분류 학습기의 분류기 성능 시각화 및 평가하기
분류 학습기 앱에서 분류기를 훈련시킨 후 정확도 값을 기반으로 모델을 비교하고, 클래스 예측값을 플로팅하여 결과를 시각화하고, 혼동행렬, ROC 곡선, 정밀도-재현율 곡선을 사용하여 성능을 평가할 수 있습니다.
k겹 교차 검증을 사용하는 경우 앱은 k 검증 겹의 결합된 관측값 세트를 사용하여 모델 메트릭(예: 오차율)을 계산하고 평균값을 보고합니다. 앱은 검증 겹의 관측값에 대한 예측을 수행하고, 해당 예측값을 플롯에 표시합니다.
데이터를 앱으로 가져오면 앱은 기본적으로 교차 검증을 자동으로 사용합니다. 다른 검증 방식을 선택하려면 Select Validation Scheme in Classification Learner or Regression Learner 항목을 참조하십시오.
홀드아웃 검증을 사용하는 경우, 앱은 검증 세트의 관측값을 사용하여 예측을 수행하고 모델 메트릭을 계산합니다. 앱은 또한 예측값을 기반으로 혼동행렬, ROC 곡선, 정밀도-재현율 곡선을 계산합니다.
재대입 검증을 사용하는 경우, 앱은 전체 모델을 훈련하는 데 사용되는 동일한 훈련 데이터 세트를 사용하여 예측을 수행하고 모델 메트릭을 계산합니다.
모델 창에서 성능 검사하기
분류 학습기에서 모델을 훈련시킨 후 모델 창에서 전반적인 정확도(단위: 백분율)가 가장 우수한 모델을 확인합니다. 가장 높은 정확도(검증) 점수가 상자에 강조 표시됩니다. 이 점수는 검증 정확도입니다. 검증 정확도 점수는 훈련 데이터와 비교하여 새 데이터에 대한 모델의 성능을 추정합니다. 점수를 참고하면 가장 적합한 모델을 선택하는 데 도움이 됩니다.

전반적인 점수가 가장 높은 모델이 목표에 가장 적합한 모델이 아닐 수도 있습니다. 전반적인 정확도가 약간 낮은 모델이 목표에 가장 적합한 분류기일 수 있습니다. 예를 들어 특정 클래스의 거짓양성이 중요할 수 있습니다. 데이터 수집이 어렵거나 비용이 많이 드는 일부 예측 변수를 제외하고 싶을 수도 있습니다.
각 클래스에서 분류기의 성능이 어땠는지 알아보려면 혼동행렬을 살펴보십시오.
요약 탭과 모델 창에서 모델 메트릭 보기
모델 요약 탭과 모델 창에서 모델 메트릭을 보고, 메트릭을 사용하여 모델을 평가하고 비교할 수 있습니다. 또는 결과 비교 플롯과 결과값 테이블 탭을 사용하여 모델을 비교할 수 있습니다. 자세한 내용은 결과 비교 플롯에서 모델 정보와 결과 보기 항목과 테이블 뷰에서 모델 정보와 결과 비교하기 항목을 참조하십시오.
훈련 결과 메트릭과 추가 훈련 결과 메트릭은 검증 세트에서 계산됩니다. 테스트 결과 메트릭과 추가 테스트 결과 메트릭(표시되는 경우)은 테스트 데이터 세트에서 계산됩니다. 자세한 내용은 테스트 데이터 세트를 사용하여 모델 성능 평가하기 항목을 참조하십시오.

모델 메트릭
| 메트릭 | 설명 | 팁 |
|---|---|---|
| 정확도 | 올바르게 분류된 관측값의 백분율 | 정확도가 큰 값을 찾으십시오. |
| 총 비용 | 총 오분류 비용. 기본적으로 총 오분류 비용은 오분류된 관측값의 개수입니다. 자세한 내용은 Misclassification Costs in Classification Learner App 항목을 참조하십시오. | 총 비용 값이 작은 값을 찾으십시오. 정확도 값은 여전히 커야 합니다. |
| 오차율 | 오분류된 관측값의 백분율. 오차율은 1에서 정확도를 뺀 값입니다. | 오차율이 작은 값을 찾으십시오. |
| 예측 속도 | 검증 데이터 세트에 대한 예측 시간을 기반으로 기대되는 새 데이터 예측 속도 | 앱 내부와 외부의 배경 프로세스가 이 추정값에 영향을 미칠 수 있으므로 더 잘 비교될 수 있도록 유사한 조건에서 모델을 훈련시키십시오. |
| 훈련 시간 | 모델을 훈련하는 데 소요된 시간 | 앱 내부와 외부의 배경 프로세스가 이 추정값에 영향을 미칠 수 있으므로 더 잘 비교될 수 있도록 유사한 조건에서 모델을 훈련시키십시오. |
| 모델 크기(간소) | 간소 모델로 내보낸 경우(즉, 훈련 데이터 없이 내보낸 경우) 머신러닝 모델 객체의 크기. 모델을 작업 공간으로 내보낼 때, 내보내는 구조체에 모델 객체와 추가 필드가 포함됩니다. 앱은 whos 함수가 반환하는 모델 객체의 크기(단위: 바이트)를 표시합니다. learnersize 함수는 whos를 호출하기 전에 모델 객체에서 gather를 호출하기 때문에 일부 모델 유형에 대해서는 다른 크기를 반환할 수도 있다는 점에 유의하십시오. | 타깃 애플리케이션의 메모리 요구 사항에 맞는 모델 크기 값을 찾으십시오. |
| 모델 크기(Coder) | MATLAB® Coder™에 의해 생성된 C/C++ 코드에서 모델의 대략적인 크기(단위: 바이트). 앱은 type="coder"로 지정된 learnersize 함수가 반환하는 크기(단위: 바이트)를 표시합니다. 코드 생성 시 지원되지 않는 모델 유형의 경우 코더 모델 크기는 NaN입니다. | 지원되는 모델 유형 목록은 Export Classification Model to MATLAB Coder to Generate C/C++ Code 항목을 참조하십시오. |
앱은 세 가지 추가적인 모델 메트릭인 정밀도, 재현율, F1 점수를 제공합니다. 이러한 메트릭은 알려진 클래스가 포함된 검증 데이터 또는 테스트 데이터에 대해 모델이 올바른 예측(참양성 및 참음성)과 잘못된 예측(거짓양성 및 거짓음성)을 하는 빈도를 나타내는 지표입니다. 또한 이러한 메트릭은 클래스별로 제공되거나, 모든 클래스에 대해 매크로 평균, 마이크로 평균 또는 가중 평균 중 한 방법을 사용하여 평균화될 수 있습니다. 이러한 메트릭을 사용하는 플롯의 예제는 ROC 곡선 검사하기 항목과 정밀도-재현율 곡선 검사하기 항목을 참조하십시오.
