cosineSimilarity
코사인 유사도를 사용한 문서 유사도
구문
설명
similarities = cosineSimilarity(documents)similarities(i,j)의 점수는 documents(i)와 documents(j) 사이의 유사도를 나타냅니다.
similarities = cosineSimilarity(documents,queries)documents의 단어 개수에서 도출된 TF-IDF 행렬을 사용하여 documents와 queries 사이의 유사도를 반환합니다. similarities(i,j)의 점수는 documents(i)와 queries(j) 사이의 유사도를 나타냅니다.
similarities = cosineSimilarity(bag)bag의 단어 개수에서 도출된 TF-IDF 행렬을 사용하여 지정된 bag-of-words 또는 bag-of-n-grams 모델에 의해 인코딩된 문서의 쌍별 유사도를 반환합니다. similarities(i,j)의 점수는 bag에 의해 인코딩된 i번째 문서와 j번째 문서 사이의 유사도를 나타냅니다.
similarities = cosineSimilarity(bag,queries)bag의 단어 개수에서 도출된 TF-IDF 행렬을 사용하여 bag-of-words 또는 bag-of-n-grams 모델 bag에 의해 인코딩된 문서와 queries 사이의 유사도를 반환합니다. similarities(i,j)의 점수는 bag에 의해 인코딩된 i번째 문서와 queries(j) 사이의 유사도를 나타냅니다.
similarities = cosineSimilarity(M)M 의 행 벡터로 인코딩된 데이터에 대한 유사도를 반환합니다. similarities(i,j)의 점수는 M(i,:)과 M(j,:) 사이의 유사도를 나타냅니다.
similarities = cosineSimilarity(M1,M2)M1 및 M2의 인코딩된 문서 사이의 유사도를 반환합니다. similarities(i,j)의 점수는 M1(i,:)과 M2(j,:) 사이의 유사도에 대응합니다.
예제
토큰화된 문서로 구성된 배열을 만듭니다.
textData = [
"the quick brown fox jumped over the lazy dog"
"the fast brown fox jumped over the lazy dog"
"the lazy dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(textData)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
9 tokens: the fast brown fox jumped over the lazy dog
8 tokens: the lazy dog sat there and did nothing
6 tokens: the other animals sat there watching
cosineSimilarity 함수를 사용하여 해당 문서 사이의 유사도를 계산합니다. 출력값은 희소 행렬입니다.
similarities = cosineSimilarity(documents);
문서 간 유사도를 히트맵으로 시각화합니다.
figure heatmap(similarities); xlabel("Document") ylabel("Document") title("Cosine Similarities")
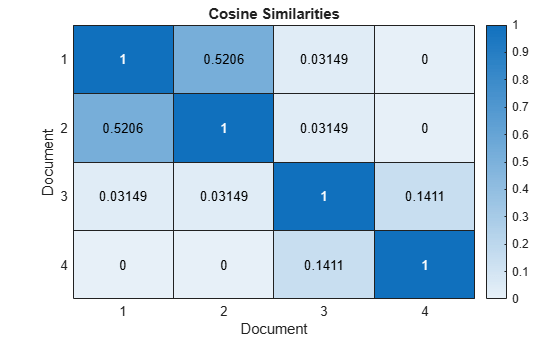
1에 가까운 점수는 강한 유사도를 나타냅니다. 0에 가까운 점수는 약한 유사도를 나타냅니다.
입력 문서로 구성된 배열을 만듭니다.
str = [
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(str)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
8 tokens: the fast fox jumped over the lazy dog
7 tokens: the dog sat there and did nothing
6 tokens: the other animals sat there watching
쿼리 문서로 구성된 배열을 만듭니다.
str = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
queries = tokenizedDocument(str)queries =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
cosineSimilarity 함수를 사용하여 입력 문서와 쿼리 문서 사이의 유사도를 계산합니다. 출력값은 희소 행렬입니다.
similarities = cosineSimilarity(documents,queries);
문서의 유사도를 히트맵으로 시각화합니다.
