이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
일반화 파레토 분포를 사용하여 꼬리 데이터 모델링하기
이 예제에서는 최대가능도 추정을 통해 일반화 파레토 분포에 꼬리 데이터를 피팅하는 방법을 보여줍니다.
모수 분포를 데이터에 피팅하면 밀도가 높은 영역에서는 데이터와의 일치성이 높지만 밀도가 낮은 영역에서는 일치성이 떨어지는 모델이 생성되는 경우가 있습니다. 정규분포 또는 스튜던트 t 분포와 같은 단봉분포의 경우 이렇게 밀도가 낮은 영역을 분포의 "꼬리"라고 합니다. 모델이 꼬리에서 제대로 피팅되지 않는 이유 중 하나는, 관련 정의에 따르면, 모델 선택의 근거가 되는 데이터가 꼬리에서 더 적으며 따라서 최빈값 근처의 데이터를 피팅할 수 있는 모델이 선택되기 때문입니다. 또 다른 이유는 실제 데이터의 분포가 일반적인 모수적 모델보다 흔히 더 복잡하기 때문일 수 있습니다.
그러나, 데이터를 꼬리에 피팅하는 것은 많은 응용 사례에서 주요 과제입니다. 일반화 파레토 분포(GP)는 이론적 논거를 기반으로 다양한 분포에서 꼬리를 모델링할 수 있는 분포로 개발되었습니다. GP를 사용하여 분포 피팅을 하는 한 방법은 관측값이 많은 영역에 비모수적 피팅(예: 경험적 누적 분포 함수)을 사용하고 그 GP를 데이터의 꼬리에 피팅하는 것입니다.
일반화 파레토 분포
일반화 파레토 분포(GP)는 오른쪽이 비스듬한 분포이며, 형태 모수 k와 스케일 모수 sigma로 모수화됩니다. k는 "꼬리 인덱스" 모수라고도 하며 양수, 0(영) 또는 음수가 될 수 있습니다.
x = linspace(0,10,1000); plot(x,gppdf(x,-.4,1),'-', x,gppdf(x,0,1),'-', x,gppdf(x,2,1),'-'); xlabel('x / sigma'); ylabel('Probability density'); legend({'k < 0' 'k = 0' 'k > 0'});
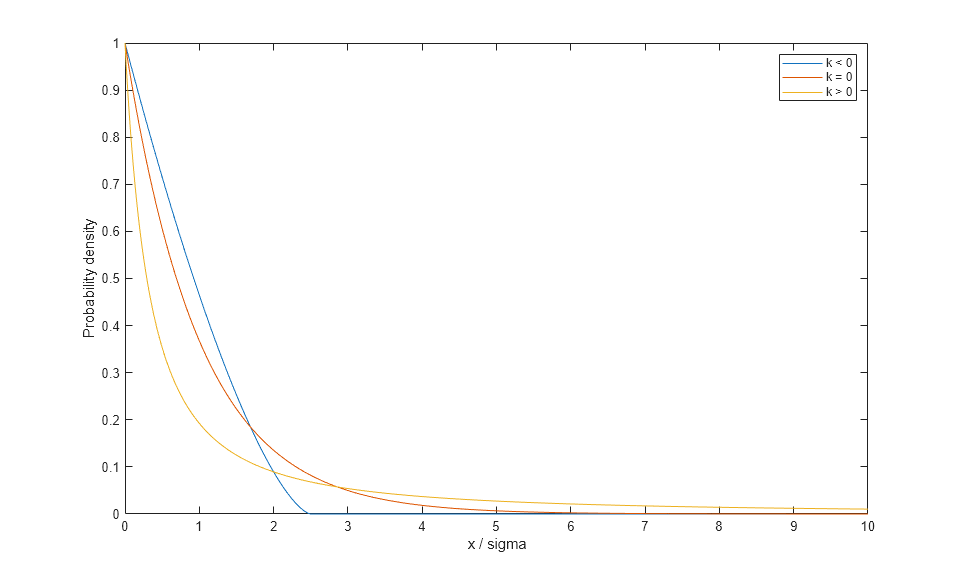
k < 0인 경우, GP는 상한 -(1/k)를 초과할 확률이 0입니다. k >= 0인 경우, GP에 상한이 없습니다. 또한, GP는 0에서 멀어지도록 하한을 이동시키는 세 번째 분계점 모수와 함께 사용되는 경우가 많습니다. 여기서는 이러한 일반성이 필요하지 않습니다.
GP 분포는 지수 분포(k = 0)와 파레토 분포(k > 0) 모두를 일반화한 것입니다. GP는 연속적인 형태 범위를 지원할 수 있도록 더 큰 분포군에 이 두 분포를 포함시킵니다.
