Divide
하나의 입력을 다른 입력으로 나누기
라이브러리:
Simulink /
Math Operations
HDL Coder /
HDL Floating Point Operations
HDL Coder /
Math Operations
설명
Divide 블록은 첫 번째 입력을 두 번째 입력으로 나눈 결과를 출력합니다. 입력은 두 스칼라, 스칼라와 비 스칼라, 또는 차원이 동일한 두 비 스칼라일 수 있습니다. 이 블록은 모든 포트가 동일한 single형 또는 double형을 가질 경우 나눗셈 포트에서 복소 입력값만 지원합니다.
Divide 블록은 기능적으로 다음과 같이 두 블록 파라미터 값이 사전 설정된 Product 블록과 동일합니다.
곱셈 —
요소별(.*)입력 개수 —
*/
이 두 파라미터 중 하나라도 디폴트 값이 아닌 값을 설정하면, Divide 블록은 기능적으로 Product 블록 또는 Product of Elements 블록과 동일해질 수 있습니다.
예제
이 예제에서는 Divide 블록을 사용하여 두 입력의 요소별 (.*) 나눗셈을 수행하는 방법을 보여줍니다. 이 예제에서 Divide 블록은 두 스칼라끼리 나누기, 벡터를 스칼라로 나누기, 스칼라를 벡터로 나누기, 두 행렬끼리 나누기를 수행합니다.
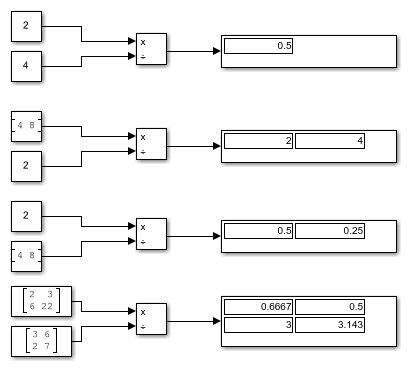
포트
입력
출력
파라미터
기본
블록의 두 가지 속성을 제어합니다.
블록의 입력 포트 개수
각 입력이 출력으로 곱해지는지 나뉘는지 여부
다음을 지정합니다.
1또는*또는/블록은 하나의 입력 포트를 갖습니다. 요소별 모드에서는 블록이 Product of Elements 블록에 설명된 대로 입력을 처리합니다. 행렬 모드에서는 파라미터 값이
1또는*인 경우 블록이 입력 값을 출력합니다. 값이/인 경우 입력은 정사각 행렬(퇴화된 유형으로서 스칼라도 포함)이어야 하며, 블록은 행렬의 역행렬을 출력합니다. 자세한 내용은 요소별 모드 항목과 행렬 모드 항목을 참조하십시오.1보다 큰 정수 값
블록은 정수 값으로 지정된 입력 개수를 갖습니다. 입력은 요소별 모드 또는 행렬 모드로 곱해지며, 이는 곱셈 파라미터로 지정됩니다. 자세한 내용은 요소별 모드 항목과 행렬 모드 항목을 참조하십시오.
따옴표로 묶이지 않은 두 개 이상의
*와/문자로 구성된 문자열블록은 문자형 벡터의 길이로 지정된 입력 개수를 갖습니다.
*문자에 해당하는 각 입력이 출력에 곱해집니다./문자에 해당하는 각 입력이 출력을 나눕니다. 연산은 요소별 모드 또는 행렬 모드로 곱해지며, 이는 곱셈 파라미터로 지정됩니다. 자세한 내용은 요소별 모드 항목과 행렬 모드 항목을 참조하십시오.
프로그래밍 방식의 사용법
블록 파라미터: Inputs |
| 유형: 문자형 벡터 |
값: '2' | '*' | '**' | '*/' | '*/*' | ... |
디폴트 값: '*/' |
블록이 요소별(.*) 곱셈을 수행할지 아니면 행렬(*) 곱셈을 수행할지 지정합니다.
프로그래밍 방식의 사용법
블록 파라미터: Multiplication |
| 유형: 문자형 벡터 |
값: 'Element-wise(.*)' | 'Matrix(*)' |
디폴트 값: 'Element-wise(.*)' |
지정된 차원을 따라 함수를 적용하는 방법을 지정합니다.
모든 차원— 모든 차원의 모든 입력값에 함수를 적용합니다.지정된 차원— 지정된 차원의 모든 입력값에 함수를 적용합니다.