추가적인 모델 메트릭
| 메트릭 | 설명 | 팁 |
|---|---|---|
| 정밀도 | 양성예측도. 양성으로 예측된 모든 결과 중 참양성인 결과의 비율을 의미합니다. | 더 높은 정밀도 값을 찾으십시오. 거짓양성 예측의 개수가 많을수록 모델의 정밀도가 낮아집니다. |
| 재현율 | 참양성률(민감도). 실제 참양성인 모든 결과 중 참양성으로 예측된 결과의 비율을 의미합니다. | 더 높은 재현율 값을 찾으십시오. 거짓음성 예측의 개수가 많을수록 모델의 재현율이 낮아집니다. |
| F1 점수 | 정밀도와 재현율의 조화 평균 | F1 점수가 높으려면 모델의 정밀도와 재현율이 둘 다 높아야 합니다. |
평균 유형
| 메트릭 | 설명 | 팁 |
|---|---|---|
| 매크로 평균 | 가중치 없이 클래스별 메트릭 값들의 평균을 구함 | 클래스 빈도에 상관없이 이 모델이 모든 클래스에서 평균적으로 성능이 어떠한지 평가하려면 이 통계량을 사용하십시오. |
| 마이크로 평균 | 모든 클래스에 대해 예측 값과 실제 값을 결합한 값을 사용해 계산되는 특정 메트릭의 평균 | 클래스에 상관없이 모든 예측을 동등하게 평가하려면 이 통계량을 사용하십시오. |
| 가중 평균 | 각 클래스의 발생 빈도에 따라 가중치를 적용하여 클래스별 메트릭 값들의 평균을 구함 | 모델 성능을 평가할 때 클래스 빈도의 큰 불균형을 고려하려면 이 통계량을 사용하십시오. |
모델 창에서 정확도, 총 비용, 오차율, 매크로 평균 정밀도, 매크로 평균 재현율 또는 매크로 평균 F1 점수에 따라 모델을 정렬할 수 있습니다. 모델 정렬을 위한 메트릭을 선택하려면 모델 창의 맨 위에 있는 정렬 기준 목록을 사용합니다. 일부 메트릭은 모델 창에서 정렬에 사용할 수 없습니다. 결과값 테이블에서 다른 메트릭을 기준으로 모델을 정렬할 수 있습니다(테이블 뷰에서 모델 정보와 결과 비교하기 항목 참조).
또한 모델 창에 나열된 모델을 삭제할 수 있습니다. 삭제할 모델을 선택하고 창의 오른쪽 위에 있는 선택한 모델을 삭제합니다 버튼을 클릭하거나 모델을 마우스 오른쪽 버튼으로 클릭하고 삭제를 선택합니다. 마지막 남은 모델은 모델 창에서 삭제할 수 없습니다.
테이블 뷰에서 모델 정보와 결과 비교하기
요약 탭이나 모델 창을 사용하여 모델 메트릭을 비교하는 대신 결과값 테이블을 사용할 수 있습니다. 학습 탭의 플롯 및 결과 섹션에서 결과값 테이블을 클릭합니다. 결과값 테이블에서 훈련 결과와 테스트 결과를 기준으로 모델을 정렬하는 것은 물론, 옵션(예: 모델 유형, 선택한 특징, PCA 등)을 기준으로 모델을 정렬할 수도 있습니다. 예를 들어, 검증 정확도를 기준으로 모델을 정렬하려면 정확도(검증) 열 헤더에서 정렬 화살표를 클릭합니다. 아래쪽 화살표는 모델이 가장 높은 정확도에서 가장 낮은 정확도 순으로 정렬됨을 나타냅니다.
테이블 열 옵션을 더 보려면 테이블의 오른쪽 위에 있는 "표시할 열 선택" 버튼  을 클릭합니다. "표시할 열 선택" 대화 상자에서 결과값 테이블에 표시할 열의 체크박스를 선택합니다. 새로 선택한 열은 오른쪽의 테이블에 추가됩니다.
을 클릭합니다. "표시할 열 선택" 대화 상자에서 결과값 테이블에 표시할 열의 체크박스를 선택합니다. 새로 선택한 열은 오른쪽의 테이블에 추가됩니다.

결과값 테이블 내에서 테이블 열이 원하는 순서로 나타나도록 수동으로 끌어서 놓을 수 있습니다.
즐겨찾기 열을 사용하여 일부 모델을 즐겨찾기로 표시할 수 있습니다. 즐겨찾기로 선택된 모델은 결과값 테이블과 모델 창에서 일관되게 유지됩니다. 다른 열과 달리 즐겨찾기 열과 모델 번호 열은 테이블에서 제거할 수 없습니다.
