이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
회귀 신경망 성능 평가하기
fitrnet을 사용하여 완전 연결 계층을 가진 피드포워드 회귀 신경망 모델을 만듭니다. 모델 과적합을 방지하기 위해 검증 데이터를 사용하여 훈련 과정을 조기에 중단합니다. 그런 다음, 모델의 객체 함수를 사용해 테스트 데이터로 모델 성능을 평가합니다.
표본 데이터 불러오기
1970년대와 1980년대 초에 제조된 자동차의 측정값을 포함하는 carbig 데이터 세트를 불러옵니다.
load carbigOrigin 변수를 categorical형 변수로 변환합니다. 그런 다음, Acceleration, Displacement 등의 예측 변수와 MPG 응답 변수를 포함하는 테이블을 만듭니다. 각 행은 자동차 한 대의 측정값을 포함합니다. 테이블에서 누락값이 있는 행은 삭제합니다.
Origin = categorical(cellstr(Origin));
Tbl = table(Acceleration,Displacement,Horsepower, ...
Model_Year,Origin,Weight,MPG);
Tbl = rmmissing(Tbl);데이터 분할하기
데이터를 훈련 세트, 검증 세트, 테스트 세트로 분할합니다. 먼저, 관측값의 약 1/3은 테스트 세트용으로 남겨둡니다. 그런 다음, 남은 데이터를 반으로 나누어 훈련 세트와 검증 세트를 만듭니다.
rng("default") % For reproducibility of the data partitions cvp1 = cvpartition(size(Tbl,1),"Holdout",1/3); testTbl = Tbl(test(cvp1),:); remainingTbl = Tbl(training(cvp1),:); cvp2 = cvpartition(size(remainingTbl,1),"Holdout",1/2); validationTbl = remainingTbl(test(cvp2),:); trainTbl = remainingTbl(training(cvp2),:);
신경망 훈련시키기
훈련 세트를 사용하여 회귀 신경망 모델을 훈련시킵니다. tblTrain의 MPG 열을 응답 변수로 지정하고, 숫자형 예측 변수를 표준화합니다. 검증 세트를 사용하여 각 반복 시 모델을 평가합니다. Verbose 이름-값 인수를 사용하여 각 반복 시 훈련 정보를 표시하도록 지정합니다. 기본적으로, 검증 손실이 지금까지 계산된 최소 검증 손실보다 크거나 같은 경우가 6회 연속 발생하면 훈련 과정이 조기에 종료됩니다. 검증 손실이 최솟값보다 크거나 같아도 되는 횟수를 변경하려면 ValidationPatience 이름-값 인수를 지정하십시오.
Mdl = fitrnet(trainTbl,"MPG","Standardize",true, ... "ValidationData",validationTbl, ... "Verbose",1);
|==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 1| 102.962345| 46.853164| 6.700877| 0.032779| 115.730384| 0| | 2| 55.403995| 22.171181| 1.811805| 0.020571| 53.086379| 0| | 3| 37.588848| 11.135231| 0.782861| 0.005298| 38.580002| 0| | 4| 29.713458| 8.379231| 0.392009| 0.003921| 31.021379| 0| | 5| 17.523851| 9.958164| 2.137584| 0.003729| 17.594863| 0| | 6| 12.700624| 2.957771| 0.744551| 0.003962| 14.209019| 0| | 7| 11.841152| 1.907378| 0.201770| 0.003880| 13.159899| 0| | 8| 10.162988| 2.542555| 0.576907| 0.003956| 11.352490| 0| | 9| 8.889095| 2.779980| 0.615716| 0.002668| 10.446334| 0| | 10| 7.670335| 2.400272| 0.648711| 0.011382| 10.424337| 0| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 11| 7.416274| 0.505111| 0.214707| 0.005407| 10.522517| 1| | 12| 7.338923| 0.880655| 0.119085| 0.004414| 10.648031| 2| | 13| 7.149407| 1.784821| 0.277908| 0.002899| 10.800952| 3| | 14| 6.866385| 1.904480| 0.472190| 0.005637| 10.839202| 4| | 15| 6.815575| 3.339285| 0.943063| 0.002956| 10.031692| 0| | 16| 6.428137| 0.684771| 0.133729| 0.003287| 9.867819| 0| | 17| 6.363299| 0.456606| 0.125363| 0.006535| 9.720076| 0| | 18| 6.289887| 0.742923| 0.152290| 0.009971| 9.576588| 0| | 19| 6.215407| 0.964684| 0.183503| 0.002971| 9.422910| 0| | 20| 6.078333| 2.124971| 0.566948| 0.002843| 9.599573| 1| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 21| 5.947923| 1.217291| 0.583867| 0.003745| 9.618400| 2| | 22| 5.855505| 0.671774| 0.285123| 0.002729| 9.734680| 3| | 23| 5.831802| 1.882061| 0.657368| 0.001770| 10.365968| 4| | 24| 5.713261| 1.004072| 0.134719| 0.001882| 10.314258| 5| | 25| 5.520766| 0.967032| 0.290156| 0.001891| 10.177322| 6| |==========================================================================================|
객체 Mdl의 TrainingHistory 속성에 있는 정보를 사용하여 검증 세트의 MSE(평균제곱오차)가 최소가 되는 반복을 확인합니다. 최종적으로 반환된 모델 Mdl은 이 반복에서 훈련된 모델입니다.
