이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
경로 추종 컨트롤을 위해 DDPG 에이전트 훈련시키기
이 예제에서는 Simulink®에서 DDPG(심층 결정적 정책 경사법) 에이전트에게 PFC(경로 추종 컨트롤)를 훈련시키는 방법을 보여줍니다. DDPG 에이전트에 대한 자세한 내용은 DDPG(심층 결정적 정책 경사) 에이전트 항목을 참조하십시오.
Simulink 모델
이 예제의 강화 학습 환경은 선행 차량에 대한 간단한 종방향 모델과 함께 자기 차량에 대한 간단한 자전거 모델로 구성됩니다. 훈련 목표는 자기 차량이 종방향으로의 가속과 제동을 제어하여 선행 차량과의 안전 거리를 유지하면서 설정 속도로 주행하도록 하는 것과 동시에 앞쪽 조향각을 조정하여 자기 차량이 차선의 중심선을 따라 주행하도록 하는 것입니다. PFC에 대한 자세한 내용은 Path Following Control System (Model Predictive Control Toolbox) 항목을 참조하십시오. 자기 차량 동특성은 다음 파라미터로 지정됩니다.
m = 1600; % total vehicle mass (kg) Iz = 2875; % yaw moment of inertia (mNs^2) lf = 1.4; % long. distance from center of gravity to front tires (m) lr = 1.6; % long. distance from center of gravity to rear tires (m) Cf = 19000; % cornering stiffness of front tires (N/rad) Cr = 33000; % cornering stiffness of rear tires (N/rad) tau = 0.5; % longitudinal time constant
두 차량의 초기 위치와 속도를 지정합니다.
x0_lead = 50; % initial position for lead car (m) v0_lead = 24; % initial velocity for lead car (m/s) x0_ego = 10; % initial position for ego car (m) v0_ego = 18; % initial velocity for ego car (m/s)
정지 상태의 디폴트 간격(m), 시간차(s) 및 운전자 설정 속도(m/s)를 지정합니다.
D_default = 10; t_gap = 1.4; v_set = 28;
차량 동특성의 물리적 한계를 시뮬레이션하기 위해 가속 범위를 [–3,2](m/s^2)로, 조향각 범위를 [–0.2618,0.2618](rad)(즉, -15도와 15도)로 각각 제한합니다.
amin_ego = -3; amax_ego = 2; umin_ego = -0.2618; % +15 deg umax_ego = 0.2618; % -15 deg
도로의 곡률은 상수 0.001()로 정의됩니다. 횡방향 편차의 초기값은 0.2m이고, 상대적 요 각도의 초기값은 –0.1rad입니다.
rho = 0.001; e1_initial = 0.2; e2_initial = -0.1;
샘플 시간 Ts와 시뮬레이션 지속 시간 Tf를 초 단위로 정의합니다.
Ts = 0.1; Tf = 60;
모델을 엽니다.
mdl = "rlPFCMdl"; open_system(mdl) agentblk = mdl + "/RL Agent";

이 모델의 경우 다음이 적용됩니다.
행동 신호는 가속 행동과 조향각 행동으로 구성됩니다. 가속 행동 신호는 –3과 2(m/s^2) 사이의 값을 받습니다. 조향 행동 신호는 –15도(–0.2618 rad)와 15도(0.2618 rad) 사이의 값을 받습니다.
자기 차량의 기준 속도 는 다음과 같이 정의됩니다. 상대 거리가 안전 거리보다 짧으면 자기 차량은 선행 차량 속도와 운전자 설정 속도의 최솟값을 추종합니다. 이 같은 방식으로 자기 차량은 선행 차량과의 거리를 유지합니다. 상대 거리가 안전 거리보다 길면 자기 차량은 운전자 설정 속도를 추종합니다. 이 예제에서 안전 거리는 자기 차량 종방향 속도 의 선형 함수로 정의됩니다. 즉, 입니다. 이 안전 거리가 자기 차량의 추종 속도를 결정합니다.
환경에서 관측하는 값에는 종방향 측정값 즉, 속도 오차 , 적분 , 자기 차량 종방향 속도 가 포함됩니다. 그 외에도 관측값에는 횡방향 측정값 즉, 횡방향 편차 과 상대적 요 각도 , 이들의 도함수인 과 , 이들의 적분인 과 가 포함됩니다.