테이블에서 행을 제거하려면 행 내의 항목을 마우스 오른쪽 버튼으로 클릭하고 행 숨기기(또는 행이 강조 표시된 경우 선택한 행 숨기기)를 클릭합니다. 연속 행을 제거하려면 첫 번째 행 내의 항목을 클릭하고 Shift 키를 누른 다음 제거하려는 마지막 행 내의 항목을 클릭합니다. 그런 다음 강조 표시된 항목 중 하나를 마우스 오른쪽 버튼으로 클릭하고 선택한 행 숨기기를 클릭합니다. 제거된 모든 행을 복원하려면 테이블의 아무 항목이나 마우스 오른쪽 버튼으로 클릭하고 모든 행 표시를 클릭합니다. 복원된 행은 테이블 맨 아래에 추가됩니다.
테이블의 정보를 내보내려면 테이블의 오른쪽 위에 있는 내보내기 버튼  중 하나를 사용합니다. 테이블을 작업 공간으로 내보낼지 파일로 내보낼지 선택합니다. 내보낸 테이블에는 표시된 행과 열만 포함됩니다.
중 하나를 사용합니다. 테이블을 작업 공간으로 내보낼지 파일로 내보낼지 선택합니다. 내보낸 테이블에는 표시된 행과 열만 포함됩니다.
결과 비교 플롯에서 모델 정보와 결과 보기
결과 비교 플롯에서 모델 정보와 결과를 볼 수 있습니다. 학습 탭 또는 테스트 탭의 플롯 및 결과 섹션에서 결과 비교를 클릭합니다. 또는 결과값 테이블 탭에서 결과 플로팅 버튼을 클릭합니다. 플롯은 모델에 대한 검증 정확도를 가장 높은 정확도 값에서 가장 낮은 정확도 값 순서로 정렬한 막대 차트를 표시합니다. 데이터 정렬 아래에 있는 정렬 기준 목록을 사용하여 다른 훈련 결과와 테스트 결과를 기준으로 모델을 정렬할 수 있습니다. 동일한 유형의 모델을 그룹화하려면 모델 유형별로 그룹화를 선택합니다. 동일한 색을 모든 모델 유형에 할당하려면 모델 유형별로 채색을 선택 해제합니다.
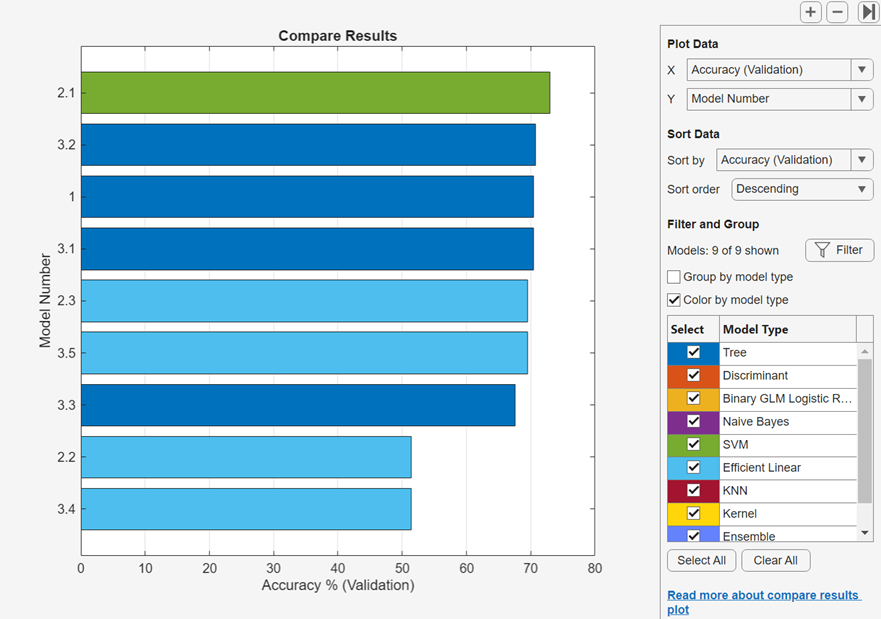
선택 아래에 있는 체크박스를 사용하여 표시할 모델 유형을 선택합니다. 플롯에서 막대를 마우스 오른쪽 버튼으로 클릭하고 모델 숨기기를 선택하여 표시된 모델을 숨깁니다.
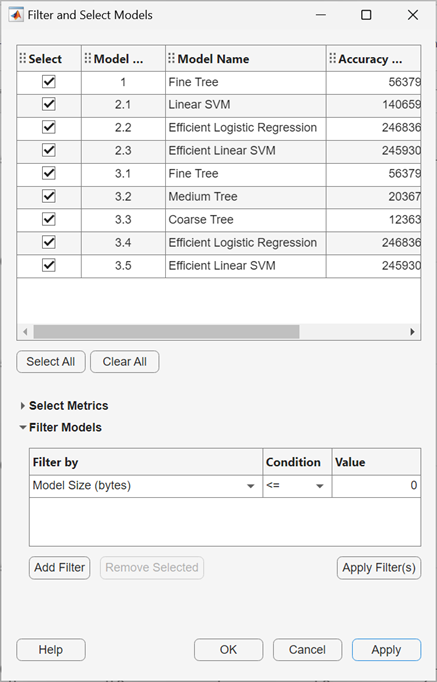
또한 필터링 및 그룹화 아래에 있는 필터 버튼을 클릭하여 표시되는 모델을 선택하고 필터링할 수 있습니다. 모델 필터링 및 선택 대화 상자에서 메트릭 선택을 클릭하고 이 대화 상자 상단의 모델 테이블에서 표시할 메트릭을 선택합니다. 이 테이블 내에서 테이블 열이 원하는 순서로 나타나도록 끌어서 놓을 수 있습니다. 테이블을 정렬하려면 테이블 헤더의 정렬 화살표를 클릭합니다. 메트릭 값을 기준으로 모델을 필터링하려면 먼저 필터링 기준 열에서 메트릭을 선택합니다. 그런 다음 모델 필터링 테이블에서 조건을 선택하고, 값 필드에 값을 입력하고, 필터 적용을 클릭합니다. 모델 테이블에서 선택 사항이 업데이트됩니다. 필터 추가 버튼을 클릭하여 추가 조건을 지정할 수 있습니다. 확인을 클릭하여 업데이트된 플롯을 표시합니다.
