the-Loop test with the same test vectors. And then it will compare the results.
So I can select here Processor-in-the-Loop. I could do the same with Software-in-the-Loop. But now I want to do Processor-in-the-Loop. And then, time, I put 35 seconds, consistently with the length of this test vector.
So we can actually run a verification here. And while this is running, the code will be generated for the NXP board. So the test vectors will be communicated to the board. The board will do the processing with the object code that is running on it. And then giving back the results that can be visualized in Simulink.
So we can actually see this in the model when we hit the run button. We have seen that. Then, first of all, Simulink start a simulation, by changing these block status to do Model-in-the-Loop and not Processor-in-the-Loop. That will be the baseline test, so you will see that the colors change based on the input. So blue, red, green, and so on. And then, after this Model-in-the-Loop, it starts the Processor-in-the-Loop.
So now Simulink will use the configuration block of NXP so that this reference model is put back to Processor-in-the-Loop. And you see that now the code is actually running on the board. You see that in the Simulink model, because the data is given back to Simulink. But for the sake of proving that actually the code is running on the board to you, I also showed the light changing color.
So then with the Simulink Data Inspector, you can check the results. And here you see the comparison between the Processor-in-the-Loop output and the Model-in-the-Loop output. You see that the blue is having two signals that are overlapping. Same for the red. You can see that the difference is zero from the lower window, where the two are compared. And the same is happening also for the green. Again, we are zero difference.
So first of all, we saw that Simulink models can be reduced across all the phases of design. From the requirements, you can write requirements in text, link them to an architecture, then go to a first implementation, and continuously test these with simulations.
The focus of today was on generating the code. So we generated code from the Simulink models, and we also saw a few examples of customization and optimizations that you may want to obtain. And you can do this with the options of the embedded coder.
And finally, we saw that we can continuously test and verify our artifacts. So the model, but also the generated code and even the object code, with Model-in-the-Loop, Software-in-the-Loop, and Processor-in-the-Loop.
We also saw that the model based design toolbox made by the team of Daniel Popa at NXP allow us to do a full application deployment. And so this saves a lot of time to all the users, because less integration
effort is required. So I would like to ask Daniel if he can tell us a little bit more about his plans and his toolbox.
Thank you, Mauro, for these great demos. I hope everyone will enjoy those and learn what they can do with MATLAB, Simulink, and additional tool boxes and hardware from NXP.
So I think you got a clear view of what you can do with Model-in-the-Loop, Software-in-the-Loop, Processor-in-the-Loop. Keep in mind, we also have rapid prototyping, even if it hasn't been advertised yet. You can also develop the entire product directly from MATLAB and Simulink, like the last stage shown here.
And keep in mind, NXP model based design tool box can help you at all these stages to make your product and project faster to the market.
So once again, we go towards this slide. This slide is just a recap of what you have seen using the coders, you can generate that code. This code can then be integrated with existing drivers from NXP S32 SDK drivers. You can use the NXP S32 Design Studio to debug such a code, deploy this code to the target using various interfaces. And in the end, you have everything you need to build the final product and go to market.
So let's see a couple of the major functions that this kind of toolbox is capable of. In case of the S32K product families, we can cover most of the microcontroller peripheral cores and system function, as highlighted here in red. If you can look, it's almost the 95% of the core capabilities are already exposed in the MATLAB and Simulink environment.
In terms of configuration modes, there are plenty of customization available for all the microcontrollers. And even external chips, which are commonly used in conjunction with the S32K microcontroller for specific application. Specific application may involve motor control application, or battery management system, or even this kind of canned application where you have to change the level of voltages between the microcontrollers and the existing network.
The toolbox is also delivered with additional software application utilities, like free master, bootloader, profiler, and so on and so forth, that are used to boost your productivity with NXP solutions.
From the start, I would like to highlight that you don't need to have any prior knowledge of C embedded programming when you are trying to build such applications. It is even better if you don't know too many things about programming in general, since the model based design is all about the architecting a system of logical decision branches in a simple visual workflow.
To create an application, first you need to configure the microcontrollers and the peripherals you want to use in your application. Then, if your embedded application requires, you need to add inputs and outputs into your system. These are the action blocks supported by the NXP model based design tool box, and allows access to read and write to any microcontrollers, I/O pins, and peripherals.
Then, depicted here in the user application subsystem, you need to implement your algorithm. So basically your secret sauce. The idea. And this is the part of the algorithm which will perform the action that you want. In general, this part is hardware independent, and it should be designed for portability across multiple platforms.
For example, if at some point you keep adding functionalities here, and the microcontroller is no longer featured product, you could easily switch to a different one, or even a different vendor by simply changing the outside configuration and action blocks of the hardware.
And if you need additional information about this tool box and this kind of solution, or just try to seek help in resolving issues, please consult our online community or our NXP model based design homepage.
And in the end, I would like to thank you for your attention. And let's move towards the Q&A section now.
Thank you, Daniel. And to you for watching this webinar. If you have questions, you can contact us on the email addresses here on the slide. Or feel free to use the available support at both MathWorks and NXP.

Featured Product