perfcurve
분류기 출력값에 대한 ROC(수신자 조작 특성) 곡선 또는 기타 성능 곡선
구문
설명
[___] = perfcurve(는 하나 이상의 labels,scores,posclass,Name,Value)Name,Value 쌍 인수로 지정된 추가 옵션을 사용하여 ROC 곡선의 좌표와 함께 위에 열거된 구문에 나와 있는 다른 출력 인수를 반환합니다.
예를 들어, 음성 클래스 목록을 제공하거나, X 또는 Y 기준을 변경하거나, 교차 검증 또는 부트스트랩을 사용하여 점별(Pointwise) 신뢰한계를 계산하거나, 오분류 비용을 지정하거나, 신뢰한계를 병렬로 계산할 수 있습니다.
예제
표본 데이터를 불러옵니다.
load fisheriris처음 두 특징만 예측 변수로 사용합니다. 종 versicolor 및 virginica에 대응되는 측정값만 사용하여 이진 분류 문제를 정의합니다.
pred = meas(51:end,1:2);
이진 응답 변수를 정의합니다.
resp = (1:100)'>50; % Versicolor = 0, virginica = 1로지스틱 회귀 모델을 피팅합니다.
mdl = fitglm(pred,resp,'Distribution','binomial','Link','logit');
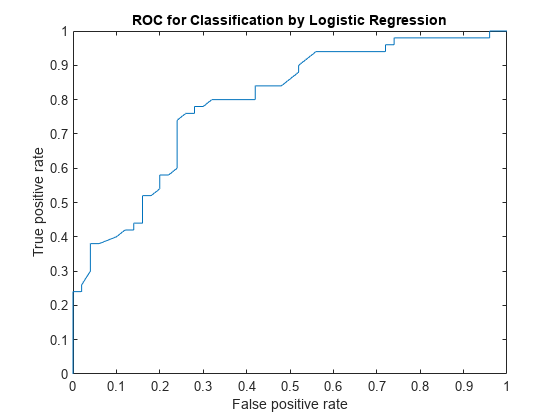
ROC 곡선을 계산합니다. 로지스틱 회귀 모델의 확률 추정값을 점수로 사용합니다.
scores = mdl.Fitted.Probability;
[X,Y,T,AUC] = perfcurve(species(51:end,:),scores,'virginica');perfcurve는 배열 T에 분계점 값을 저장합니다.
곡선 아래 면적을 표시합니다.
AUC
AUC = 0.7918
곡선 아래 면적은 0.7918입니다. 최대 AUC 값은 1이고, 이는 완벽한 분류기에 해당합니다. AUC 값이 클수록 더 나은 분류기 성능을 나타냅니다.
ROC 곡선을 플로팅합니다.
plot(X,Y) xlabel('False positive rate') ylabel('True positive rate') title('ROC for Classification by Logistic Regression')
rocmetrics 객체를 생성하고 plot 객체 함수를 사용하여 ROC 곡선을 계산하고 플로팅할 수 있습니다.
rocObj = rocmetrics(species(51:end,:),scores,'virginica');
plot(rocObj)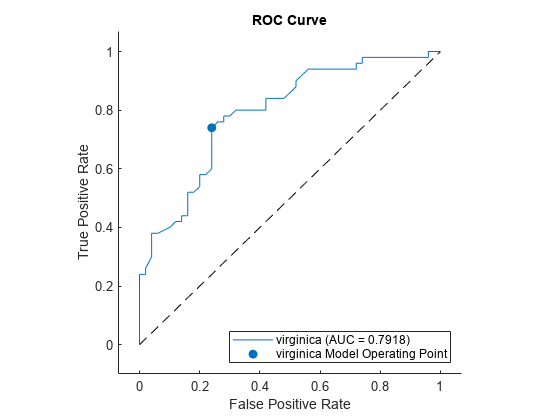
plot 함수가 채워진 원을 모델 동작점에 표시하며 곡선에 대한 클래스 이름 및 AUC 값을 범례에 표시합니다.