초과량 데이터 시뮬레이션하기
GP 분포의 생성은 초과량의 관점에서 정의될 수 있습니다. 정규분포와 같이 오른쪽 꼬리가 0으로 떨어지는 확률 분포로 시작하여 해당 분포에 상관없이 난수 값을 추출할 수 있습니다. 분계점 값을 고정하고, 분계점 아래에 있는 모든 값을 버린 후, 버리지 않은 나머지 값에서 분계점을 뺀 결과를 초과량이라고 합니다. 초과량 분포는 GP에 가깝습니다. 마찬가지로, 분포의 왼쪽 꼬리에서 분계점을 설정하여 이 분계점보다 높은 값을 모두 무시할 수 있습니다. 근삿값이 타당하려면 분계점이 원래 분포의 꼬리에서 충분히 멀리 떨어져 있어야 합니다.
GP 분포의 형태 모수 k는 원래 분포에 의해 결정됩니다. 꼬리가 다항식으로 떨어지는 분포(예: 스튜던트 t 분포)의 경우 양의 형태 모수가 생성됩니다. 꼬리가 기하급수적으로 감소하는 분포(예: 정규분포)는 0 형태 모수에 대응합니다. 유한한 꼬리를 갖는 분포(예: 베타 분포)는 음의 형태 모수에 대응합니다.
GP 분포를 적용하는 실제 사례로는 주식 시장 수익의 극값이나 극단적 홍수 재해를 모델링하는 경우를 들 수 있습니다. 이 예제에서는 자유도가 5인 스튜던트 t 분포에서 생성된 시뮬레이션 데이터를 사용하겠습니다. t 분포에서 2000개 관측값 중 가장 큰 값부터 5%를 취한 후 95% 분위수를 차감하여 초과량을 구합니다.
rng(3,'twister');
x = trnd(5,2000,1);
q = quantile(x,.95);
y = x(x>q) - q;
n = numel(y)
n = 100
최대가능도를 사용하여 분포 피팅하기
GP 분포는 0 < sigma 및 -Inf < k < Inf에 대해 정의됩니다. 그러나, k < -1/2인 경우 최대가능도 추정의 결과를 해석하는 것이 문제가 될 수 있습니다. 다행히, 이러한 사례는 베타 분포 또는 삼각형분포와 같은 분포에서 꼬리를 피팅하는 것에 해당하므로 여기서는 문제가 없습니다.
paramEsts = gpfit(y); kHat = paramEsts(1) % Tail index parameter sigmaHat = paramEsts(2) % Scale parameter
kHat =
0.0987
sigmaHat =
0.7156
예상했던 대로 시뮬레이션된 데이터는 t 분포를 사용하여 생성되었으므로 k의 추정값은 양수입니다.
시각적으로 피팅 확인하기
피팅이 얼마나 일치하는지를 시각적으로 평가하기 위해 꼬리 데이터에 대한 스케일링된 히스토그램을 플로팅하고 GP에 대한 밀도 함수 추정값과 겹쳐 놓겠습니다. 이 히스토그램은 막대 높이와 막대 너비를 곱한 합이 1이 되도록 스케일링됩니다.
bins = 0:.25:7; h = bar(bins,histc(y,bins)/(length(y)*.25),'histc'); h.FaceColor = [.9 .9 .9]; ygrid = linspace(0,1.1*max(y),100); line(ygrid,gppdf(ygrid,kHat,sigmaHat)); xlim([0,6]); xlabel('Exceedance'); ylabel('Probability Density');
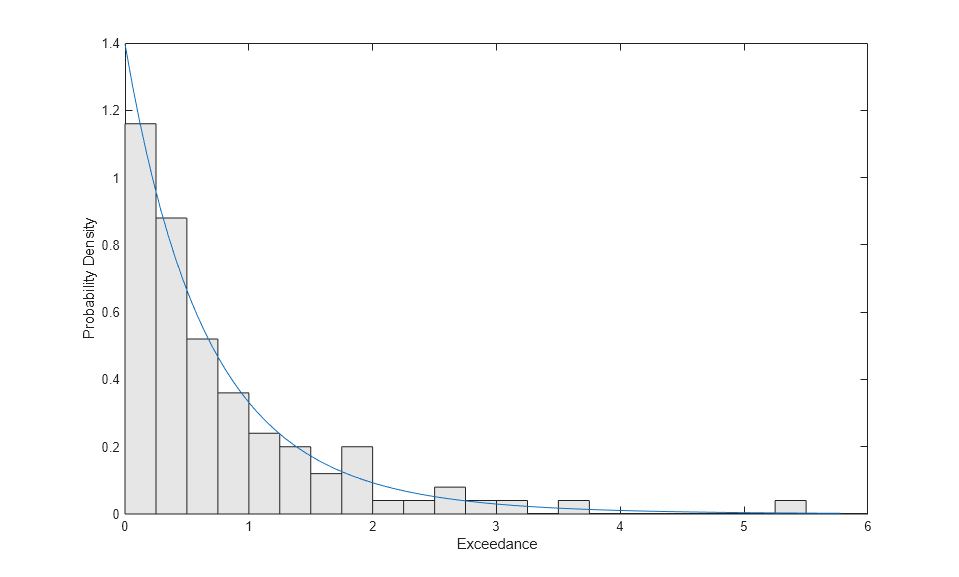
여기서는 상당히 작은 Bin 너비를 사용했으므로 히스토그램에 잡음이 많습니다. 그러나 피팅된 밀도가 데이터의 형태를 따르므로 GP 모델이 좋은 선택으로 보입니다.
