textscan
텍스트 파일이나 문자열에서 형식 지정된 데이터 읽어 들이기
구문
설명
C = textscan(fileID,formatSpec)C로 읽어 들입니다. 파일 ID fileID로 텍스트 파일을 지정합니다. fileID 값은 fopen으로 파일을 열어 구할 수 있습니다. 파일에서 읽기가 끝나면 fclose(fileID)를 호출하여 파일을 닫습니다.
textscan은 파일의 데이터가 formatSpec의 변환 지정자와 일치하는지 확인합니다. textscan은 전체 파일에 formatSpec을 다시 적용하고 formatSpec을 데이터와 일치시킬 수 없는 경우 중지합니다.
C = textscan(fileID,formatSpec,N)formatSpec을 N번 사용하여 파일 데이터를 읽어 들입니다. 여기서 N은 양의 정수입니다. N주기 이후에 파일에서 추가 데이터를 읽으려면 원래 fileID를 사용하여 textscan을 다시 호출하십시오. 동일한 파일 ID(fileID)와 함께 textscan을 호출하여 파일의 텍스트 스캔을 재개하는 경우, textscan은 마지막 읽기가 종료된 지점에서 읽기를 자동으로 재개합니다.
C = textscan(chr,formatSpec)chr의 텍스트를 셀형 배열 C로 읽어 들입니다. 문자형 벡터에서 텍스트를 읽어올 때는 textscan을 반복 호출할 때마다 스캔이 처음부터 다시 시작됩니다. 마지막 위치에서 스캔을 다시 시작하려면 position 출력값을 요청하십시오.
textscan은 문자형 벡터 chr의 데이터가 formatSpec에 지정된 형식과 일치하는지 확인합니다.
C = textscan(chr,formatSpec,N)formatSpec을 N번 사용합니다. 여기서 N은 양의 정수입니다.
C = textscan(___,Name,Value)Name,Value 쌍의 입력 인수를 하나 이상 사용하여 옵션을 지정합니다.
예제
부동소수점 숫자가 포함된 문자형 벡터 읽기
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
formatSpec 내의 '%f' 지정자는 chr의 각 필드에서 배정밀도 부동소수점 숫자가 있는지 확인하도록 textscan에 지시합니다.
셀형 배열 C의 내용을 표시합니다.
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
각 값을 소수점 1자릿수로 자르며 동일한 문자형 벡터를 읽습니다.
C = textscan(chr,'%3.1f %*1d');지정자 %3.1f는 필드 너비 3자릿수와 정밀도 1을 나타냅니다. textscan 함수는 소수점 및 소수점 다음의 1자리를 포함하여 총 3자리를 읽습니다. 지정자 %*1d는 나머지 숫자를 건너뛰도록 textscan에 지시합니다.
셀형 배열 C의 내용을 표시합니다.
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
일련의 16진수를 나타내는 문자형 벡터를 읽어 들입니다. 16진수를 나타내는 텍스트에는 숫자 0-9와 문자 a-f 또는 A-F가 포함되며, 접두사 0x 또는 0X가 포함될 수 있습니다.
hexnums의 필드를 16진수와 일치시키려면 '%x' 지정자를 사용하십시오. textscan 함수는 필드를 부호 없는 64비트 정수로 변환합니다.
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1×1 cell array
{6×1 uint64}
C의 내용을 행 벡터로 표시합니다.
transpose(C{:})ans = 1×6 uint64 row vector
255 256 15454 10 15 16
필드를 8비트, 16비트, 32비트 또는 64비트의 부호 있는 정수 또는 부호 없는 정수로 변환할 수 있습니다. hexnums의 필드를 부호 있는 32비트 정수로 변환하려면 '%xs32' 지정자를 사용하십시오.
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1×6 int32 row vector
255 256 15454 10 15 16
입력값을 해석하기 위해 필드 너비를 지정할 수도 있습니다. 이 경우 접두사는 필드 너비에 포함됩니다. 예를 들어, %3x에서와 같이 필드 너비를 3으로 설정하면 textscan은 텍스트 '0xAF 100'을 '0xA', 'F' 및 '100'의 세 조각 텍스트로 분할합니다. 이 세 조각의 텍스트는 서로 다른 16진수로 처리됩니다.
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1×3 uint64 row vector
10 15 256
일련의 이진수를 나타내는 문자형 벡터를 읽어 들입니다. 이진수를 나타내는 텍스트는 숫자 0과 1을 포함하며, 접두사 0b 또는 0B가 포함될 수 있습니다.
binnums의 필드를 이진수와 일치시키려면 '%b' 지정자를 사용하십시오. textscan 함수는 필드를 부호 없는 64비트 정수로 변환합니다.
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1×1 cell array
{5×1 uint64}
C의 내용을 행 벡터로 표시합니다.
transpose(C{:})ans = 1×5 uint64 row vector
42 3 4 9 2
필드를 8비트, 16비트, 32비트 또는 64비트의 부호 있는 정수 또는 부호 없는 정수로 변환할 수 있습니다. binnums의 필드를 부호 있는 32비트 정수로 변환하려면 '%bs32' 지정자를 사용하십시오.