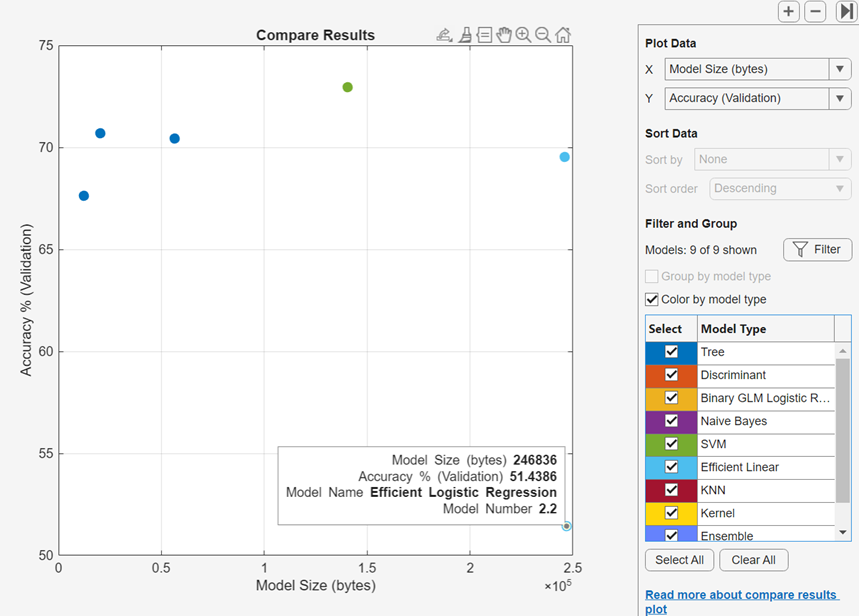
플로팅할 다른 메트릭을 데이터 플로팅 아래에 있는 X 목록과 Y 목록에서 선택합니다. X 또는 Y에 대해 Model Number를 선택하지 않으면 앱은 산점도 플롯을 표시합니다.
결과 비교 플롯을 Figure로 내보내려면 Export Plots in Classification Learner App 항목을 참조하십시오.
결과값 테이블을 작업 공간으로 내보내려면 플롯 내보내기를 클릭하고 플롯 데이터 내보내기를 선택합니다. 결과 메트릭 플롯 데이터 내보내기 대화 상자에서, 내보내는 변수의 이름을 편집하고(필요한 경우) 확인을 클릭합니다. 앱은 결과값 테이블을 포함하는 구조체형 배열을 생성합니다.
분류기 결과 플로팅하기
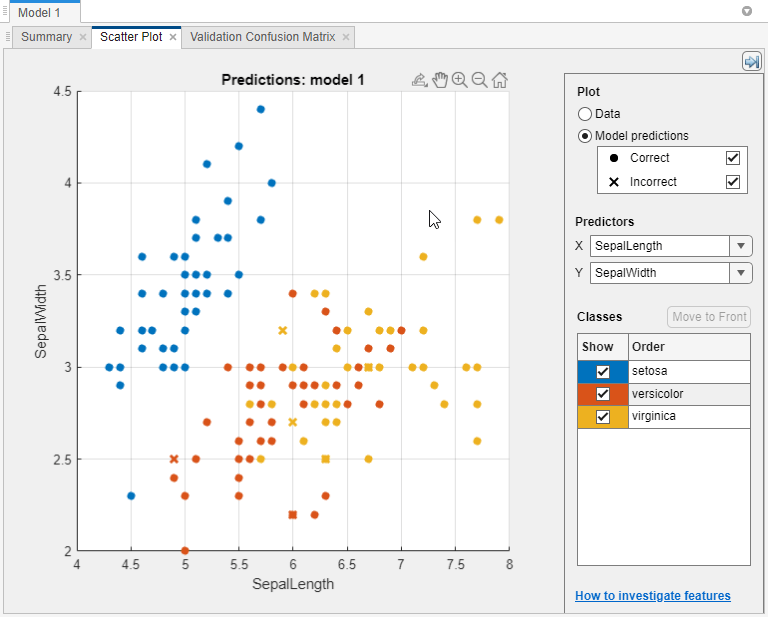
산점도 플롯을 사용하여 분류기 결과를 조사합니다. 모델의 산점도 플롯을 보려면 모델 창에서 모델을 선택합니다. 학습 탭의 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 산점도를 클릭합니다. 분류기를 훈련시킨 후에는 산점도 플롯이 데이터 표시에서 모델 예측 표시로 전환됩니다. 홀드아웃 검증이나 교차 검증을 사용하는 경우, 예측값은 홀드아웃(검증) 관측값에 대한 예측입니다. 즉, 소프트웨어는 해당 관측값을 제외하고 훈련된 모델을 사용하여 각 예측을 얻습니다.
결과를 살펴보려면 오른쪽 컨트롤을 사용합니다. 가능한 작업:
모델 예측값을 플로팅할지 데이터만 플로팅할지 선택합니다.
모델 예측 아래의 체크박스를 사용하여 올바른 결과 또는 잘못된 결과를 표시하거나 숨깁니다.
예측 변수의 X 목록과 Y 목록을 사용하여 플로팅할 특징을 선택합니다.
표시의 체크박스를 사용하여 특정 클래스를 표시하거나 숨겨 클래스별로 결과를 시각화합니다.