iteration = Mdl.TrainingHistory.Iteration; valLosses = Mdl.TrainingHistory.ValidationLoss; [~,minIdx] = min(valLosses); iteration(minIdx)
ans = 19
테스트 세트 성능 평가하기
loss 및 predict 객체 함수를 사용하여, 훈련된 모델 Mdl의 성능을 테스트 세트 testTbl에 대해 평가합니다.
테스트 세트의 MSE(평균제곱오차)를 계산합니다. MSE 값이 작을수록 성능이 더 우수하다는 뜻입니다.
mse = loss(Mdl,testTbl,"MPG")mse = 7.4101
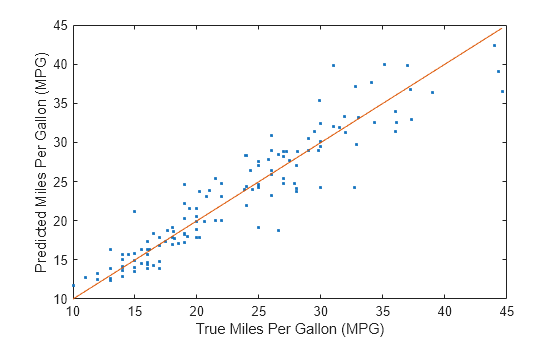
예측된 테스트 세트의 응답 변수 값을 실제 응답 변수 값과 비교합니다. 예측된 MPG(갤런당마일)가 세로 축에, 실제 MPG가 가로 축에 표시되도록 플로팅합니다. 기준선 위에 있는 점들은 정확한 예측값을 나타냅니다. 양호한 모델은 예측값들이 선 근처에 흩어져 있는 결과를 생성합니다.
predictedY = predict(Mdl,testTbl); plot(testTbl.MPG,predictedY,".") hold on plot(testTbl.MPG,testTbl.MPG) hold off xlabel("True Miles Per Gallon (MPG)") ylabel("Predicted Miles Per Gallon (MPG)")
예측된 MPG 값과 실제 MPG 값의 분포를 상자 플롯을 사용하여 원산지별로 비교합니다. boxchart 함수를 사용하여 상자 플롯을 만듭니다. 각 상자 플롯에는 중앙값, 하위 사분위수 및 상위 사분위수, 이상값(사분위 범위를 사용하여 계산), 이상값이 아닌 최솟값 및 최댓값이 표시됩니다. 특히, 각 상자 내부의 선은 표본 중앙값이고, 원형 마커는 이상값입니다.