예를 들어, 이 모델에서 곱셈은 요소별(.*)로 설정되고 적용 범위는 모든 차원으로 설정되어 있다고 가정하겠습니다. 블록은 모든 차원의 모든 값의 곱을 반환합니다.
![2D matrix with Constant block value [1 2 3;7 6 4] as input to Product block configured for all dimensions](prod_alldim.png)
종속성
이 파라미터를 활성화하려면 입력 개수를 *로 설정하고 곱셈을 요소별(.*)로 설정하십시오.
프로그래밍 방식의 사용법
블록 파라미터: CollapseMode |
| 유형: 문자형 벡터 |
값: 'All dimensions' | 'Specified dimension' |
디폴트 값: 'All dimensions' |
곱셈을 적용할 차원으로, 양의 정수로 지정합니다. 예를 들어, 2차원 행렬의 경우 1은 각 열에 함수를 적용하고 2는 각 행에 함수를 적용합니다.
예를 들어, 이 모델에서 곱셈은 요소별(.*)로 설정되고 적용 범위는 지정된 차원으로 설정되며 차원은 2로 설정되어 있다고 가정하겠습니다. 블록은 각 행의 모든 값의 곱을 반환합니다.
![2D matrix with Constant block value [1 2 3;7 6 4] as input to Product block configured for dimension 2](prod_2dim.png)
종속성
이 파라미터를 활성화하려면 다음을 수행하십시오.
입력 개수를
*로 설정합니다.곱셈을
요소별(.*)로 설정합니다.적용 범위를
지정된 차원으로 설정합니다.
프로그래밍 방식의 사용법
블록 파라미터: CollapseDim |
| 유형: 문자형 벡터 |
값: '1' | '2' | ... |
디폴트 값: '1' |
샘플 간의 시간 간격을 지정합니다. 샘플 시간을 상속하려면 이 파라미터를 -1로 설정하십시오. 자세한 내용은 샘플 시간 지정하기 항목을 참조하십시오.
종속성
이 파라미터는 -1 이외의 값으로 설정한 경우에만 표시됩니다. 자세한 내용은 Blocks for Which Sample Time Is Not Recommended 항목을 참조하십시오.
프로그래밍 방식의 사용법
프로그래밍 방식으로 블록 파라미터 값을 설정하려면 set_param 함수를 사용하십시오.
| 파라미터: | SampleTime |
| 값: | "-1" (디폴트 값) | scalar or vector in quotes |
신호 특성
입력 신호의 데이터형이 모두 동일해야 하는지 여부를 지정합니다. 이 파라미터를 활성화할 경우 입력 신호 유형이 다르면 시뮬레이션 중에 오류가 발생합니다.
프로그래밍 방식의 사용법
블록 파라미터: InputSameDT |
| 유형: 문자형 벡터 |
값: 'off' | 'on' |
디폴트 값: 'off' |
소프트웨어에서 검사하는 출력 범위의 하한 값입니다.
이 최솟값을 사용하여 다음 작업이 수행됩니다.
일부 블록에 대해 파라미터 범위 검사(Specify Minimum and Maximum Values for Block Parameters 참조).
시뮬레이션 범위 검사(Specify Signal Ranges 및 Enable Simulation Range Checking 참조).
고정소수점 데이터형의 자동 스케일링.
모델에서 생성한 코드 최적화. 이 최적화 작업은 알고리즘의 코드를 제거하고, SIL 또는 외부 모드 같은 일부 시뮬레이션 모드의 결과에 영향을 줄 수 있습니다. 자세한 내용은 Optimize using the specified minimum and maximum values (Embedded Coder) 항목을 참조하십시오.
팁
출력 최솟값은 실제 출력 신호를 포화시키거나 자르지 않습니다. 대신 Saturation 블록을 사용하십시오.
프로그래밍 방식의 사용법
프로그래밍 방식으로 블록 파라미터 값을 설정하려면 set_param 함수를 사용하십시오.
| 파라미터: | OutMin |
| 값: | '[]' (디폴트 값) | scalar in quotes |
소프트웨어에서 검사하는 출력 범위의 상한 값입니다.
이 최댓값을 사용하여 다음 작업이 수행됩니다.
일부 블록에 대해 파라미터 범위 검사(Specify Minimum and Maximum Values for Block Parameters 참조).
시뮬레이션 범위 검사(Specify Signal Ranges 및 Enable Simulation Range Checking 참조).
고정소수점 데이터형의 자동 스케일링.
