classify
판별분석을 사용하여 관측값 분류하기
구문
설명
참고
판별분석 분류기 훈련과 레이블 예측에는 classify보다 fitcdiscr 및 predict를 권장합니다. fitcdiscr은 교차 검증 및 하이퍼파라미터 최적화를 지원하며, 새로운 예측을 하거나 사전 확률을 변경할 때마다 매번 분류기를 피팅할 필요가 없습니다.
class = classify(sample,training,group)sample의 각 데이터 행을 training의 데이터가 속한 그룹 중 하나로 분류합니다. training의 그룹은 group으로 지정됩니다. 이 함수는 class를 반환하며, 여기에는 sample의 각 행에 할당된 그룹이 포함됩니다.
예제
fisheriris 데이터 세트를 불러옵니다. group을 붓꽃 종을 포함하는 문자형 벡터로 구성된 셀형 배열로 생성합니다.
load fisheriris
group = species;meas 행렬은 150개 붓꽃에 대한 2개의 꽃받침 측정값과 2개의 꽃잎 측정값을 포함합니다. group의 그룹 정보를 사용하여 관측값을 층화된 훈련 세트(trainingData) 하나와 표본 세트(sampleData) 하나로 임의로 분할합니다. sampleData를 위해 40% 홀드아웃 표본을 지정합니다.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.40); trainInds = training(cv); sampleInds = test(cv); trainingData = meas(trainInds,:); sampleData = meas(sampleInds,:);
선형 판별분석을 사용하여 sampleData를 분류하고 group의 실제 레이블과 class의 예측 레이블에서 혼동행렬 차트를 만듭니다.
class = classify(sampleData,trainingData,group(trainInds)); cm = confusionchart(group(sampleInds),class);
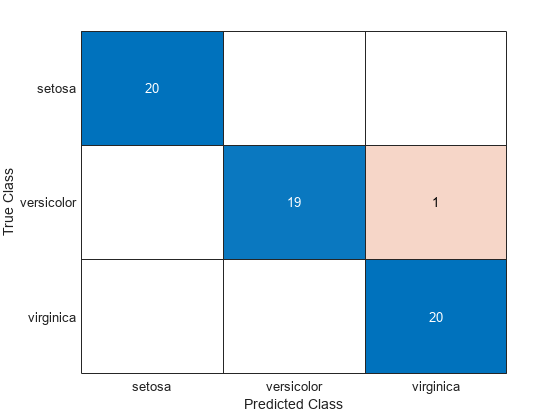
classify 함수는 versicolor 붓꽃 하나를 표본 데이터 세트에서 virginica로 잘못 분류합니다.
2차 판별분석을 사용하여 데이터 점을 측정값 그리드(표본 데이터)에 분류합니다. 그런 다음 표본 데이터, 훈련 데이터, 결정 경계를 시각화합니다.
fisheriris 데이터 세트를 불러옵니다. group을 붓꽃 종을 포함하는 문자형 벡터로 구성된 셀형 배열로 생성합니다.
load fisheriris
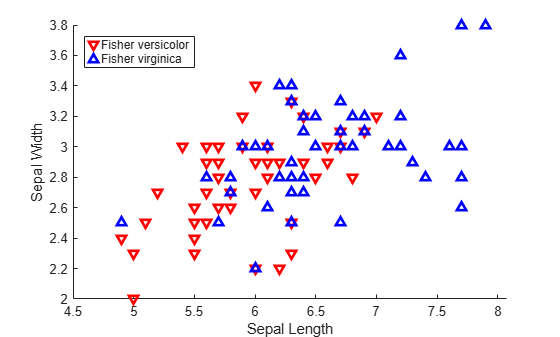
group = species(51:end);붓꽃 versicolor 종과 virginica 종에 대한 꽃받침 길이(SL)와 너비(SW) 측정값을 플로팅합니다.