횡방향 편차가 이거나 종방향 속도가 이거나 선행 차량과 자기 차량 간의 상대 거리가 이면 시뮬레이션이 종료됩니다.
매 시간 스텝 마다 제공되는 보상 는 다음과 같습니다.
여기서 은 이전 시간 스텝 의 조향 입력이고, 은 이전 시간 스텝의 가속 입력입니다. 3개의 논리값은 다음과 같습니다.
시뮬레이션이 종료된 경우 이고, 그 외의 경우에는 입니다.
횡방향 오차가 인 경우 이고, 그 외의 경우에는 입니다.
속도 오차 인 경우 이고, 그 외의 경우에는 입니다.
이 3가지의 보상 논리 항은 에이전트에 횡방향 오차는 물론 속도 오차도 작게 만들도록 동기를 부여하고, 그 사이에 시뮬레이션이 조기 종료되면 에이전트에 벌점을 부여합니다.
환경 인터페이스 만들기
Simulink 모델에 대한 환경 인터페이스를 만듭니다.
관측값 사양을 만듭니다.
obsInfo = rlNumericSpec([9 1], ... LowerLimit=-inf*ones(9,1), ... UpperLimit=inf*ones(9,1)); obsInfo.Name = "observations";
행동 사양을 만듭니다.
actInfo = rlNumericSpec([2 1], ... LowerLimit=[-3;-0.2618], ... UpperLimit=[2;0.2618]); actInfo.Name = "accel;steer";
환경 인터페이스를 만듭니다.
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);
초기 조건을 정의하려면 익명 함수 핸들을 사용하여 환경 재설정 함수를 지정하십시오. 예제 끝에 정의된 재설정 함수 localResetFcn은 선행 차량의 초기 위치와 횡방향 편차 및 상대적 요 각도를 무작위로 할당합니다.
env.ResetFcn = @(in)localResetFcn(in);
재현이 가능하도록 난수 생성기 시드값을 고정합니다.
rng(0)
DDPG 에이전트 만들기
DDPG 에이전트는 파라미터화된 Q-값 함수 근사기를 사용하여 정책의 값을 추정합니다. Q-값 함수 크리틱은 현재 관측값과 행동을 입력값으로 받고 single형 스칼라를 출력값(현재 관측값에 해당하는 상태로부터 행동을 받고 그 후 정책을 따를 때 추정되는 감가된 누적 장기 보상)으로 반환합니다.
크리틱 내에서 파라미터화된 Q-값 함수를 모델링하려면 두 개의 입력 계층(obsInfo로 지정된 대로 관측값 채널에 대한 입력 계층 및 actInfo로 지정된 대로 행동 채널에 대한 입력 계층)과 (스칼라 값을 반환하는) 하나의 출력 계층을 갖는 신경망을 사용하십시오. prod(obsInfo.Dimension)과 prod(actInfo.Dimension)은 행 벡터, 열 벡터 또는 행렬로 정렬되는지에 관계없이 각각 관측값 공간과 행동 공간의 차원 수를 반환합니다.
각 신경망 경로를 layer 객체로 구성된 배열로 정의하고 각 경로의 입력 계층과 출력 계층에 이름을 할당합니다. 이러한 이름을 사용하면 경로를 연결한 다음 나중에 신경망 입력 계층 및 출력 계층을 적절한 환경 채널과 명시적으로 연결할 수 있습니다.
% Number of neurons L = 100; % Main path mainPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(L) reluLayer fullyConnectedLayer(L) additionLayer(2,Name="add") reluLayer fullyConnectedLayer(L) reluLayer fullyConnectedLayer(1,Name="QValLyr") ]; % Action path actionPath = [ featureInputLayer(prod(actInfo.Dimension),Name="actInLyr") fullyConnectedLayer(L,Name="actOutLyr") ]; % Assemble layergraph object criticNet = layerGraph(mainPath); criticNet = addLayers(criticNet,actionPath); criticNet = connectLayers(criticNet,"actOutLyr","add/in2");
dlnetwork 객체로 변환하고 가중치 개수를 표시합니다.