모델에서 생성한 코드 최적화. 이 최적화 작업은 알고리즘의 코드를 제거하고, SIL 또는 외부 모드 같은 일부 시뮬레이션 모드의 결과에 영향을 줄 수 있습니다. 자세한 내용은 Optimize using the specified minimum and maximum values (Embedded Coder) 항목을 참조하십시오.
팁
출력 최댓값은 실제 출력 신호를 포화시키거나 자르지 않습니다. 대신 Saturation 블록을 사용하십시오.
프로그래밍 방식의 사용법
프로그래밍 방식으로 블록 파라미터 값을 설정하려면 set_param 함수를 사용하십시오.
| 파라미터: | OutMax |
| 값: | '[]' (디폴트 값) | scalar in quotes |
출력의 데이터형을 선택합니다. 유형은 상속되거나 직접 지정되거나 Simulink.NumericType과 같은 데이터형 객체로 표현될 수 있습니다. 자세한 내용은 Control Data Types of Signals 항목을 참조하십시오.
상속된 옵션을 선택하면 블록은 다음과 같이 동작합니다.
상속: 내부 규칙을 통해 상속— Simulink®가 임베디드 타깃 하드웨어의 속성을 고려하면서도 수치적 정확도와 성능, 생성된 코드 크기 간에 균형을 이루도록 데이터형을 선택합니다. 임베디드 타깃 설정을 변경할 경우 내부 규칙을 통해 선택된 데이터형이 변경될 수 있습니다. 예를 들어 블록이int8형의 입력을int16형의 이득에 곱하고ASIC/FPGA가 타깃 하드웨어 유형으로 지정된 경우 출력 데이터형은sfix24입니다.지정되지 않음(32비트 일반으로 간주됨), 즉 일반 32비트 마이크로프로세서가 타깃 하드웨어로 지정된 경우 출력 데이터형은int32입니다. 타깃 마이크로프로세서에서 제공된 어떤 워드 길이로도 출력 범위를 수용할 수 없는 경우 Simulink는 진단 뷰어에 오류를 표시합니다.항상 코드 효율성과 수치적 정확도를 동시에 최적화할 수 있는 것은 아닙니다. 내부 규칙이 수치적 정확도 또는 성능의 특정 요건에 부합되지 않으면 다음 옵션 중 하나를 사용하십시오.
명시적으로 출력 데이터형을 지정합니다.
상속: 입력과 동일을 간단히 선택합니다.명시적으로
fixdt(1,32,16)같은 디폴트 데이터형을 지정한 다음, 모델의 데이터형을 제안하는 고정소수점 툴을 사용합니다. 자세한 내용은fxptdlg(Fixed-Point Designer) 항목을 참조하십시오.고유한 상속 규칙을 지정하려면
상속: 역전파를 통해 상속을 사용한 후 Data Type Propagation 블록을 사용합니다. 이 블록의 사용 방법에 대한 예는 Signal Attributes 라이브러리의 Data Type Propagation Examples 블록에서 볼 수 있습니다.
상속: 역전파를 통해 상속— 구동 블록의 데이터형을 사용합니다.상속: 첫 번째 입력과 동일— 첫 번째 입력 신호의 데이터형을 사용합니다.
종속성
입력값이 단정밀도보다 작은 부동소수점 데이터형인 경우 상속: 내부 규칙을 통해 상속 출력 데이터형은 Inherit floating-point output type smaller than single precision 구성 파라미터의 설정에 따라 다릅니다. 데이터형을 인코딩하는 데 필요한 비트 수가 단정밀도 데이터형을 인코딩하는 데 필요한 32비트보다 작으면 데이터형은 단정밀도보다 작습니다. 예를 들어, half형과 int16형은 단정밀도보다 작습니다.
프로그래밍 방식의 사용법
블록 파라미터: OutDataTypeStr |
| 유형: 문자형 벡터 |
값: 'Inherit: Inherit via internal rule | 'Inherit: Same as first input' | 'Inherit: Inherit via back propagation' | 'double' | 'single' | 'int8' | 'uint8' | 'int16' | 'uint16' | 'int32' | 'uint32' | 'int64' | 'uint64' | 'fixdt(1,16)' | 'fixdt(1,16,0)' | 'fixdt(1,16,2^0,0)' | '<data type expression>' |
디폴트 값: 'Inherit: Inherit via internal rule' |
블록에 지정한 출력 데이터형이 고정소수점 툴에 의해 재정의되지 않도록 방지하려면 이 파라미터를 선택합니다. 자세한 내용은 Use Lock Output Data Type Setting (Fixed-Point Designer) 항목을 참조하십시오.