SL = meas(51:end,1); SW = meas(51:end,2); h1 = gscatter(SL,SW,group,'rb','v^',[],'off'); h1(1).LineWidth = 2; h1(2).LineWidth = 2; legend('Fisher versicolor','Fisher virginica','Location','NW') xlabel('Sepal Length') ylabel('Sepal Width')
sampleData를 측정값 그리드를 포함하는 숫자형 행렬로 생성합니다. trainingData를 붓꽃 versicolor 종과 virginica 종의 꽃받침 길이와 너비 측정값을 포함하는 숫자형 행렬로 생성합니다.
[X,Y] = meshgrid(linspace(4.5,8),linspace(2,4)); X = X(:); Y = Y(:); sampleData = [X Y]; trainingData = [SL SW];
2차 판별분석을 사용하여 sampleData를 분류합니다.
[C,err,posterior,logp,coeff] = classify(sampleData,trainingData,group,'quadratic');두 클래스 간의 2차 경계에 대한 계수 K, L, M을 가져옵니다.
K = coeff(1,2).const; L = coeff(1,2).linear; Q = coeff(1,2).quadratic;
두 클래스를 구분하는 곡선은 다음 수식으로 정의됩니다.
판별 분류를 시각화합니다.
hold on h2 = gscatter(X,Y,C,'rb','.',1,'off'); f = @(x,y) K + L(1)*x + L(2)*y + Q(1,1)*x.*x + (Q(1,2)+Q(2,1))*x.*y + Q(2,2)*y.*y; h3 = fimplicit(f,[4.5 8 2 4]); h3.Color = 'm'; h3.LineWidth = 2; h3.DisplayName = 'Decision Boundary'; hold off axis tight xlabel('Sepal Length') ylabel('Sepal Width') title('Classification with Fisher Training Data')
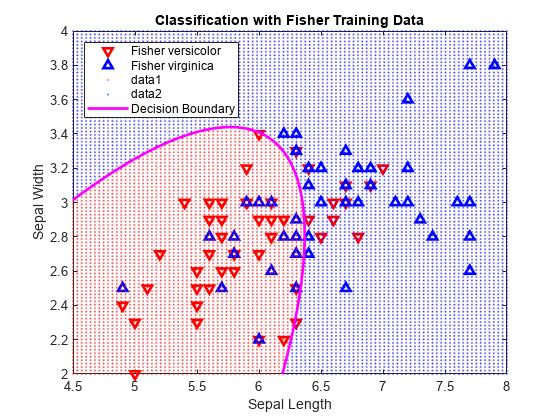
데이터 세트를 표본 데이터와 훈련 데이터로 분할하고 선형 판별분석을 사용하여 샘플 데이터를 분류합니다. 그런 다음 결정 경계를 시각화합니다.
fisheriris 데이터 세트를 불러옵니다. group을 붓꽃 종을 포함하는 문자형 벡터로 구성된 셀형 배열로 생성합니다. PL과 PW를 각각 꽃잎 길이 측정값과 꽃잎 너비 측정값을 포함하는 숫자형 벡터로 생성합니다.
load fisheriris
group = species;
PL = meas(:,3);
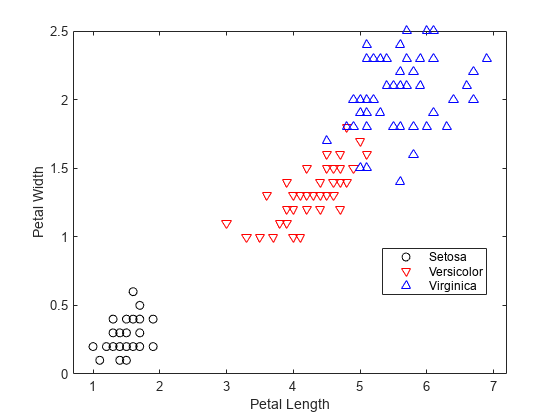
PW = meas(:,4);붓꽃 setosa, versicolor, virginica 종에 대한 꽃받침 길이(PL)와 너비(PW) 측정값을 플로팅합니다.
