updateMetrics
Update performance metrics in linear incremental learning model given new data
Description
Given streaming data, updateMetrics measures the performance of a configured incremental learning model for linear regression (incrementalRegressionLinear object) or linear binary classification (incrementalClassificationLinear object). updateMetrics stores the performance metrics in the output model.
updateMetrics allows for flexible incremental learning. After you call the function to update model performance metrics on an incoming chunk of data, you can perform other actions before you train the model to the data. For example, you can decide whether you need to train the model based on its performance on a chunk of data. Alternatively, you can both update model performance metrics and train the model on the data as it arrives, in one call, by using the updateMetricsAndFit function.
To measure the model performance on a specified batch of data, call loss instead.
Mdl = updateMetrics(Mdl,X,Y)Mdl, which is the input incremental learning model Mdl modified to contain the model performance metrics on the incoming predictor and response data, X and Y respectively.
When the input model is warm (Mdl.IsWarm is true), updateMetrics overwrites previously computed metrics, stored in the Metrics property, with the new values. Otherwise, updateMetrics stores NaN values in Metrics instead.
The input and output models have the same data type.
Examples
Train a linear model for binary classification by using fitclinear, convert it to an incremental learner, and then track its performance to streaming data.
Load and Preprocess Data
Load the human activity data set. Randomly shuffle the data.
load humanactivity rng(1) % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, or Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = Y > 2;
Train Linear Model for Binary Classification
Fit a linear model for binary classification to a random sample of half the data.
idxtt = randsample([true false],n,true); TTMdl = fitclinear(X(idxtt,:),Y(idxtt))
TTMdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.2999
Lambda: 8.2967e-05
Learner: 'svm'
Properties, Methods
TTMdl is a ClassificationLinear model object representing a traditionally trained linear model for binary classification.
Convert Trained Model
Convert the traditionally trained classification model to a binary classification linear model for incremental learning.
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationLinear
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.2999
Learner: 'svm'
Properties, Methods
IncrementalMdl.IsWarm
ans = logical
1
The incremental model is warm. Therefore, updateMetrics can track model performance metrics given data.
Track Performance Metrics
Track the model performance on the rest of the data by using the updateMetrics function. Simulate a data stream by processing 50 observations at a time. At each iteration:
Call
updateMetricsto update the cumulative and window classification error of the model given the incoming chunk of observations. Overwrite the previous incremental model to update the losses in theMetricsproperty. Note that the function does not fit the model to the chunk of data—the chunk is "new" data for the model.Store the classification error and first coefficient .
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta1 = [IncrementalMdl.Beta(1); zeros(nchunk+1,1)]; Xil = X(idxil,:); Yil = Y(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetrics(IncrementalMdl,Xil(idx,:),Yil(idx)); ce{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; beta1(j + 1) = IncrementalMdl.Beta(1); end
IncrementalMdl is an incrementalClassificationLinear model object that has tracked the model performance to observations in the data stream.
Plot a trace plot of the performance metrics and estimated coefficient .
t = tiledlayout(2,1); nexttile h = plot(ce.Variables); xlim([0 nchunk]) ylabel('Classification Error') legend(h,ce.Properties.VariableNames) nexttile plot(beta1) ylabel('\beta_1') xlim([0 nchunk]) xlabel(t,'Iteration')
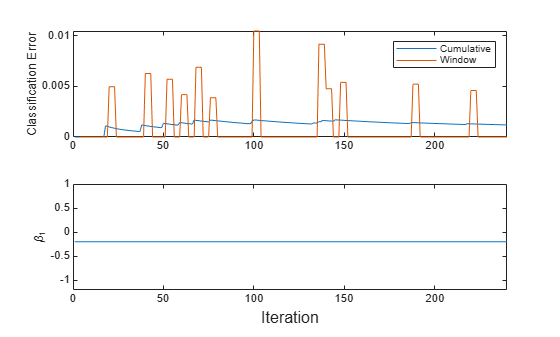
The cumulative loss is stable, whereas the window loss jumps.
does not change because updateMetrics does not fit the model to the data.
Create an incremental linear SVM model for binary classification. Specify an estimation period of 5,000 observations and the SGD solver.
Mdl = incrementalClassificationLinear('EstimationPeriod',5000,'Solver','sgd')
Mdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
Beta: [0×1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl is an incrementalClassificationLinear model. All its properties are read-only.
Determine whether the model is warm and the size of the metrics warm-up period by querying model properties.
isWarm = Mdl.IsWarm
isWarm = logical
0
mwp = Mdl.MetricsWarmupPeriod
mwp = 1000
Mdl.IsWarm is 0; therefore, Mdl is not warm.
Determine the number of observations incremental fitting functions, such as fit, must process before measuring the performance of the model.
numObsBeforeMetrics = Mdl.MetricsWarmupPeriod + Mdl.EstimationPeriod
numObsBeforeMetrics = 6000
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, or Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = Y > 2;
Perform incremental learning. At each iteration:
Simulate a data stream by processing a chunk of 50 observations.
Measure model performance metrics on the incoming chunk using
updateMetrics. Overwrite the input model.Fit the model to the incoming chunk by using the
fitfunction. Overwrite the input model.Store and the misclassification error rate to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta1 = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); ce{j,:} = Mdl.Metrics{"ClassificationError",:}; Mdl = fit(Mdl,X(idx,:),Y(idx)); beta1(j) = Mdl.Beta(1); end
Mdl is an incrementalClassificationLinear model object trained on all the data in the stream.