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1×5 int32 row vector
42 3 4 9 2
입력값을 해석하기 위해 필드 너비를 지정할 수도 있습니다. 이 경우 접두사는 필드 너비에 포함됩니다. 예를 들어, %3b에서와 같이 필드 너비를 3으로 설정하면 textscan는 텍스트 '0b1010 100'을 '0b1', '010' 및 '100'의 세 조각 텍스트로 분할합니다. 세 조각의 텍스트는 서로 다른 이진수로 처리됩니다.
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1×3 uint64 row vector
1 2 4
데이터 파일을 불러오고, 적합한 유형을 사용하여 각 열을 읽습니다.
파일 scan1.dat를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다.
filename = 'scan1.dat';
파일을 열고, 적절한 변환 지정자를 사용하여 각 열을 읽습니다. textscan은 1-by-9 셀형 배열 C를 반환합니다.
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2249 cell
C의 각 셀의 MATLAB® 데이터형을 확인합니다.
C
C=1×9 cell array
{3×1 cell} {3×1 cell} {3×1 single} {3×1 int8} {3×1 uint32} {3×1 double} {3×1 double} {3×1 cell} {3×1 double}
개별 요소를 검토합니다. C{1}과 C{2}는 셀형 배열입니다. C{5}는 uint32 데이터형이므로 C{5}의 처음 2개 요소는 32비트 부호 없는 정수에 대한 최댓값이거나 intmax('uint32')입니다.
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
이전 예제에서 다룬 데이터의 두 번째 열의 각 필드에서 리터럴 텍스트 'Level'을 제거합니다. 아래에 이 파일의 미리보기가 나와 있습니다.

파일을 열고, formatSpec 입력값의 리터럴 텍스트를 일치시킵니다.
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3×1 int32 column vector
1
2
3
C의 두 번째 셀의 MATLAB® 데이터형을 확인합니다. 1-by-9 셀형 배열 C의 두 번째 셀은 이제 int32 데이터형이 됩니다.
disp( class(C{2}) )int32
이전 예제에서 다룬 파일의 첫 번째 열을 셀형 배열로 읽어 들이고, 라인의 나머지를 건너뜁니다.
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3×1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan은 셀형 배열 날짜를 반환합니다.
파일 data.csv를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 이 파일에는 쉼표로 구분된 데이터가 들어 있으며, 빈 값도 들어 있습니다.
![]()
빈 셀을 -Inf로 변환하고 파일을 읽습니다.
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2×1 uint8 column vector
0
11
textscan은 1-by-6 셀형 배열 C를 반환합니다. textscan 함수는 C{4}의 빈 값을 -Inf로 변환합니다. 여기서 C{4}는 부동소수점 형식과 연결되어 있습니다. MATLAB®은 부호 없는 정수 -Inf를 0으로 나타내기 때문에 textscan은 C{5}의 빈 값을 -Inf가 아니라 0으로 변환합니다.
파일 data2.csv를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 이 파일에는 주석으로 해석될 수 있는 데이터와, 'NA' 또는 'na'처럼 빈 필드를 나타낼 수 있는 기타 요소가 들어 있습니다.
filename = 'data2.csv';![]()
textscan이 주석이나 빈 값으로 취급해야 하는 입력값을 지정하고, 데이터를 C로 스캔합니다.
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
출력값을 표시합니다.
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
파일 data3.csv를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 이 파일에는 반복되는 구분 기호가 들어 있습니다.
filename = 'data3.csv';
반복 쉼표를 단일 구분 기호로 취급하려면 MultipleDelimsAsOne 파라미터를 사용하여 값을 1(true)로 설정하십시오.
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
이 예제에 대한 데이터 파일 grades.txt를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 이 파일에는 반복되는 구분 기호가 들어 있습니다.
filename = 'grades.txt';
'%s' 형식을 4번 사용하여 열 제목을 읽습니다.
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
파일에서 숫자형 데이터를 읽습니다.
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4×1 int32} {4×1 double} {4×1 double} {4×1 double}
CollectOutput의 디폴트 값은 0(false)이므로 textscan은 개별 배열로 숫자형 데이터의 각 열을 반환합니다.
파일 위치 표시자를 파일의 시작 부분으로 설정합니다.
frewind(fileID);
파일을 다시 읽고 CollectOutput을 1(true)로 설정하여 동일한 클래스의 연속 열을 단일 배열로 모읍니다. repmat 함수를 사용하여 %f 변환 지정자가 3번 나타나야 함을 지정할 수 있습니다. 이 기법은 형식이 여러 번 반복되는 경우에 유용합니다.
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4×1 int32} {4×3 double}
테스트 점수(모두 double형)가 단일 4×3 배열에 수집됩니다.
파일을 닫습니다.
fclose(fileID);
텍스트 파일에서 데이터의 첫 번째 열과 마지막 열을 읽습니다. 텍스트로 구성된 열과 정수 데이터로 구성된 열을 건너뜁니다.