h1 = gscatter(PL,PW,species,'krb','ov^',[],'off'); legend('Setosa','Versicolor','Virginica','Location','best') xlabel('Petal Length') ylabel('Petal Width')
group의 그룹 정보를 사용하여 관측값을 층화된 훈련 세트(trainingData) 하나와 표본 세트(sampleData) 하나로 임의로 분할합니다. sampleData를 위해 10% 홀드아웃 표본을 지정합니다.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.10); trainInds = training(cv); sampleInds = test(cv); trainingData = [PL(trainInds) PW(trainInds)]; sampleData = [PL(sampleInds) PW(sampleInds)];
선형 판별분석을 사용하여 sampleData를 분류합니다.
[class,err,posterior,logp,coeff] = classify(sampleData,trainingData,group(trainInds));
두 번째 클래스와 세 번째 클래스 사이의 선형 경계에 대한 계수 K와 L을 가져옵니다.
K = coeff(2,3).const; L = coeff(2,3).linear;
두 번째 클래스와 세 번째 클래스를 구분하는 선은 수식 으로 정의됩니다. 두 번째 클래스와 세 번째 클래스 사이의 경계선을 플로팅합니다.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; hold on h2 = fimplicit(f,[.9 7.1 0 2.5]); h2.Color = 'r'; h2.DisplayName = 'Boundary between Versicolor & Virginica';
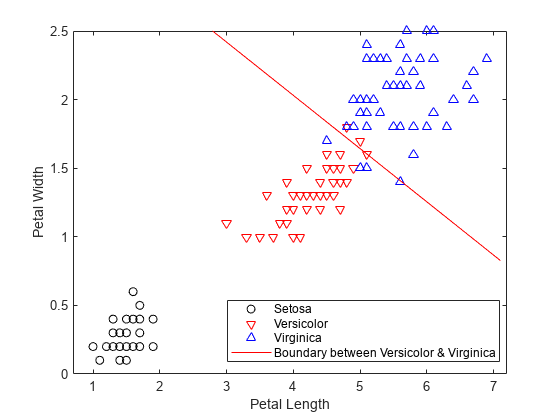
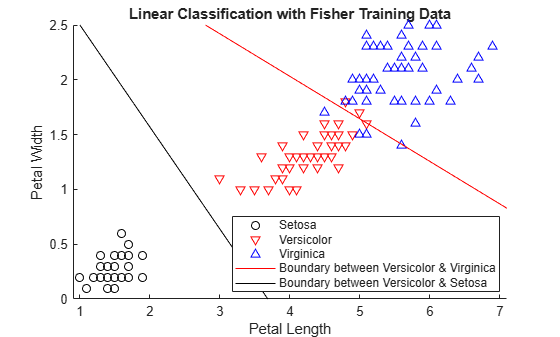
첫 번째 클래스와 두 번째 클래스 사이의 선형 경계에 대한 계수 K와 L을 가져옵니다.
K = coeff(1,2).const; L = coeff(1,2).linear;
첫 번째 클래스와 두 번째 클래스를 구분하는 선을 플로팅합니다.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; h3 = fimplicit(f,[.9 7.1 0 2.5]); hold off h3.Color = 'k'; h3.DisplayName = 'Boundary between Versicolor & Setosa'; axis tight title('Linear Classification with Fisher Training Data')
입력 인수
출력 인수
대체 기능
fitcdiscr 함수도 판별분석을 수행합니다. fitcdiscr 함수를 사용하여 분류기를 훈련시키고 predict 함수를 사용하여 새 데이터의 레이블을 예측할 수 있습니다. fitcdiscr 함수는 교차 검증 및 하이퍼파라미터 최적화를 지원하며, 새로운 예측을 하거나 사전 확률을 변경할 때마다 매번 분류기를 피팅할 필요가 없습니다.
참고 문헌
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. NY: Oxford University Press, 1988.
[2] Seber, George A. F. Multivariate Observations. NJ: John Wiley & Sons, Inc., 1984.
버전 내역
R2006a 이전에 개발됨