표본 데이터를 불러옵니다.
load ionosphereX는 예측 변수로 구성된 351x34 실수 값 행렬입니다. Y는 나쁜 레이다 반환값에 대해서는 'b'를, 좋은 레이다 반환값에 대해서는 'g'를 클래스 레이블로 갖는 문자형 배열입니다.
응답 변수의 형식을 다시 지정하여 로지스틱 회귀를 피팅합니다. 예측 변수 3~예측 변수 34를 사용합니다.
resp = strcmp(Y,'b'); % resp = 1, if Y = 'b', or 0 if Y = 'g' pred = X(:,3:34);
레이다 반환값에 대한 사후 확률을 나쁜 레이다 반환값으로 추정하도록 로지스틱 회귀 모델을 피팅합니다.
mdl = fitglm(pred,resp,'Distribution','binomial','Link','logit'); score_log = mdl.Fitted.Probability; % Probability estimates
점수에 대한 확률을 사용하여 표준 ROC 곡선을 계산합니다.
[Xlog,Ylog,Tlog,AUClog] = perfcurve(resp,score_log,'true');동일한 표본 데이터에 대해 SVM 분류기를 훈련시킵니다. 데이터를 표준화합니다.
mdlSVM = fitcsvm(pred,resp,'Standardize',true);사후 확률(점수)을 계산합니다.
mdlSVM = fitPosterior(mdlSVM); [~,score_svm] = resubPredict(mdlSVM);
score_svm의 두 번째 열은 나쁜 레이다 반환값에 대한 사후 확률을 포함합니다.
SVM 모델에서 얻은 점수를 사용하여 표준 ROC 곡선을 계산합니다.
[Xsvm,Ysvm,Tsvm,AUCsvm] = perfcurve(resp,score_svm(:,mdlSVM.ClassNames),'true');동일한 표본 데이터에 대해 나이브 베이즈 분류기를 피팅합니다.
mdlNB = fitcnb(pred,resp);
사후 확률(점수)을 계산합니다.
[~,score_nb] = resubPredict(mdlNB);
나이브 베이즈 분류에서 얻은 점수를 사용하여 표준 ROC 곡선을 계산합니다.
[Xnb,Ynb,Tnb,AUCnb] = perfcurve(resp,score_nb(:,mdlNB.ClassNames),'true');동일한 그래프에 ROC 곡선을 플로팅합니다.
plot(Xlog,Ylog) hold on plot(Xsvm,Ysvm) plot(Xnb,Ynb) legend('Logistic Regression','Support Vector Machines','Naive Bayes','Location','Best') xlabel('False positive rate'); ylabel('True positive rate'); title('ROC Curves for Logistic Regression, SVM, and Naive Bayes Classification') hold off

SVM은 분계점이 높을수록 더 나은 ROC 값을 생성하지만, 로지스틱 회귀가 일반적으로 좋은 레이다 반환값에서 나쁜 레이다 반환값을 구분하는 데 더 적합합니다. 나이브 베이즈에 대한 ROC 곡선은 전반적으로 다른 두 ROC 곡선보다 낮으며, 이는 다른 두 분류기 방법보다 표본내 성능이 낮다는 것을 나타냅니다.
세 가지 분류기에 대한 곡선 아래 면적을 비교합니다.
AUClog
AUClog = 0.9659
AUCsvm
AUCsvm = 0.9489
AUCnb
AUCnb = 0.9393
로지스틱 회귀가 분류에 대해 가장 높은 AUC 측정값을 가지며, 나이브 베이즈가 가장 낮은 값을 가집니다. 이 결과는 로지스틱 회귀가 이 표본 데이터에 대해 더 나은 표본내 평균 성능을 제공한다는 것을 나타냅니다.
이 예제에서는 ROC 곡선을 사용하여 분류기의 사용자 지정 커널 함수에 대해 더 적합한 모수 값을 결정하는 방법을 보여줍니다.