클래스에서 클래스를 선택한 다음 맨 앞으로 이동을 클릭하여 플로팅된 클래스의 쌓임 순서를 변경합니다.
플롯을 확대/축소하거나 패닝합니다. 확대/축소 또는 패닝을 활성화하려면 산점도 플롯 위에 마우스를 올려놓고 플롯의 오른쪽 상단 위에 나타나는 도구 모음에서 해당 버튼을 클릭합니다.
산점도 플롯에서 특징 조사하기 항목도 참조하십시오.
앱에서 만든 산점도 플롯을 Figure로 내보내려면 Export Plots in Classification Learner App 항목을 참조하십시오.
혼동행렬에서 클래스당 성능 검사하기
현재 선택한 분류기가 각 클래스에서 성능이 어땠는지 파악하려면 혼동행렬 플롯을 사용합니다. 분류 모델을 훈련시키고 나면 자동으로 해당 모델의 혼동행렬이 열립니다. "모두" 모델을 훈련시키는 경우 첫 번째 모델의 혼동행렬이 열립니다. 다른 모델의 혼동행렬을 보려면 모델 창에서 모델을 선택합니다. 학습 탭의 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 혼동행렬(검증)을 클릭합니다. 혼동행렬은 분류기의 성능이 좋지 않은 영역을 식별하는 데 도움이 됩니다.
플롯을 열면 행에는 실제 클래스가 표시되고 열에는 예측 클래스가 표시됩니다. 홀드아웃 검증 또는 교차 검증을 사용하는 경우 홀드아웃(검증) 관측값에 대한 예측값을 사용하여 혼동행렬이 계산됩니다. 대각선 셀은 실제 클래스와 예측 클래스가 일치하는 위치를 보여줍니다. 이러한 대각선 셀이 파란색인 경우 분류기가 이 실제 클래스의 관측값을 올바르게 분류한 것입니다.
디폴트 뷰에서는 각 셀에 관측값 개수가 표시됩니다.
분류기의 클래스당 성능이 어땠는지 보려면 플롯에서 참양성률(TPR), 거짓음성률(FNR) 옵션을 선택합니다. TPR은 실제 클래스당 올바르게 분류된 관측값의 비율입니다. FNR은 실제 클래스당 잘못 분류된 관측값의 비율입니다. 플롯의 오른쪽 마지막 2개 열에는 실제 클래스당 요약이 표시됩니다.
팁
백분율이 높고 주황색인 대각선에서 셀을 검사하여 분류기의 성능이 좋지 않은 영역을 찾습니다. 백분율이 높을수록 셀 색의 채도가 어두워집니다. 이러한 주황색 셀에서는 실제 클래스와 예측 클래스가 일치하지 않습니다. 데이터 점이 오분류되었습니다.
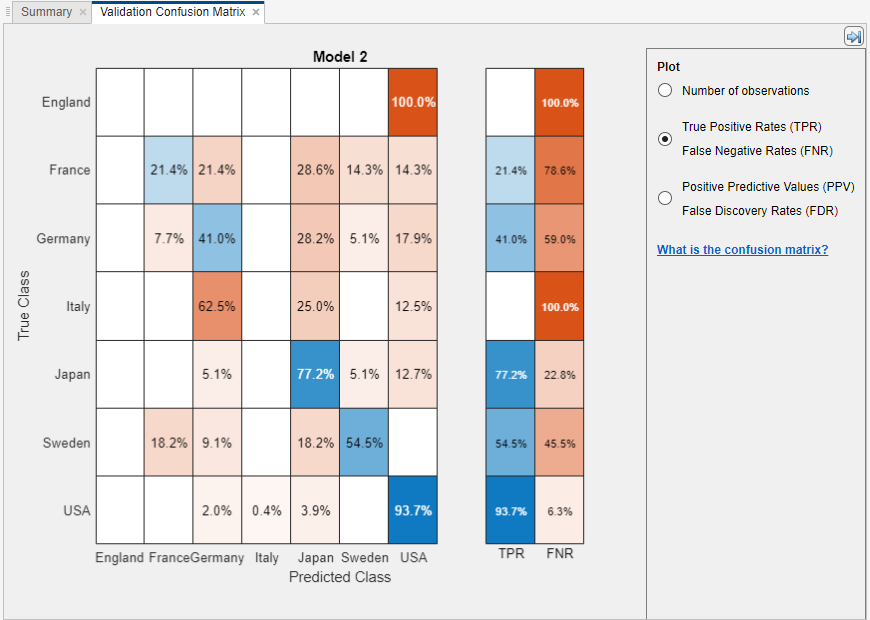
carbig 데이터 세트를 사용하는 이 예제에서는 위에서 다섯 번째 행에 실제 클래스가 Japan인 모든 자동차가 표시됩니다. 열에는 예측 클래스가 표시됩니다. 일본 자동차 중 77.2%는 올바르게 분류되었으므로 이 클래스에서 정확하게 분류된 점에 대한 참양성률은 77.2%이며, 이는 TPR 열에 파란색 셀로 표시되어 있습니다.
Japan 행에 있는 다른 자동차들은 오분류되었습니다. 5.1%는 독일 자동차, 5.1%는 스웨덴 자동차, 12.7%는 미국 자동차로 잘못 분류되었습니다. 이 클래스에서 잘못 분류된 점에 대한 거짓음성률은 22.8%이며, 이는 FNR 열에 주황색 셀로 표시되어 있습니다.
백분율 대신 관측값(이 예제의 경우 자동차) 개수를 보려면 플롯에서 관측값 개수를 선택합니다.
