이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
랜덤 포레스트의 예측 변수 선택하기
이 예제에서는 회귀 트리의 랜덤 포레스트를 성장(학습)시킬 때, 데이터 세트에 적합한 분할 예측 변수 선택 기법을 고르는 방법을 보여줍니다. 또한 훈련 데이터에 포함할 가장 중요한 예측 변수를 결정하는 방법도 보여줍니다.
데이터를 불러오고 전처리하기
carbig 데이터 세트를 불러옵니다. 실린더 개수, 엔진 배기량, 마력, 중량, 가속, 연식, 원산지를 고려하여 차량의 연비를 예측하는 모델을 가정해 보겠습니다. Cylinders, Model_Year, Origin은 범주형 변수라고 가정하겠습니다.
load carbig
Cylinders = categorical(Cylinders);
Model_Year = categorical(Model_Year);
Origin = categorical(cellstr(Origin));
X = table(Cylinders,Displacement,Horsepower,Weight,Acceleration,Model_Year,Origin);예측 변수의 수준 결정하기
표준 CART 알고리즘은 수준(고유 값)이 많은 예측 변수(예: 연속 변수)를 수준이 적은 예측 변수(예: 범주형 변수)보다 더 자주 분할하려는 경향이 있습니다. 데이터가 이종(이질적)이거나 예측 변수의 수준 개수가 크게 다를 경우 표준 CART 대신 곡률 또는 상호 작용 검정을 사용하여 분할 예측 변수를 선택하는 것을 고려해 보십시오.
각 예측 변수에 대해 데이터의 수준 개수를 확인합니다. 이를 수행하는 한 가지 방법은 다음과 같은 익명 함수를 정의하는 것입니다.
categorical을 사용하여 모든 변수를 categorical형 데이터형으로 변환하는 익명 함수categories를 사용하여 누락값을 무시하면서 모든 고유한 범주를 확인하는 익명 함수numel을 사용하여 범주 개수를 세는 익명 함수
그런 다음, varfun을 사용하여 각 변수에 함수를 적용합니다.
countLevels = @(x)numel(categories(categorical(x))); numLevels = varfun(countLevels,X,'OutputFormat','uniform');
예측 변수 간 수준 개수를 비교합니다.
figure bar(numLevels) title('Number of Levels Among Predictors') xlabel('Predictor variable') ylabel('Number of levels') h = gca; h.XTickLabel = X.Properties.VariableNames(1:end-1); h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';
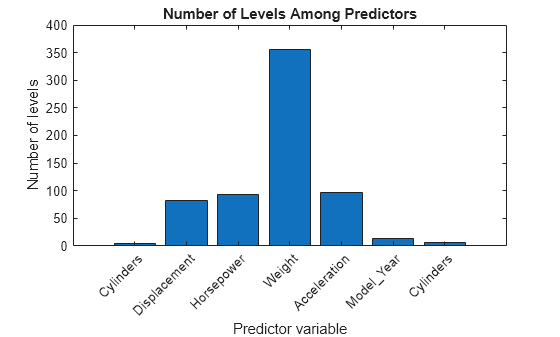
연속 변수는 categorical형 변수보다 수준 개수가 훨씬 더 많습니다. 예측 변수 간 수준 개수가 매우 다양하기 때문에 랜덤 포레스트의 각 트리 노드에서 표준 CART를 사용하여 분할 예측 변수를 선택하면 예측 변수의 중요도 추정값이 부정확해질 수 있습니다. 이런 경우에는 곡률 검정 또는 상호 작용 검정을 사용하십시오. 'PredictorSelection' 이름-값 쌍 인수를 사용하여 알고리즘을 지정합니다. 자세한 내용은 Choose Split Predictor Selection Technique 항목을 참조하십시오.
회귀 트리들로 구성된 배깅 앙상블 훈련시키기
200개의 회귀 트리들로 구성된 배깅 앙상블을 훈련시켜 예측 변수의 중요도 값을 추정합니다. 다음 이름-값 쌍 인수를 사용하여 트리 학습기를 정의합니다.
'NumVariablesToSample','all'— 각 노드에서 모든 예측 변수를 사용하여 각 트리가 모든 예측 변수를 사용하도록 합니다.'PredictorSelection','interaction-curvature'— 상호 검정을 사용하도록 지정하여 분할 예측 변수를 선택합니다.'Surrogate','on'— 데이터 세트에 누락값이 있으므로 대리 분할을 사용하도록 지정하여 정확도를 높입니다.
t = templateTree('NumVariablesToSample','all',... 'PredictorSelection','interaction-curvature','Surrogate','on'); rng(1); % For reproducibility Mdl = fitrensemble(X,MPG,'Method','Bag','NumLearningCycles',200, ... 'Learners',t);
Mdl은 RegressionBaggedEnsemble 모델입니다.
Out-of-bag 예측을 사용하여 모델 를 추정합니다.
yHat = oobPredict(Mdl); R2 = corr(Mdl.Y,yHat)^2
R2 = 0.8744
Mdl은 평균 주변 변동성의 87%를 설명합니다.
예측 변수 중요도 추정
트리에서 Out-of-bag 관측값을 치환하여 예측 변수 중요도 값을 추정합니다.
impOOB = oobPermutedPredictorImportance(Mdl);
impOOB는 Mdl.PredictorNames의 예측 변수에 대응하는 예측 변수 중요도 추정값들을 나타내는 1×7 벡터입니다. 추정값이 수준의 개수가 많은 예측 변수에 편향되지 않습니다.