프로그래밍 방식의 사용법
프로그래밍 방식으로 블록 파라미터 값을 설정하려면 set_param 함수를 사용하십시오.
| 파라미터: | LockScale |
| 값: | 'off' (디폴트 값) | 'on' |
고정소수점 연산의 반올림 모드를 선택합니다. 선택 가능한 옵션은 다음과 같습니다.
올림(Ceiling)양수와 음수를 양의 무한대 방향으로 올림합니다. MATLAB®
ceil함수와 동일합니다.수렴(Convergent)숫자를 표현 가능한 가장 가까운 값으로 반올림합니다. 반올림 경계에 놓인 숫자인 경우 가장 가까운 짝수로 반올림합니다. Fixed-Point Designer™
convergent함수와 동일합니다.내림(Floor)양수와 음수를 음의 무한대 방향으로 내림합니다. MATLAB
floor함수와 동일합니다.최근접(Nearest)숫자를 표현 가능한 가장 가까운 값으로 반올림합니다. 반올림 경계에 놓인 숫자인 경우 양의 무한대 방향으로 올림합니다. Fixed-Point Designer
nearest함수와 동일합니다.반올림(Round)숫자를 표현 가능한 가장 가까운 값으로 반올림합니다. 반올림 경계에 놓인 숫자인 경우 양수는 양의 무한대 방향으로 올림하고 음수는 음의 무한대 방향으로 내림합니다. Fixed-Point Designer
round함수와 동일합니다.최대단순(Simplest)가능한 한 가장 효율적인 반올림 코드를 생성하기 위해 내림과 0 방향으로의 올림/내림 중에서 선택합니다. 이 반올림 모드는 하드웨어 구현 창에 있는 다음 구성 파라미터로부터 영향을 받습니다.
부호 있는 정수 나눗셈의 반올림 방식 파라미터가
0 방향(Zero)또는정의되지 않음으로 설정된 경우최대단순(Simplest)은 0으로 결정됩니다.부호 있는 정수 나눗셈의 반올림 방식 파라미터가
내림(Floor)으로 설정된 경우최대단순(Simplest)은floor방식으로 결정됩니다.
0 방향(Zero)숫자를 0 방향으로 반올림합니다. MATLAB
fix함수와 동일합니다.
자세한 내용은 반올림 모드 (Fixed-Point Designer) 항목을 참조하십시오.
블록 파라미터는 표현 가능한 가장 가까운 값으로 항상 반올림됩니다. 블록 파라미터의 반올림 동작을 제어하려면 마스크 필드에 MATLAB 반올림 함수를 사용하여 표현식을 입력하십시오.
프로그래밍 방식의 사용법
블록 파라미터: RndMeth |
| 유형: 문자형 벡터 |
값: 'Ceiling' | 'Convergent' | 'Floor' | 'Nearest' | 'Round' | 'Simplest' | 'Zero' |
디폴트 값: 'Floor' |
오버플로 시 포화시킬지 아니면 래핑할지를 지정합니다.
on— 오버플로 시 데이터형이 표현할 수 있는 최솟값 또는 최댓값으로 포화됩니다.off— 오버플로 시 데이터형이 표현할 수 있는 적절한 값으로 래핑됩니다.
예를 들어, 부호 있는 8비트 정수 int8이 표현할 수 있는 최댓값은 127입니다. 블록 연산 결과가 이 최댓값보다 크면 8비트 정수 오버플로가 발생합니다.
이 파라미터를 선택하면 블록 출력이 127에서 포화됩니다. 마찬가지로 블록 출력은 최소 출력값 -128에서 포화됩니다.
이 파라미터를 선택 해제하면 오버플로를 일으키는 값이
int8형으로 해석되어 의도치 않은 결과가 발생할 수 있습니다. 예를 들어,int8형으로 표현된 130(2진수 1000 0010)의 블록 결과는 -126입니다.
팁
모델에 오버플로가 발생할 가능성이 있고 생성된 코드에서 포화 보호를 명시적으로 지정하려는 경우 이 파라미터를 선택해 보십시오.
생성된 코드의 효율성을 최적화하려면 이 파라미터를 선택 해제하는 것이 좋습니다. 이 파라미터를 선택 해제하면 블록이 범위를 벗어난 신호를 처리하는 방법을 과도하게 지정하는 일이 방지됩니다. 자세한 내용은 Troubleshoot Signal Range Errors 항목을 참조하십시오.
이 파라미터를 선택하는 경우 출력이나 결과뿐만 아니라 블록의 모든 내부 연산에 포화가 적용됩니다.