거짓양성이 분류 문제에서 중요한 경우, 오발견율을 조사하기 위해 실제 클래스 대신 예측 클래스당 결과를 플로팅합니다. 예측 클래스당 결과를 보려면 플롯에서 양성예측도(PPV), 오발견율(FDR) 옵션을 선택합니다. PPV는 예측 클래스당 올바르게 분류된 관측값의 비율입니다. FDR은 예측 클래스당 잘못 분류된 관측값의 비율입니다. 이 옵션을 선택하면 이제 혼동행렬에 요약 행이 포함되며 테이블 아래에 위치합니다. 각 클래스에서 올바르게 예측된 점에 대한 양성예측도는 파란색으로 표시되고 각 클래스에서 잘못 예측된 점에 대한 오발견율은 주황색으로 표시됩니다.
관심 클래스에 오분류된 점이 너무 많다고 판단되면 분류기 설정이나 특징 선택을 변경하여 더 나은 모델을 찾아보십시오.
앱에서 만든 혼동행렬 플롯을 Figure로 내보내려면 Export Plots in Classification Learner App 항목을 참조하십시오.
혼동행렬을 작업 공간으로 내보내려면 플롯 내보내기를 클릭하고 플롯 데이터 내보내기를 선택합니다. 혼동행렬 플롯 데이터 내보내기 대화 상자에서, 내보내는 변수의 이름을 편집하고(필요한 경우) 확인을 클릭합니다. 앱은 혼동행렬과 클래스 레이블을 포함하는 구조체형 배열을 생성합니다.
ROC 곡선 검사하기
모델을 훈련시킨 후 ROC(수신자 조작 특성) 곡선을 봅니다. 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 ROC 곡선(검증)을 클릭합니다. 앱은 rocmetrics 함수를 사용하여 ROC 곡선을 만듭니다.

ROC 곡선은 현재 선택된 분류기가 계산한 분류 점수의 서로 다른 임계값에 대한 참양성률(TPR) 대 거짓양성률(FPR)을 보여줍니다. 모델 동작점은 분류기가 관측값을 분류하는 데 사용한 임계값에 대응하는 거짓양성률과 참양성률을 보여줍니다. 예를 들어 거짓양성률이 0.1이면 분류기가 음성 클래스 관측값의 10%를 양성 클래스에 잘못 할당한다는 의미입니다. 참양성률이 0.85이면 분류기가 양성 클래스 관측값의 85%를 양성 클래스에 올바르게 할당한다는 의미입니다.
AUC(곡선 아래 영역) 값은 FPR = 0에서 FPR = 1 범위의 FPR에 대한 ROC 곡선(TPR 값)의 적분에 대응됩니다. AUC 값은 분류기의 전반적인 품질을 나타내는 척도입니다. AUC 값은 0에서 1 사이의 범위에 있으며, AUC 값이 클수록 분류기 성능이 우수함을 나타냅니다. 클래스와 훈련된 모델을 비교하여 ROC 곡선에서 서로 다른 성능을 보이는지 확인합니다.
클래스별 곡선 아래에 있는 표시 체크박스를 사용하여 특정 클래스의 ROC 곡선을 만들 수 있습니다. 그러나 이진 분류 문제에서는 두 클래스 모두의 ROC 곡선을 검사할 필요가 없습니다. 두 ROC 곡선은 대칭이고 AUC 값은 동일합니다. 한 클래스의 TPR은 다른 클래스의 참음성률(TNR)이며 TNR은 1 – FPR입니다. 따라서 한 클래스의 TPR 대 FPR에 대한 플롯은 다른 클래스의 1 – FPR 대 1 – TPR에 대한 플롯과 동일합니다.
다중클래스 분류기의 경우, 앱은 각 클래스에 대해 하나의 이진 문제를 갖도록 일대다(OVA) 이진 분류 문제 세트를 정식화하고, 대응하는 이진 문제를 사용하여 각 클래스에 대한 ROC 곡선을 구합니다. 각 이진 문제는 한 클래스가 양성이고 나머지는 음성이라고 가정합니다. 플롯의 모델 동작점은 일대다(OVA) 이진 문제에서 각 클래스에 대한 분류기의 성능을 보여줍니다.
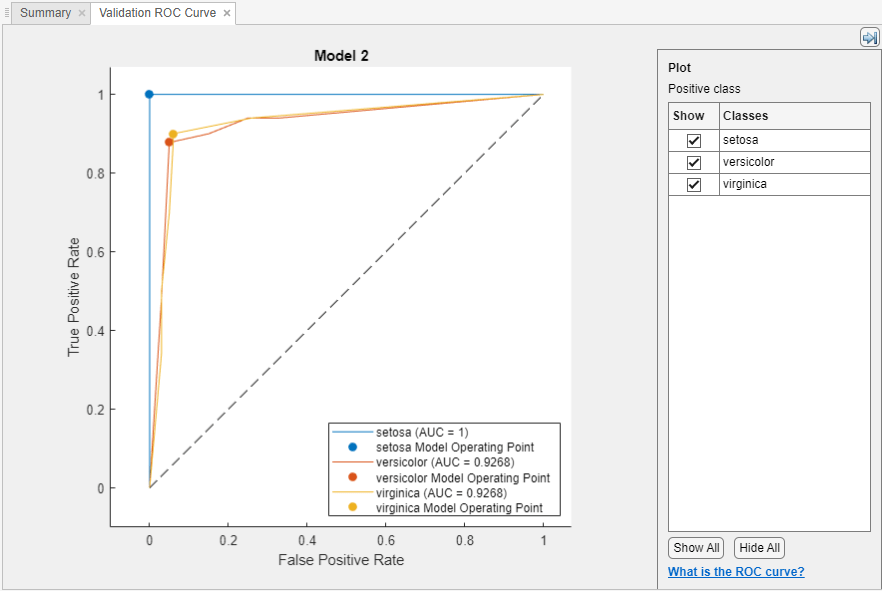
또한 평균 곡선 아래에 있는 표시 체크박스를 사용하여 평균 ROC 곡선을 플로팅할 수 있습니다. 평균 유형에 대한 설명은 요약 탭과 모델 창에서 모델 메트릭 보기 항목을 참조하십시오.