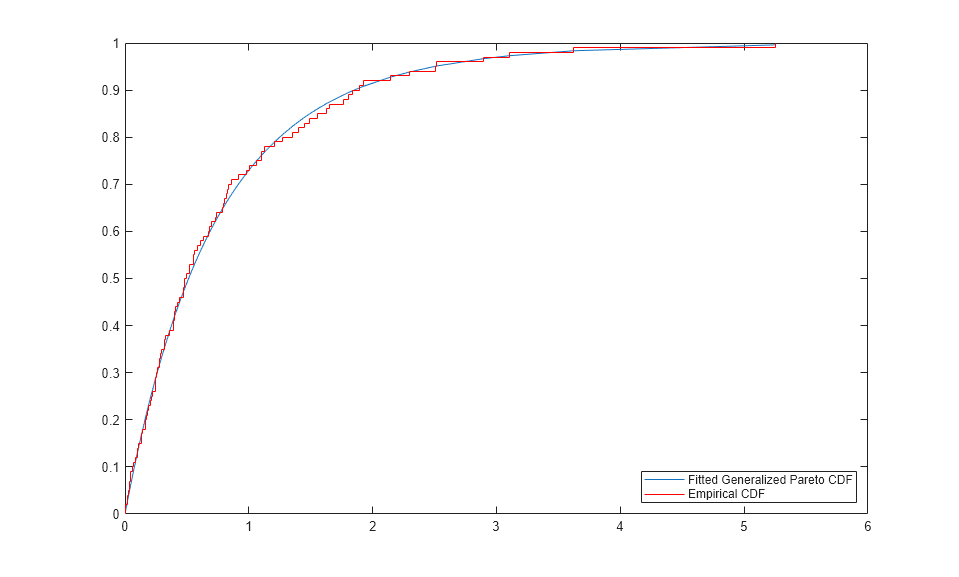
경험적 CDF를 피팅된 CDF와 비교할 수도 있습니다.
[F,yi] = ecdf(y); plot(yi,gpcdf(yi,kHat,sigmaHat),'-'); hold on; stairs(yi,F,'r'); hold off; legend('Fitted Generalized Pareto CDF','Empirical CDF','location','southeast');
모수 추정값에 대한 표준 오차 계산하기
추정값의 정밀도를 수치화하기 위해 최대가능도 추정량으로 구성된 점근적 공분산 행렬에서 계산한 표준 오차를 사용하겠습니다. 함수 gplike는 해당 공분산 행렬에 대한 수치 근사를 두 번째 출력값으로 계산합니다. 또는, 두 개의 출력 인수를 사용하여 gpfit을 호출할 수 있으며 이 경우 모수에 대한 신뢰구간이 반환됩니다.
[nll,acov] = gplike(paramEsts, y); stdErr = sqrt(diag(acov))
stdErr =
0.1158
0.1093
이 표준 오차는 k의 추정값의 상대 정밀도가 sigma의 추정값의 상대 정밀도보다 많이 낮으며, 따라서 표준 오차가 추정값에 가깝다는 것을 나타냅니다. 형태 모수는 대개 추정하기가 어렵습니다. 이 표준 오차를 계산할 때 GP 모델이 올바르며 공분산 행렬에 대한 점근적 근사가 가능할 만큼 데이터가 충분히 있다고 가정했음을 명심하십시오.
점근적 정규성 가정 확인하기
일반적으로 표준 오차를 해석할 때 동일한 소스에서 가져온 데이터에 대해 동일한 피팅을 여러 번 반복할 수 있다면 그 모수의 최대가능도 추정값이 대략적으로 정규분포를 따른다고 가정합니다. 예를 들어, 신뢰구간은 대개 이러한 가정을 바탕으로 합니다.