criticNet = dlnetwork(criticNet); summary(criticNet)
Initialized: true
Number of learnables: 21.6k
Inputs:
1 'obsInLyr' 9 features
2 'actInLyr' 2 features
크리틱 신경망 구성을 확인합니다.
figure plot(criticNet)
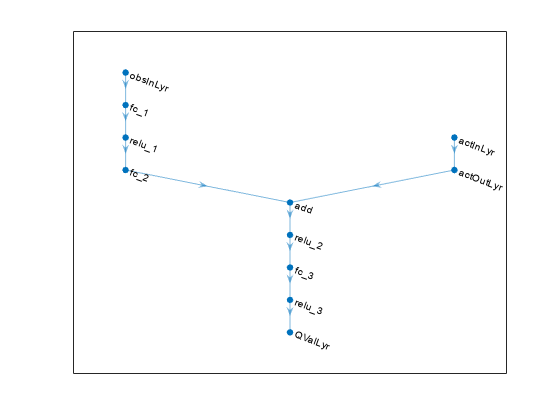
지정된 신경망과 환경 행동 및 관측값 사양을 사용하여 크리틱을 만듭니다. 관측값 채널 및 행동 채널과 연결할 신경망 계층의 이름도 추가 인수로 전달합니다. 자세한 내용은 rlQValueFunction 항목을 참조하십시오.
critic = rlQValueFunction(criticNet,obsInfo,actInfo,... ObservationInputNames="obsInLyr",ActionInputNames="actInLyr");
DDPG 에이전트는 연속 행동 공간에 대해 연속 결정적 액터가 학습한 파라미터화된 결정적 정책을 사용합니다. 이 액터는 현재 관측값을 입력값으로 받고 관측값의 결정적 함수인 행동을 출력값으로 반환합니다.
액터 내에서 파라미터화된 정책을 모델링하려면 (obsInfo로 지정된 대로 환경 관측값 채널의 내용을 받는) 하나의 입력 계층과 (actInfo로 지정된 대로 환경 행동 채널에 행동을 반환하는) 하나의 출력 계층을 갖는 신경망을 사용하십시오.
신경망을 layer 객체로 구성된 배열로 정의합니다.
actorNet = [
featureInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(L)
reluLayer
fullyConnectedLayer(L)
reluLayer
fullyConnectedLayer(L)
reluLayer
fullyConnectedLayer(2)
tanhLayer
scalingLayer(Scale=[2.5;0.2618],Bias=[-0.5;0])
];dlnetwork 객체로 변환하고 가중치 개수를 표시합니다.
actorNet = dlnetwork(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 21.4k
Inputs:
1 'input' 9 features
크리틱과 비슷한 방식으로 액터를 생성합니다. 자세한 내용은 rlContinuousDeterministicActor 항목을 참조하십시오.
actor = rlContinuousDeterministicActor(actorNet,obsInfo,actInfo);
rlOptimizerOptions를 사용하여 크리틱과 액터에 대한 훈련 옵션을 지정합니다.
criticOptions = rlOptimizerOptions( ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=1e-4); actorOptions = rlOptimizerOptions( ... LearnRate=1e-4, ... GradientThreshold=1, ... L2RegularizationFactor=1e-4);
rlDDPGAgentOptions를 사용하여 DDPG 에이전트 옵션을 지정하고 액터와 크리틱의 옵션을 포함시킵니다.
agentOptions = rlDDPGAgentOptions(... SampleTime=Ts,... ActorOptimizerOptions=actorOptions,... CriticOptimizerOptions=criticOptions,... ExperienceBufferLength=1e6); agentOptions.NoiseOptions.Variance = [0.6;0.1]; agentOptions.NoiseOptions.VarianceDecayRate = 1e-5;
액터, 크리틱 및 에이전트 옵션을 사용하여 DDPG 에이전트를 만듭니다. 자세한 내용은 rlDDPGAgent 항목을 참조하십시오.
agent = rlDDPGAgent(actor,critic,agentOptions);
에이전트 훈련시키기
에이전트를 훈련시키려면 먼저 훈련 옵션을 지정하십시오. 이 예제에서는 다음 옵션을 사용합니다.