단위원 내부 임의의 점으로 구성된 집합을 생성합니다.
rng(1); % For reproducibility n = 100; % Number of points per quadrant r1 = sqrt(rand(2*n,1)); % Random radii t1 = [pi/2*rand(n,1); (pi/2*rand(n,1)+pi)]; % Random angles for Q1 and Q3 X1 = [r1.*cos(t1) r1.*sin(t1)]; % Polar-to-Cartesian conversion r2 = sqrt(rand(2*n,1)); t2 = [pi/2*rand(n,1)+pi/2; (pi/2*rand(n,1)-pi/2)]; % Random angles for Q2 and Q4 X2 = [r2.*cos(t2) r2.*sin(t2)];
예측 변수를 정의합니다. 제1사분면과 제3사분면의 점은 양성 클래스에 속하는 것으로 레이블을 지정하고 제2사분면과 제4사분면의 점은 음성 클래스에 속하는 것으로 레이블을 지정합니다.
pred = [X1; X2];
resp = ones(4*n,1);
resp(2*n + 1:end) = -1; % Labels
특징 공간의 두 행렬을 입력값으로 받아 시그모이드 커널을 사용하여 이들 입력값을 그람 행렬(Gram Matrix)로 변환하는 함수 mysigmoid.m을 생성합니다.
function G = mysigmoid(U,V) % Sigmoid kernel function with slope gamma and intercept c gamma = 1; c = -1; G = tanh(gamma*U*V' + c); end
시그모이드 커널 함수를 사용하여 SVM 분류기를 훈련시킵니다. 데이터를 표준화하는 것이 좋습니다.
SVMModel1 = fitcsvm(pred,resp,'KernelFunction','mysigmoid',... 'Standardize',true); SVMModel1 = fitPosterior(SVMModel1); [~,scores1] = resubPredict(SVMModel1);
mysigmoid.m에서 gamma = 0.5를 설정하고 mysigmoid2.m으로 저장합니다. 또한, 조정된 시그모이드 커널을 사용하여 SVM 분류기를 훈련시킵니다.
function G = mysigmoid2(U,V) % Sigmoid kernel function with slope gamma and intercept c gamma = 0.5; c = -1; G = tanh(gamma*U*V' + c); end
SVMModel2 = fitcsvm(pred,resp,'KernelFunction','mysigmoid2',... 'Standardize',true); SVMModel2 = fitPosterior(SVMModel2); [~,scores2] = resubPredict(SVMModel2);
두 모델 모두에 대한 ROC 곡선과 곡선 아래 면적(AUC)을 계산합니다.
[x1,y1,~,auc1] = perfcurve(resp,scores1(:,2),1); [x2,y2,~,auc2] = perfcurve(resp,scores2(:,2),1);
ROC 곡선을 플로팅합니다.
plot(x1,y1) hold on plot(x2,y2) hold off legend('gamma = 1','gamma = 0.5','Location','SE'); xlabel('False positive rate'); ylabel('True positive rate'); title('ROC for classification by SVM');
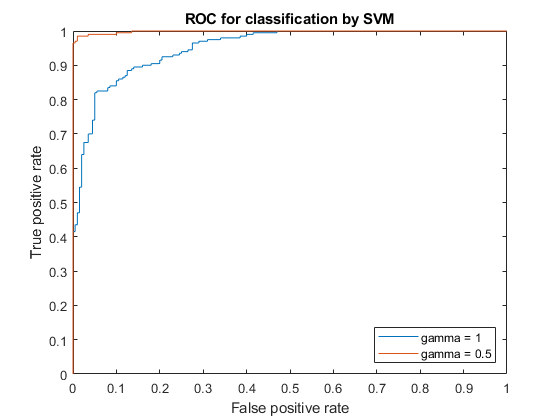
감마 모수가 0.5로 설정된 커널 함수가 더 나은 표본내 결과를 제공합니다.
AUC 측정값을 비교합니다.
auc1 auc2
auc1 =
0.9518
auc2 =
0.9985

감마가 0.5로 설정된 곡선 아래 면적은 감마가 1로 설정된 곡선 아래 면적보다 큽니다. 이는 또한 감마 모수 값이 0.5인 경우 더 나은 결과를 생성함을 확인합니다. 이러한 두 감마 모수 값을 갖는 분류기 성능을 시각적으로 비교한 것을 보려면 사용자 지정 커널을 사용하여 SVM 분류기 훈련시키기 항목을 참조하십시오.