각 원산지별로 빨간색 상자 플롯(예측된 MPG 값의 분포 표시)과 파란색 상자 플롯(실제 MPG 값의 분포 표시)을 비교합니다. 예측된 MPG 값과 실제 MPG 값의 분포가 유사하다면 예측이 양호함을 나타냅니다.
boxchart(testTbl.Origin,testTbl.MPG) hold on boxchart(testTbl.Origin,predictedY) hold off legend(["True MPG","Predicted MPG"]) xlabel("Country of Origin") ylabel("Miles Per Gallon (MPG)")
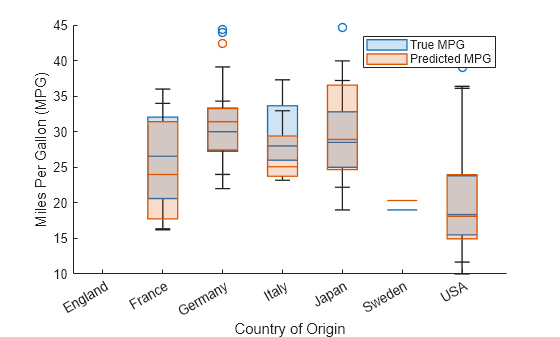
대부분의 국가에서, 예측된 MPG 값과 실제 MPG 값이 유사한 분포를 보입니다. 일부 불일치는 훈련 세트와 테스트 세트에 포함된 자동차 수가 적기 때문일 수 있습니다.
훈련 세트와 테스트 세트에서 자동차의 MPG 값 범위를 비교합니다.
trainSummary = grpstats(trainTbl(:,["MPG","Origin"]),"Origin", ... "range")
trainSummary=6×3 table
Origin GroupCount range_MPG
_______ __________ _________
France France 2 1.2
Germany Germany 12 23.4
Italy Italy 1 0
Japan Japan 26 26.6
Sweden Sweden 4 8
USA USA 86 27
testSummary = grpstats(testTbl(:,["MPG","Origin"]),"Origin", ... "range")
testSummary=6×3 table
Origin GroupCount range_MPG
_______ __________ _________
France France 4 19.8
Germany Germany 13 20.3
Italy Italy 4 11.3
Japan Japan 26 25.6
Sweden Sweden 1 0
USA USA 82 29
프랑스, 이탈리아, 스웨덴과 같이 훈련 및 테스트 세트에 자동차 수가 적은 국가의 경우, 두 세트 모두에서 MPG 값의 범위가 크게 다릅니다.
테스트 세트 잔차를 플로팅합니다. 양호한 모델은 일반적으로 잔차가 0 주변에 대략 대칭적으로 흩어져 있습니다. 잔차에 명확한 패턴이 나타난다면, 모델을 개선할 여지가 있음을 시사합니다.
residuals = testTbl.MPG - predictedY; plot(testTbl.MPG,residuals,".") hold on yline(0) hold off xlabel("True Miles Per Gallon (MPG)") ylabel("MPG Residuals")
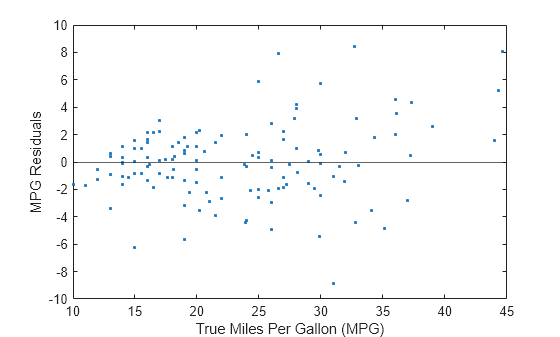
이 플롯은 잔차가 고르게 분포되어 있음을 보여줍니다.
절댓값 기준으로 잔차가 가장 큰 관측값에 대해 추가 정보를 얻을 수 있습니다.
[~,residualIdx] = sort(residuals,"descend", ... "ComparisonMethod","abs"); residuals(residualIdx)
ans = 130×1
-8.8469
8.4427
8.0493
7.8996
-6.2220
5.8589
5.7007
-5.6733
-5.4545
5.1899
-4.9175
-4.8600
4.5415
-4.3959
-4.3915
⋮
잔차가 가장 큰 관측값, 즉 크기가 8보다 큰 관측값 3개를 표시합니다.
testTbl(residualIdx(1:3),:)
ans=3×7 table
Acceleration Displacement Horsepower Model_Year Origin Weight MPG
____________ ____________ __________ __________ ______ ______ ____
17.6 91 68 82 Japan 1970 31
11.4 168 132 80 Japan 2910 32.7
13.8 91 67 80 Japan 1850 44.6
참고 항목
fitrnet | loss | predict | RegressionNeuralNetwork | boxchart