최대
10000개의 에피소드에 대해 훈련을 실행하며, 각 에피소드마다 최대maxsteps개의 시간 스텝이 지속됩니다.에피소드 관리자 대화 상자에 훈련 진행 상황을 표시합니다(
Verbose및Plots옵션 설정).에이전트가 받은 누적 에피소드 보상이
1700보다 클 때 훈련을 중지합니다.
자세한 내용은 rlTrainingOptions 항목을 참조하십시오.
maxepisodes = 1e4; maxsteps = ceil(Tf/Ts); trainingOpts = rlTrainingOptions(... MaxEpisodes=maxepisodes,... MaxStepsPerEpisode=maxsteps,... Verbose=false,... Plots="training-progress",... StopTrainingCriteria="EpisodeCount",... StopTrainingValue=1450);
train 함수를 사용하여 에이전트를 훈련시킵니다. 훈련은 완료하는 데 수 분이 소요되는 계산 집약적인 절차입니다. 이 예제를 실행하는 동안 시간을 절약하려면 doTraining을 false로 설정하여 사전 훈련된 에이전트를 불러오십시오. 에이전트를 직접 훈련시키려면 doTraining을 true로 설정하십시오.
doTraining = false; if doTraining % Train the agent. trainingStats = train(agent,env,trainingOpts); else % Load a pretrained agent for the example. load("SimulinkPFCDDPG.mat","agent") end

DDPG 에이전트 시뮬레이션하기
훈련된 에이전트의 성능을 검증하려면 다음 명령의 주석을 해제하여 Simulink 환경 내에서 에이전트를 시뮬레이션하십시오. 에이전트 시뮬레이션에 대한 자세한 내용은 rlSimulationOptions 항목과 sim 항목을 참조하십시오.
% simOptions = rlSimulationOptions(MaxSteps=maxsteps); % experience = sim(env,agent,simOptions);
결정적 초기 조건을 사용하여 훈련된 에이전트를 시연하려면 Simulink에서 모델을 시뮬레이션하십시오.
e1_initial = -0.4; e2_initial = 0.1; x0_lead = 80; sim(mdl)
다음 플롯은 선행 차량이 자기 차량보다 70(m) 앞설 때의 시뮬레이션 결과를 보여줍니다.
처음 35초 동안에는 상대 거리가 안전 거리(오른쪽 아래 플롯)보다 크기 때문에 자기 차량이 설정 속도(오른쪽 위 플롯)를 추종합니다. 속도를 높여 설정 속도에 도달하기 위해 가속이 대부분 음수가 아닙니다(왼쪽 위 플롯).
35초부터 42초까지는 상대 거리가 안전 거리(오른쪽 아래 플롯)보다 대부분 작기 때문에 자기 차량이 선행 차량 속도의 최솟값과 설정 속도를 추종합니다. 선행 차량의 속도가 설정 속도(오른쪽 위 플롯)보다 작기 때문에 선행 차량 속도를 추종하기 위해 가속이 0이 아닌 값(왼쪽 위 플롯)이 됩니다.
42초부터 58초까지 자기 차량은 설정 속도(오른쪽 위 플롯)를 추종하고 가속은 0(왼쪽 위 플롯)으로 유지됩니다.
58초부터 60초까지는 상대 거리가 안전 거리(오른쪽 아래 플롯)보다 작기 때문에 자기 차량이 속도를 늦추고 선행 차량 속도를 추종합니다.
왼쪽 아래 플롯은 횡방향 편차를 보여줍니다. 플롯에 나와 있는 것처럼, 횡방향 편차는 1초 내에 급격히 감소합니다. 횡방향 편차는 0.05m 미만으로 유지됩니다.

Simulink 모델을 닫습니다.
bdclose(mdl)
재설정 함수
function in = localResetFcn(in) % random value for initial position of lead car in = setVariable(in,"x0_lead",40+randi(60,1,1)); % random value for lateral deviation in = setVariable(in,"e1_initial", 0.5*(-1+2*rand)); % random value for relative yaw angle in = setVariable(in,"e2_initial", 0.1*(-1+2*rand)); end
참고 항목
함수
train|sim|rlSimulinkEnv