표본 데이터를 불러옵니다.
load fisheriris열 벡터 species는 세 가지 붓꽃 종인 setosa, versicolor, virginica로 구성됩니다. double형 행렬 meas는 꽃에 대한 네 가지 측정값 유형인 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비로 구성됩니다. 모든 측정값은 센티미터 단위입니다.
꽃받침 길이와 너비를 예측 변수로 사용하여 분류 트리를 훈련시킵니다. 클래스 이름을 지정하는 것이 좋습니다.
Model = fitctree(meas(:,1:2),species, ... 'ClassNames',{'setosa','versicolor','virginica'});
트리 Model을 기반으로 하여 종에 대한 클래스 레이블과 점수를 예측합니다.
[~,score] = resubPredict(Model);
점수는 하나의 관측값(데이터 행렬의 한 행)이 하나의 클래스에 속할 사후 확률입니다. score의 열은 'ClassNames'로 지정된 클래스에 대응됩니다. 따라서, 첫 번째 열은 setosa에 대응되고, 두 번째 열은 versicolor에 대응되며, 세 번째 열은 virginica에 대응됩니다.
실제 클래스 레이블 species가 주어진 경우 어떤 관측값이 versicolor에 속한다는 예측에 대한 ROC 곡선을 계산합니다. 또한, 음성 서브클래스에 대한 최적 동작점과 y 값을 계산합니다. 음성 클래스의 이름을 반환합니다.
이는 다중클래스 문제이므로 score(:,2)를 단순히 perfcurve에 대한 입력값으로 제공할 수는 없습니다. 그렇게 하는 경우 perfcurve에 두 음성 클래스(setosa 및 virginica)에 대한 점수와 관련한 충분한 정보가 제공되지 않습니다. 이 문제는 한 클래스의 점수만 파악해도 다른 클래스의 점수를 충분히 판단할 수 있는 이진 분류 문제와는 다릅니다. 따라서, perfcurve에 두 음성 클래스의 점수를 고려하는 함수를 제공해야 합니다. 이러한 함수 중 하나는 이며, 이는 일대다(OVA) 코딩 설계에 대응합니다.
diffscore1 = score(:,2) - max(score(:,1),score(:,3));
diffscore의 값은 이진 문제에 대한 분류 점수로, 두 번째 클래스를 양성 클래스로 처리하고 나머지를 음성 클래스로 처리합니다.
[X,Y,T,~,OPTROCPT,suby,subnames] = perfcurve(species,diffscore1,'versicolor');X는 기본적으로 거짓양성률(부적합률 또는 1-특이도)이고, Y는 기본적으로 참양성률(재현율 또는 민감도)입니다. 양성 클래스 레이블은 versicolor입니다. 음성 클래스가 정의되지 않은 경우 perfcurve는 양성 클래스에 속하지 않는 관측값들이 한 클래스 내에 있다고 가정합니다. 이 함수는 이를 음성 클래스로 받습니다.
OPTROCPT
OPTROCPT = 1×2
0.1000 0.8000
suby
suby = 12×2
0 0
0.1800 0.1800
0.4800 0.4800
0.5800 0.5800
0.6200 0.6200
0.8000 0.8000
0.8800 0.8800
0.9200 0.9200
0.9600 0.9600
0.9800 0.9800
1.0000 1.0000
1.0000 1.0000
subnames
subnames = 1×2 cell
{'setosa'} {'virginica'}
ROC 곡선을 플로팅하고 ROC 곡선에 최적 동작점을 플로팅합니다.
plot(X,Y) hold on plot(OPTROCPT(1),OPTROCPT(2),'ro') xlabel('False positive rate') ylabel('True positive rate') title('ROC Curve for Classification by Classification Trees') hold off

최적 동작점에 대응되는 분계점을 구합니다.
T((X==OPTROCPT(1))&(Y==OPTROCPT(2)))
ans = 0.2857
virginica를 음성 클래스로 지정하고 versicolor에 대한 ROC 곡선을 계산하고 플로팅합니다.