To see how the parameters evolve during incremental learning, plot them on separate tiles.
t = tiledlayout(2,1); nexttile plot(beta1) ylabel('\beta_1') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') xlabel('Iteration') axis tight nexttile plot(ce.Variables) ylabel('ClassificationError') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') xline(numObsBeforeMetrics/numObsPerChunk,'g-.') xlim([0 nchunk]) legend(ce.Properties.VariableNames) xlabel(t,'Iteration')
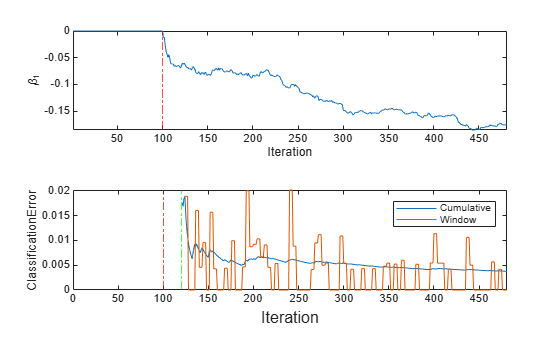
mdlIsWarm = numObsBeforeMetrics/numObsPerChunk
mdlIsWarm = 120
The plot suggests that fit does not fit the model to the data or update the parameters until after the estimation period. Also, updateMetrics does not track the classification error until after the estimation and metrics warm-up periods (120 chunks).
Incrementally train a linear regression model only when its performance degrades.
Load and shuffle the 2015 NYC housing data set. For more details on the data, see NYC Open Data.
load NYCHousing2015 rng(1) % For reproducibility n = size(NYCHousing2015,1); shuffidx = randsample(n,n); NYCHousing2015 = NYCHousing2015(shuffidx,:);
Extract the response variable SALEPRICE from the table. For numerical stability, scale SALEPRICE by 1e6.
Y = NYCHousing2015.SALEPRICE/1e6; NYCHousing2015.SALEPRICE = [];
Create dummy variable matrices from the categorical predictors.
catvars = ["BOROUGH" "BUILDINGCLASSCATEGORY" "NEIGHBORHOOD"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015,... 'InputVariables',catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
Treat all other numeric variables in the table as linear predictors of sales price. Concatenate the matrix of dummy variables to the rest of the predictor data, and transpose the data to speed up computations.
idxnum = varfun(@isnumeric,NYCHousing2015,'OutputFormat','uniform'); X = [dumvarmat NYCHousing2015{:,idxnum}]';
Configure a linear regression model for incremental learning so that it does not have an estimation or metrics warm-up period. Specify a metrics window size of 1000 observations. Fit the configured model to the first 100 observations, and specify that the observations are oriented along the columns of the data.
Mdl = incrementalRegressionLinear('EstimationPeriod',0,'MetricsWarmupPeriod',0,... 'MetricsWindowSize',1000); numObsPerChunk = 100; Mdl = fit(Mdl,X(:,1:numObsPerChunk),Y(1:numObsPerChunk),'ObservationsIn','columns');
Mdl is an incrementalRegressionLinear model object.
Perform incremental learning, with conditional fitting, by following this procedure for each iteration:
Simulate a data stream by processing a chunk of 100 observations.
Update the model performance by computing the epsilon insensitive loss, within a 200 observation window. Specify that the observations are oriented along the columns of the data.
Fit the model to the chunk of data only when the loss more than doubles from the minimum loss experienced. Specify that the observations are oriented along the columns of the data.
When tracking performance and fitting, overwrite the previous incremental model.
Store the epsilon insensitive loss and to see the how the loss and coefficient evolve during training.
Track when
fittrains the model.
% Preallocation n = numel(Y) - numObsPerChunk; nchunk = floor(n/numObsPerChunk); beta313 = zeros(nchunk,1); ei = array2table(nan(nchunk,2),'VariableNames',["Cumulative" "Window"]); trained = false(nchunk,1); % Incremental fitting for j = 2:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(:,idx),Y(idx),'ObservationsIn','columns'); ei{j,:} = Mdl.Metrics{"EpsilonInsensitiveLoss",:}; minei = min(ei{:,2}); pdiffloss = (ei{j,2} - minei)/minei*100; if pdiffloss > 100 Mdl = fit(Mdl,X(:,idx),Y(idx),'ObservationsIn','columns'); trained(j) = true; end beta313(j) = Mdl.Beta(end); end
Mdl is an incrementalRegressionLinear model object trained on all the data in the stream.
To see how the model performance and evolve during training, plot them on separate tiles.
t = tiledlayout(2,1); nexttile plot(beta313) hold on plot(find(trained),beta313(trained),'r.') xlim([0 nchunk]) ylabel('\beta_{313}') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') legend('\beta_{313}','Training occurs','Location','southeast') hold off nexttile plot(ei.Variables) xlim([0 nchunk]) ylabel('Epsilon Insensitive Loss') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') legend(ei.Properties.VariableNames) xlabel(t,'Iteration')
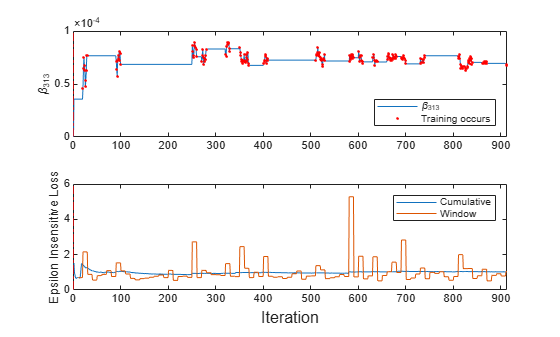
The trace plot of shows periods of constant values, during which the loss did not double from the minimum experienced.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Unlike traditional training, incremental learning might not have a separate test (holdout) set. Therefore, to treat each incoming chunk of data as a test set, pass the incremental model and each incoming chunk to
updateMetricsbefore training the model on the same data usingfit.
Algorithms
Extended Capabilities
Version History
Introduced in R2020b