ROC 곡선 비교 플롯을 생성하여 최대 4개의 훈련된 모델에 대한 ROC 곡선을 한 플롯에 표시할 수 있습니다. 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 모델 결과 비교 그룹에서 ROC 곡선 비교를 클릭합니다. 플롯 오른쪽의 모델 아래에서 표시할 모델을 선택합니다. 선택한 각 모델은 플롯에서 선 스타일이 서로 다릅니다.
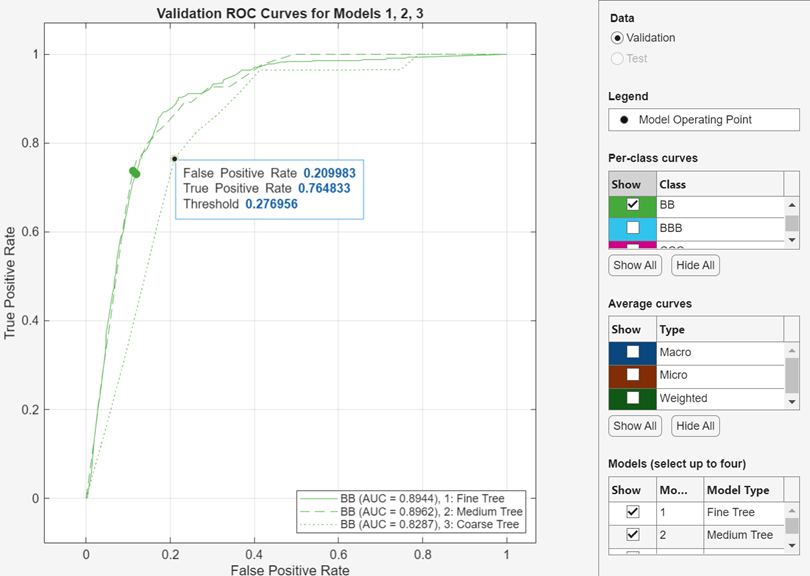
ROC 곡선에 대한 자세한 내용은 rocmetrics와 ROC Curve and Performance Metrics 항목을 참조하십시오.
앱에서 만든 ROC 곡선 플롯을 Figure로 내보내려면 Export Plots in Classification Learner App 항목을 참조하십시오.
ROC 곡선 결과를 작업 공간으로 내보내려면 플롯 내보내기를 클릭하고 플롯 데이터 내보내기를 선택합니다. ROC 곡선 플롯 데이터 내보내기 대화 상자에서, 내보내는 변수의 이름을 편집하고(필요한 경우) 확인을 클릭합니다. 앱은 rocmetrics 객체를 포함하는 구조체형 배열을 생성합니다.
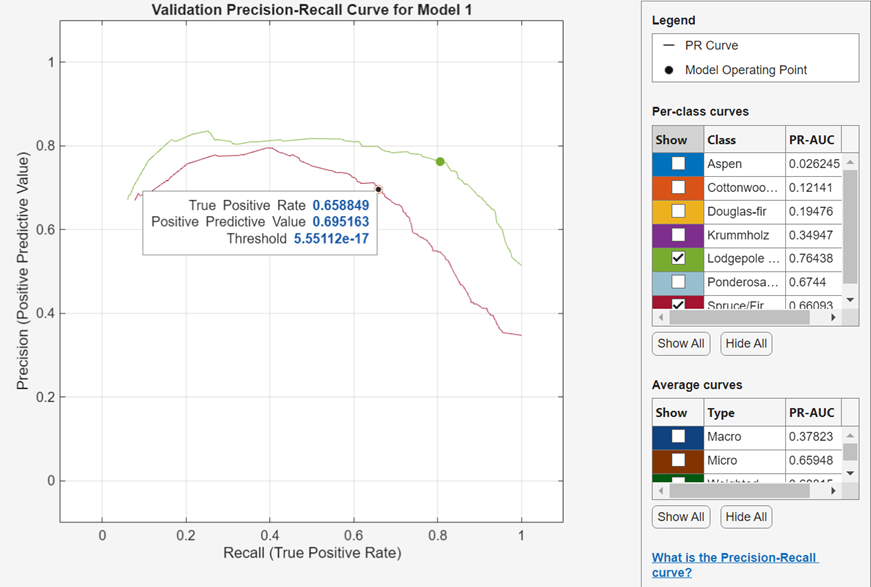
정밀도-재현율 곡선 검사하기
모델을 훈련시킨 후 정밀도-재현율 곡선을 봅니다. 플롯 및 결과 섹션에서 화살표를 클릭하여 갤러리를 연 다음 검증 결과 그룹에서 정밀도-재현율 곡선(검증)을 클릭합니다. 앱은 rocmetrics 함수를 사용하여 정밀도-재현율 곡선을 생성합니다.