즉, perfcurve에 음성 클래스의 점수를 고려하는 함수를 제공해야 합니다. 사용할 함수를 예로 들면 입니다.
diffscore2 = score(:,2) - score(:,3); [X,Y,~,~,OPTROCPT] = perfcurve(species,diffscore2,'versicolor', ... 'negClass','virginica'); OPTROCPT
OPTROCPT = 1×2
0.1800 0.8200
figure, plot(X,Y) hold on plot(OPTROCPT(1),OPTROCPT(2),'ro') xlabel('False positive rate') ylabel('True positive rate') title('ROC Curve for Classification by Classification Trees') hold off

또는 rocmetrics 객체를 사용하여 ROC 곡선을 생성할 수 있습니다. rocmetrics는 일대다(OVA) 코딩 설계를 사용하여 다중클래스 분류 문제를 지원하며, 해당 설계는 다중클래스 문제를 이진 문제의 집합으로 축소합니다. 각 클래스에 대한 일대다(OVA) ROC 곡선을 플로팅하여 각 클래스에 대한 다중클래스 문제의 성능을 검토할 수 있습니다.
rocmetrics 객체를 생성하여 성능 메트릭을 계산합니다. 실제 레이블, 분류 점수 및 클래스 이름을 지정합니다.
rocObj = rocmetrics(species,score,Model.ClassNames);
rocmetrics의 plot 함수를 사용하여 각 클래스에 대한 ROC 곡선을 플로팅합니다.
figure plot(rocObj)
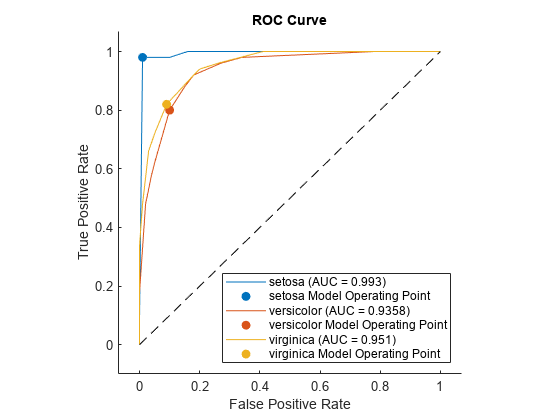
plot 함수가 채워진 원을 각 클래스에 대한 모델 동작점에 표시하며, 각 곡선에 대한 클래스 이름 및 AUC 값을 범례에 표시합니다. rocmetrics 객체 rocObj에 저장된 속성을 사용하여 최적의 동작점을 찾을 수 있습니다. 예제는 Find Model Operating Point and Optimal Operating Point 항목을 참조하십시오.
표본 데이터를 불러옵니다.
load fisheriris열 벡터 species는 세 가지 붓꽃 종인 setosa, versicolor, virginica로 구성됩니다. double형 행렬 meas는 꽃에 대한 네 가지 측정값 유형인 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비로 구성됩니다. 모든 측정값은 센티미터 단위입니다.
처음 두 특징만 예측 변수로 사용합니다. versicolor 종과 virginica 종에 대응되는 측정값만 사용하여 이진 문제를 정의합니다.
pred = meas(51:end,1:2);
이진 응답 변수를 정의합니다.
resp = (1:100)'>50; % Versicolor = 0, virginica = 1로지스틱 회귀 모델을 피팅합니다.
mdl = fitglm(pred,resp,'Distribution','binomial','Link','logit');
세로 평균화(VA)와 부트스트랩을 사용한 표본추출을 사용하여 참양성률(TPR)에 대한 점별 신뢰구간을 계산합니다.
[X,Y,T] = perfcurve(species(51:end,:),mdl.Fitted.Probability,... 'virginica','NBoot',1000,'XVals',[0:0.05:1]);
'NBoot',1000은 부트스트랩 복제 개수를 1000으로 설정합니다. 'XVals','All'은 perfcurve가 모든 점수에 대한 X 값, Y 값, T 값을 반환하도록 요청하고 세로 평균화를 사용하여 모든 X 값(거짓양성률)에서 Y 값(참양성률)의 평균을 구하도록 합니다. XVals를 지정하지 않으면 perfcurve가 기본적으로 분계점 평균화를 사용하여 신뢰한계를 계산합니다.