그러나, 해당 정규 근삿값이 양호할 수도 있고 양호하지 않을 수도 있습니다. 이 예제에서는 부트스트랩 시뮬레이션을 사용하여 근삿값이 얼마나 양호한지 평가할 수 있습니다. 데이터에서 표본을 재추출하여 1000개의 반복 실험 데이터 세트를 생성하고 GP 분포를 각 데이터 세트에 피팅한 후 반복 실험 추정값을 모두 저장하겠습니다.
replEsts = bootstrp(1000,@gpfit,y);
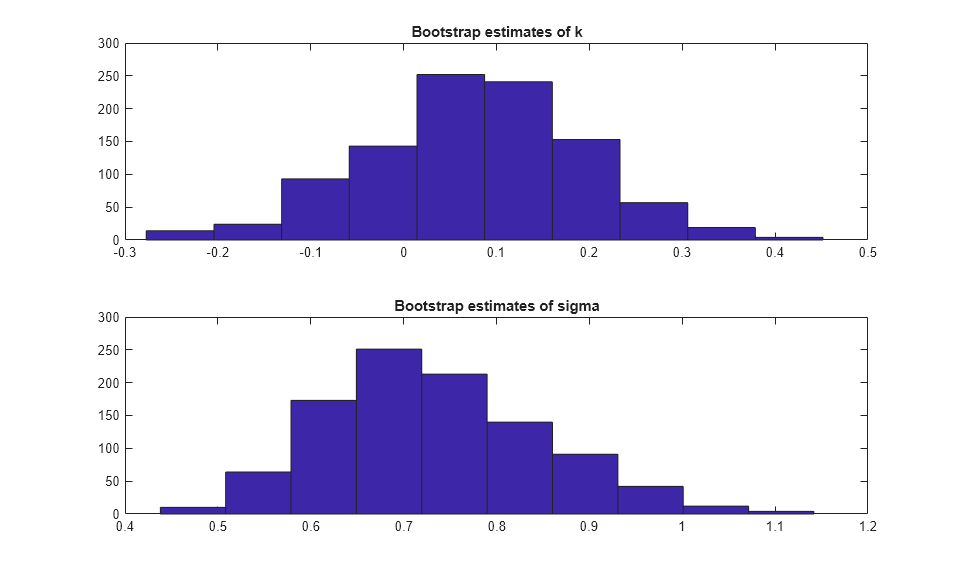
모수 추정량의 표집 분포에 대한 간단한 확인 절차로 부트스트랩 반복 실험에 대한 히스토그램을 살펴볼 수 있습니다.
subplot(2,1,1); hist(replEsts(:,1)); title('Bootstrap estimates of k'); subplot(2,1,2); hist(replEsts(:,2)); title('Bootstrap estimates of sigma');
모수 변환 사용하기
k의 부트스트랩 추정값에 대한 히스토그램은 아주 약간 비대칭으로 보이지만 sigma 추정값에 대한 히스토그램은 확실하게 오른쪽으로 편향되어 보입니다. 이 편향에 대한 일반적인 해결 방법은 로그 스케일에서 모수와 해당 표준 오차를 추정하는 것입니다. 이 경우 정규 근사를 수행하는 것이 더욱 타당할 수 있습니다. Q-Q 플롯은 직선을 대략적으로 따르지 않는 점으로 비정규성을 나타내므로 정규성을 평가하는 데는 히스토그램보다 Q-Q 플롯이 더 좋은 방법입니다. sigma에 로그 변환을 적용하는 것이 적절한지 살펴보겠습니다.
subplot(1,2,1); qqplot(replEsts(:,1)); title('Bootstrap estimates of k'); subplot(1,2,2); qqplot(log(replEsts(:,2))); title('Bootstrap estimates of log(sigma)');

k와 log(sigma)의 부트스트랩 추정값이 허용되는 수준으로 정규성에 가깝게 보입니다. sigma 추정값에 대한 Q-Q 플롯을 로그 변환되지 않은 스케일에 그려보면 앞의 히스토그램에서도 봤던 왜도를 확인할 수 있습니다. 따라서, 정규성을 띤다는 가정 하에 log(sigma)에 대한 신뢰구간을 먼저 계산한 후 지수화(거듭제곱)하여 해당 구간을 sigma의 원래 스케일로 다시 변환하는 방법으로 sigma에 대한 신뢰구간을 생성하는 것이 더욱 타당할 수 있습니다.
실제로, 이것이 바로 함수 gpfit이 자동으로 수행하는 연산입니다.
[paramEsts,paramCI] = gpfit(y);
kHat kCI = paramCI(:,1)
kHat =
0.0987
kCI =
-0.1283
0.3258
sigmaHat sigmaCI = paramCI(:,2)
sigmaHat =
0.7156
sigmaCI =
0.5305
0.9654
k에 대한 95% 신뢰구간이 최대가능도 추정값에 대해 대칭인 반면, sigma에 대한 신뢰구간은 대칭이 아닙니다. 그 이유는 log(sigma)에 대한 대칭 CI를 변환하여 생성되었기 때문입니다.