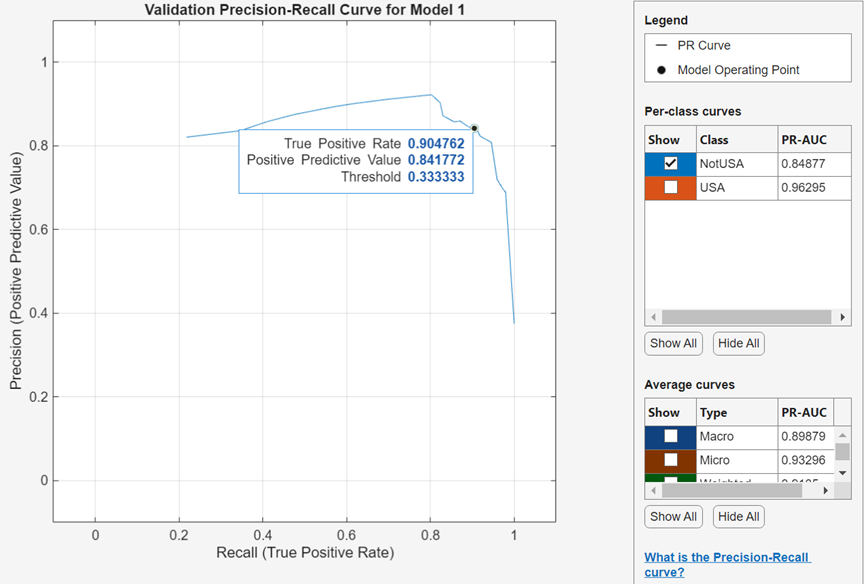
정밀도-재현율 곡선은 현재 선택된 분류기가 계산한 분류 점수의 서로 다른 임계값에 대한 양성예측도(정밀도) 대 참양성률(재현율)을 보여줍니다. 모델 동작점은 분류기가 관측값을 분류하는 데 사용한 임계값에 대응하는 정밀도와 참양성률(TPR)을 보여줍니다. 예를 들어 정밀도가 0.85이면 양성으로 할당된 관측값의 85%가 참양성이라는 의미입니다. 참양성률이 0.85이면 분류기가 양성 클래스 관측값의 85%를 양성 클래스에 올바르게 할당한다는 의미입니다.
PR-AUC(곡선 아래 면적) 값은 분류기의 전반적인 품질을 나타내는 척도입니다. PR-AUC 값은 범위 0~1 내에 있으며 PR-AUC 값이 높을수록 일반적으로 높은 정밀도와 높은 재현율을 나타냅니다(auc 항목 참조). 클래스와 훈련된 모델을 비교하여 정밀도-재현율 곡선에서 서로 다른 성능을 보이는지 확인합니다.
클래스별 곡선 아래에 있는 표시 체크박스를 사용하여 특정 클래스의 정밀도-재현율 곡선을 만들 수 있습니다. 다중클래스 분류기의 경우, 앱은 각 클래스에 대해 하나의 이진 문제를 갖도록 일대다(OVA) 이진 분류 문제 세트를 정식화하고, 대응하는 이진 문제를 사용하여 각 클래스에 대한 정밀도-재현율 곡선을 구합니다. 각 이진 문제는 한 클래스가 양성이고 나머지는 음성이라고 가정합니다. 플롯의 모델 동작점은 일대다(OVA) 이진 문제에서 각 클래스에 대한 분류기의 성능을 보여줍니다.
또한 평균 곡선 아래에 있는 표시 체크박스를 사용하여 평균 정밀도-재현율 곡선을 플로팅할 수 있습니다. 평균 유형에 대한 설명은 요약 탭과 모델 창에서 모델 메트릭 보기 항목을 참조하십시오.
정밀도-재현율 곡선 플롯을 Figure로 내보내려면 Export Plots in Classification Learner App 항목을 참조하십시오.
정밀도-재현율 곡선 결과를 작업 공간으로 내보내려면 플롯 내보내기를 클릭하고 플롯 데이터 내보내기를 선택합니다. 정밀도-재현율 곡선 플롯 데이터 내보내기 대화 상자에서, 내보내는 변수의 이름을 편집하고(필요한 경우) 확인을 클릭합니다. 앱은 rocmetrics 객체를 포함하는 구조체형 배열을 생성합니다.
레이아웃을 변경하여 모델 플롯 비교하기
학습 탭의 플롯 및 결과 섹션에서 플롯 옵션을 사용하여 분류 학습기에서 훈련된 모델의 결과를 시각화합니다. 플롯의 레이아웃을 재배열하여 여러 모델 간에 결과를 비교할 수 있습니다. 레이아웃 버튼을 클릭하면 나타나는 옵션을 사용하거나 플롯을 끌어서 놓거나 모델 플롯 탭의 오른쪽에 있는 문서 동작 버튼  을 클릭하면 제공되는 옵션을 선택합니다.
을 클릭하면 제공되는 옵션을 선택합니다.
예를 들어 분류 학습기에서 두 모델을 훈련시킨 후 각 모델에 대한 플롯을 표시하고, 다음 절차 중 하나를 사용하여 플롯을 비교할 수 있도록 플롯 레이아웃을 변경합니다.
플롯 및 결과 섹션에서 레이아웃을 클릭하고 모델 비교를 선택합니다.
두 번째 모델 탭 이름을 클릭한 다음 두 번째 모델 탭을 오른쪽으로 끌어서 놓습니다.
모델 플롯 탭의 오른쪽 끝에 있는 문서 동작 버튼
을 클릭합니다. 모두 타일 형식으로 배열옵션을 선택하고 1×2 레이아웃을 지정합니다.
참고로 플롯 오른쪽 위에 있는 "플롯 옵션을 숨깁니다" 버튼  을 클릭하여 플롯을 위한 더 많은 공간을 만들 수 있습니다.
을 클릭하여 플롯을 위한 더 많은 공간을 만들 수 있습니다.
테스트 데이터 세트를 사용하여 모델 성능 평가하기
분류 학습기에서 모델을 훈련시킨 후 앱의 테스트 데이터 세트에서 모델 성능을 평가할 수 있습니다. 자세한 내용은 Test Trained Models in Classification Learner or Regression Learner 항목을 참조하십시오.
참고 항목
도움말 항목
- Start a Classification Learner or Regression Learner Session
- 분류 학습기 앱에서 분류 모델을 훈련시키기
- Choose Classifier Options in Classification Learner
- 분류 학습기 앱을 사용한 특징 선택 및 특징 변환
- Export Plots in Classification Learner App
- Export Classification Model to Predict New Data
- Train Decision Trees Using Classification Learner App