일반적으로 코드 생성 프로세스는 오버플로가 발생할 가능성이 없는 경우를 감지할 수 있습니다. 이 경우, 코드 생성기는 포화 코드를 생성하지 않습니다.
프로그래밍 방식의 사용법
프로그래밍 방식으로 블록 파라미터 값을 설정하려면 set_param 함수를 사용하십시오.
| 파라미터: | SaturateOnIntegerOverflow |
| 값: | 'off' (디폴트 값) | 'on' |
지정할 데이터 범주를 선택합니다.
상속— 데이터형에 대한 상속 규칙.Inherit을 선택하면 오른쪽에 있는 두 번째 메뉴/텍스트 상자가 활성화되며, 여기서 상속 모드를 선택할 수 있습니다.내장— 내장 데이터형.Built in을 선택하면 오른쪽에 있는 두 번째 메뉴/텍스트 상자가 활성화되며, 여기서 내장 데이터형을 선택할 수 있습니다.고정소수점— 고정소수점 데이터형.고정소수점을 선택하면 고정소수점 데이터형을 지정하는 데 사용할 수 있는 추가 파라미터가 활성화됩니다.표현식— 데이터형으로 평가되는 표현식.Expression을 선택하면 오른쪽에 있는 두 번째 메뉴/텍스트 상자가 활성화되며, 여기에 표현식을 입력할 수 있습니다.
자세한 내용은 Specify Data Types Using Data Type Assistant 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 데이터형 도우미를 표시합니다 버튼을 클릭하십시오.
이 신호에 맞는 데이터형 재정의 모드를 선택합니다.
상속을 선택하면 Simulink는 컨텍스트, 즉 신호를 사용하는 Simulink의 블록,Simulink.Signal객체 또는 Stateflow® 차트에서 데이터형 재정의 설정을 상속합니다.끄기를 선택하면 Simulink는 컨텍스트의 데이터형 재정의 설정을 무시하고 신호에 대해 지정된 고정소수점 데이터형을 사용합니다.
자세한 내용은 Simulink 문서의 Specify Data Types Using Data Type Assistant 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 모드를 내장 또는 고정소수점으로 설정하십시오.
팁
사용자가 데이터형 재정의를 적용할 때 개별 데이터형에 대해 데이터형 재정의를 끄면 그 설정이 모델에 대한 데이터형보다 우선시 됩니다. 예를 들어, 이 옵션을 사용하여 데이터형이 데이터형 재정의 설정과 관계없이 다운스트림 블록의 요구 사항을 충족하는지 확인할 수 있습니다.
고정소수점 데이터가 부호 있는 데이터인지 또는 부호 없는 데이터인지를 지정합니다. 부호 있는 데이터는 양수 값과 음수 값을 표현할 수 있지만, 부호 없는 데이터는 양수 값만 표현합니다.
부호 있음- 고정소수점 데이터를 부호 있음으로 지정합니다.부호 없음- 고정소수점 데이터를 부호 없음으로 지정합니다.
자세한 내용은 Specify Data Types Using Data Type Assistant 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 모드를 Fixed point로 설정하십시오.
양자화된 정수를 저장하는 워드의 비트 크기를 지정합니다. 자세한 내용은 Specifying a Fixed-Point Data Type 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 모드를 고정소수점으로 설정하십시오.
고정소수점 데이터형의 소수부 길이를 양의 정수 또는 음의 정수로 지정합니다. 자세한 내용은 Specifying a Fixed-Point Data Type 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 스케일링을 이진 소수점으로 설정하십시오.
고정소수점 데이터 스케일링 방법을 지정하면 오버플로 조건이 발생하지 않도록 방지하고 양자화 오차를 최소화할 수 있습니다. 자세한 내용은 Specifying a Fixed-Point Data Type 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 모드를 고정소수점으로 설정하십시오.
고정소수점 데이터형의 기울기를 지정합니다. 자세한 내용은 Specifying a Fixed-Point Data Type 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 스케일링을 기울기 및 편향으로 설정하십시오.
고정소수점 데이터형의 편향을 임의의 실수로 지정합니다. 자세한 내용은 Specifying a Fixed-Point Data Type 항목을 참조하십시오.
종속성
이 파라미터를 활성화하려면 스케일링을 기울기 및 편향으로 설정하십시오.
블록 특성
데이터형 |
|
직접 피드스루 |
|
다차원 신호 |
|
가변 크기 신호 |
|
영점교차 검출 |
|