figure heatmap(similarities); xlabel("Query Document") ylabel("Input Document") title("Cosine Similarities")
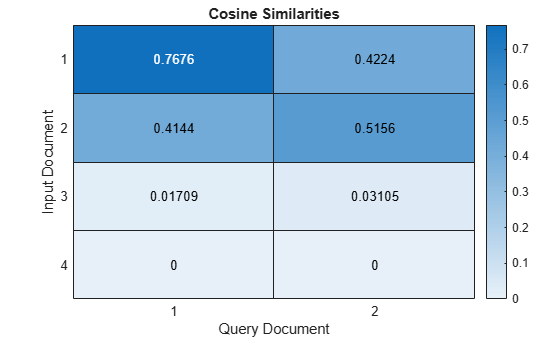
1에 가까운 점수는 강한 유사도를 나타냅니다. 0에 가까운 점수는 약한 유사도를 나타냅니다.
sonnets.csv의 텍스트 데이터에서 bag-of-words 모델을 만듭니다.
filename = "sonnets.csv"; tbl = readtable(filename,'TextType','string'); textData = tbl.Sonnet; documents = tokenizedDocument(textData); bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3527
Counts: [154×3527 double]
Vocabulary: ["From" "fairest" "creatures" "we" "desire" "increase" "," "That" "thereby" "beauty's" "rose" "might" "never" "die" "But" "as" "the" "riper" "should" "by" … ] (1×3527 string)
NumDocuments: 154
cosineSimilarity 함수를 사용하여 소네트 사이의 유사도를 계산합니다. 출력값은 희소 행렬입니다.
similarities = cosineSimilarity(bag);
처음 5개 문서의 유사도를 히트맵으로 시각화합니다.
figure heatmap(similarities(1:5,1:5)); xlabel("Document") ylabel("Document") title("Cosine Similarities")
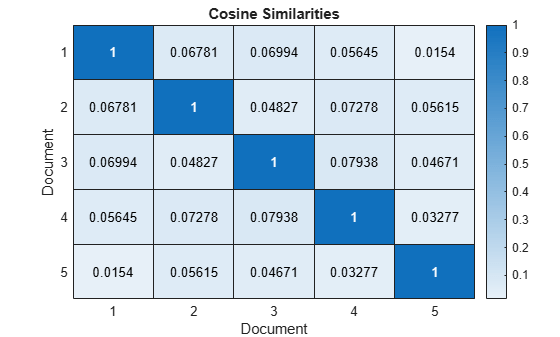
1에 가까운 점수는 강한 유사도를 나타냅니다. 0에 가까운 점수는 약한 유사도를 나타냅니다.
bag-of-words 입력의 경우 cosineSimilarity 함수는 모델에서 도출된 TF-IDF 행렬을 사용하여 코사인 유사도를 계산합니다. 단어 개수 벡터에서 직접 코사인 유사도를 계산하려면 단어 개수를 cosineSimilarity 함수에 행렬로 입력합니다.
sonnets.csv의 텍스트 데이터에서 bag-of-words 모델을 만듭니다.
filename = "sonnets.csv"; tbl = readtable(filename,'TextType','string'); textData = tbl.Sonnet; documents = tokenizedDocument(textData); bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3527
Counts: [154×3527 double]
Vocabulary: ["From" "fairest" "creatures" "we" "desire" "increase" "," "That" "thereby" "beauty's" "rose" "might" "never" "die" "But" "as" "the" "riper" "should" "by" … ] (1×3527 string)
NumDocuments: 154
모델에서 단어 개수 행렬을 가져옵니다.
M = bag.Counts;
cosineSimilarity 함수를 사용하여 단어 개수 행렬의 코사인 문서 유사도를 계산합니다. 출력값은 희소 행렬입니다.
similarities = cosineSimilarity(M);
처음 5개 문서의 유사도를 히트맵으로 시각화합니다.
figure heatmap(similarities(1:5,1:5)); xlabel("Document") ylabel("Document") title("Cosine Similarities")
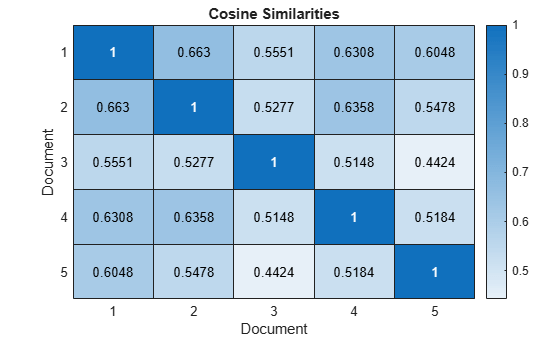
1에 가까운 점수는 강한 유사도를 나타냅니다. 0에 가까운 점수는 약한 유사도를 나타냅니다.