점별 신뢰구간을 플로팅합니다.
errorbar(X,Y(:,1),Y(:,1)-Y(:,2),Y(:,3)-Y(:,1)); xlim([-0.02,1.02]); ylim([-0.02,1.02]); xlabel('False positive rate') ylabel('True positive rate') title('ROC Curve with Pointwise Confidence Bounds') legend('PCBwVA','Location','Best')

항상 거짓양성률(FPR, 이 예제에서는 X 값임)을 제어할 수 있는 것은 아닙니다. 따라서 분계점 평균화를 통해 참양성률(TPR)에 대한 점별 신뢰구간을 계산해야 할 수 있습니다.
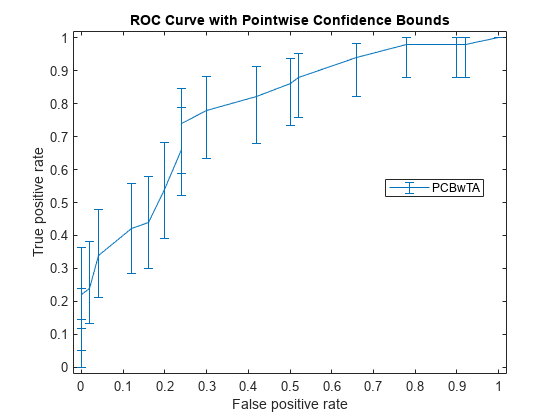
[X1,Y1,T1] = perfcurve(species(51:end,:),mdl.Fitted.Probability,... 'virginica','NBoot',1000);
'TVals'를 'All'로 설정하거나 'TVals' 또는 'Xvals'를 지정하지 않는 경우, perfcurve는 모든 점수에 대해 X 값, Y 값, T 값을 반환하고 분계점 평균화를 사용하여 X와 Y에 대한 점별 신뢰한계를 계산합니다.
신뢰한계를 플로팅합니다.
figure() errorbar(X1(:,1),Y1(:,1),Y1(:,1)-Y1(:,2),Y1(:,3)-Y1(:,1)); xlim([-0.02,1.02]); ylim([-0.02,1.02]); xlabel('False positive rate') ylabel('True positive rate') title('ROC Curve with Pointwise Confidence Bounds') legend('PCBwTA','Location','Best')

고정할 분계점 값을 지정하고 ROC 곡선을 계산합니다. 그런 다음 곡선을 플로팅합니다.
[X1,Y1,T1] = perfcurve(species(51:end,:),mdl.Fitted.Probability,... 'virginica','NBoot',1000,'TVals',0:0.05:1); figure() errorbar(X1(:,1),Y1(:,1),Y1(:,1)-Y1(:,2),Y1(:,3)-Y1(:,1)); xlim([-0.02,1.02]); ylim([-0.02,1.02]); xlabel('False positive rate') ylabel('True positive rate') title('ROC Curve with Pointwise Confidence Bounds') legend('PCBwTA','Location','Best')
입력 인수
이름-값 인수
출력 인수
알고리즘
대체 기능
rocmetrics객체를 생성하여 ROC 곡선과 다른 성능 곡선에 대한 성능 메트릭을 계산할 수 있습니다.rocmetrics는 이진 분류 문제와 다중클래스 분류 문제를 모두 지원합니다. 분류 모델 객체의predict함수(예:ClassificationTree객체의predict함수)가 반환하는 분류 점수는 점수를 다중클래스 모델에 맞게 조정하지 않고rocmetrics객체에 전달할 수 있습니다.rocmetrics는 ROC 곡선을 플로팅하는 객체 함수(plot), 다중클래스 문제에 대한 평균 ROC 곡선을 찾는 객체 함수(average) 및 객체를 생성한 후 추가적인 메트릭을 계산하는 객체 함수(addMetrics)를 제공합니다. 자세한 내용은 도움말 페이지와 ROC Curve and Performance Metrics 항목을 참조하십시오.