예측 변수 중요도의 추정값을 비교합니다.
figure bar(impOOB) title('Unbiased Predictor Importance Estimates') xlabel('Predictor variable') ylabel('Importance') h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';
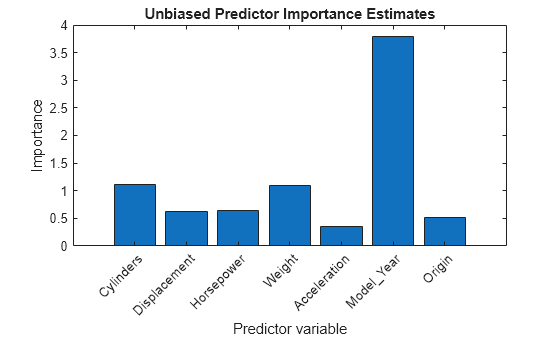
중요도 추정값이 클수록 더 중요한 예측 변수입니다. 막대 그래프에 따르면 Model_Year가 가장 중요한 예측 변수이고, 그 다음으로 Cylinders와 Weight가 중요합니다. Model_Year와 Cylinders 변수에는 각각 13개와 5개의 고유한 수준만 있는 반면, Weight 변수에는 300개가 넘는 수준이 있습니다.
각 예측 변수의 분할로 인해 발생한 평균제곱오차의 증가분을 합산하여 얻은 예측 변수 중요도 추정값과 Out-of-bag 관측값을 치환하여 얻은 예측 변수 중요도 추정값을 비교합니다. 또한, 대리 분할을 통해 추정된 예측 변수 연관성 측도를 구합니다.
[impGain,predAssociation] = predictorImportance(Mdl); figure plot(1:numel(Mdl.PredictorNames),[impOOB' impGain']) title('Predictor Importance Estimation Comparison') xlabel('Predictor variable') ylabel('Importance') h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none'; legend('OOB permuted','MSE improvement') grid on
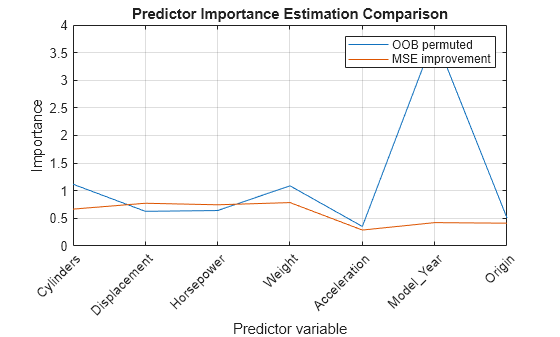
impGain의 값에 따르면 변수 Displacement, Horsepower, Weight는 중요도가 동일합니다.
predAssociation은 예측 변수 연관성 측도로 구성된 7×7 행렬입니다. 행과 열은 Mdl.PredictorNames의 예측 변수에 대응합니다. Predictive Measure of Association는 관측값을 분할하는 결정 규칙 간 유사성을 나타내는 값입니다. 최상의 대리 결정 분할은 최대의 예측 연관성 측도를 제공합니다. predAssociation의 요소를 사용하면 예측 변수 쌍 간의 관계 강도를 추론할 수 있습니다. 값이 클수록 예측 변수 쌍의 상관관계가 높습니다.
figure imagesc(predAssociation) title('Predictor Association Estimates') colorbar h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none'; h.YTickLabel = Mdl.PredictorNames;
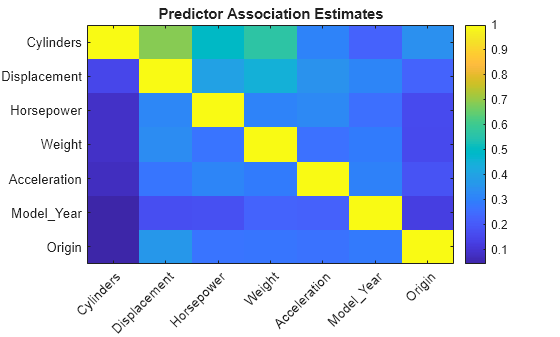
predAssociation(1,2)
ans = 0.6871
가장 큰 연관성은 Cylinders와 Displacement 간에 있지만, 두 예측 변수가 강력한 관계가 있다는 것을 나타낼 만큼 충분히 높지는 않습니다.
축소된 예측 변수 세트를 사용하여 랜덤 포레스트 성장시키기
랜덤 포레스트에서는 예측 변수 개수가 많을수록 예측 시간이 길어지므로 최대한 적은 수의 예측 변수를 사용하여 모델을 만드는 것이 좋습니다.
최적의 예측 변수를 두 개만 사용하여 200개의 회귀 트리로 구성된 랜덤 포레스트를 성장시킵니다. templateTree의 디폴트 'NumVariablesToSample' 값은 회귀의 경우 예측 변수 개수의 1/3이므로, fitrensemble은 랜덤 포레스트 알고리즘을 사용합니다.
t = templateTree('PredictorSelection','interaction-curvature','Surrogate','on', ... 'Reproducible',true); % For reproducibility of random predictor selections MdlReduced = fitrensemble(X(:,{'Model_Year' 'Weight'}),MPG,'Method','Bag', ... 'NumLearningCycles',200,'Learners',t);
축소 모델의 을 계산합니다.
yHatReduced = oobPredict(MdlReduced); r2Reduced = corr(Mdl.Y,yHatReduced)^2
r2Reduced = 0.8653
축소 모델의 은 전체 모델의 에 가깝습니다. 이 결과는 축소 모델이 예측에 사용하기에 충분함을 시사합니다.
참고 항목
templateTree | fitrensemble | oobPredict | oobPermutedPredictorImportance | predictorImportance | corr