파일 names.txt를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 이 파일에는 따옴표로 묶인 텍스트 열이 2개 있고, 이어서 정수 열이 1개 있으며, 마지막으로 부동소수점 숫자 열이 1개 들어 있습니다.
filename = 'names.txt';
파일에서 데이터의 첫 번째 열과 마지막 열을 읽습니다. 변환 지정자 %q를 사용하여 큰따옴표(")로 묶인 텍스트를 읽습니다. %*q는 따옴표로 묶인 텍스트를 건너뛰고 %*d는 정수 필드를 건너뛰고 %f는 부동소수점 숫자를 읽습니다. 'Delimiter' 이름-값 쌍의 인수를 사용하여 쉼표 구분자를 지정합니다.
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
출력값을 표시합니다. textscan은 텍스트를 묶는 큰따옴표가 제거된 셀형 배열 C를 반환합니다.
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
파일 german_dates.txt를 불러오고 텍스트 편집기에서 파일 내용을 미리 봅니다. 아래에 스크린샷이 나와 있습니다. 값의 첫 번째 열에는 독일식 날짜가 포함되어 있고 두 번째 및 세 번째 열에는 숫자형 값이 들어 있습니다.
filename = 'german_dates.txt';
파일을 엽니다. fopen의 마지막 입력값으로 파일에 연결되어 있는 문자 인코딩 체계를 지정합니다.
fileID = fopen(filename,'r','n','ISO-8859-15');
파일을 읽습니다. %{dd % MMMM yyyy}D 지정자를 사용하여 파일의 날짜 형식을 지정합니다. DateLocale 이름-값 쌍의 인수를 사용하여 날짜의 로캘을 지정합니다.
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
C의 첫 번째 셀 내용을 확인합니다. 시스템 로캘에 따라 MATLAB이 사용하는 언어로 날짜가 표시됩니다.
C{1}ans = 3×1 datetime
01 January 2014
01 February 2014
01 March 2014
sprintf를 사용하여 데이터에서 디폴트가 아닌 이스케이프 시퀀스를 변환합니다.
폼 피드 문자 \f를 포함하는 텍스트를 만듭니다. 그런 다음, textscan을 사용하여 텍스트를 읽기 위해 sprintf를 호출하여 폼 피드를 명시적으로 변환합니다.
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7×1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan은 셀형 배열 C를 반환합니다.
시작 부분 외의 위치에서 스캔을 재개합니다.
텍스트 스캔을 재개하면 textscan이 항상 시작 부분부터 읽습니다. 다른 위치에서 스캔을 재개하려면 textscan에 대한 초기 호출에서 2출력 인수 구문을 사용하십시오.
예를 들어, lyric이라는 문자형 벡터를 생성해 보겠습니다. 문자형 벡터의 첫 번째 단어를 읽은 다음 스캔을 재개합니다.
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
입력 인수
열려 있는 텍스트 파일의 파일 ID로, 숫자로 지정됩니다. textscan으로 파일을 읽으려면 fopen을 사용하여 파일을 연 다음 fileID를 가져와야 합니다.
데이터형: double
데이터 필드의 형식으로, 하나 이상의 변환 지정자로 구성된 문자형 벡터 또는 string형으로 지정됩니다. textscan은 입력값을 읽을 때 데이터가 formatSpec에 지정된 형식과 일치하는지 확인합니다. textscan은 데이터 필드와 일치하지 않는 부분이 나오면 읽기를 중지하고 읽은 모든 필드를 반환합니다.
변환 지정자의 개수에 따라 출력 배열 C의 셀 개수가 결정됩니다.
숫자형 필드
다음 표에는 숫자형 입력값에 대해 사용 가능한 변환 지정자가 나와 있습니다.
| 숫자형 입력 유형 | 변환 지정자 | 출력값 클래스 |
|---|---|---|
| 정수, 부호 있음 | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| 정수, 부호 없음 | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| 부동소수점 숫자 | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| 16진수, 부호 없는 정수 | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| 16진수, 부호 있는 정수 | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| 2진수, 부호 없는 정수 | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| 2진수, 부호 있는 정수 | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
숫자형이 아닌 필드
다음 표에는 숫자형이 아닌 문자를 포함하는 입력값에 대해 사용 가능한 변환 지정자가 나와 있습니다.
| 숫자형이 아닌 입력 유형 | 변환 지정자 | 세부 정보 |
|---|---|---|
| 문자 | %c | 구분 기호를 포함하여 단일 문자를 읽습니다. |
| 텍스트 배열 | %s | 문자형 벡터로 구성된 셀형 배열로 읽습니다. |
%q | 문자형 벡터로 구성된 셀형 배열로 읽습니다. 텍스트가 큰따옴표( 예: | |
| 날짜와 시간 | %D | 위의 |
%{ | 위의 datetime형 표시 형식에 대한 자세한 내용은 datetime형 배열의 예: | |
| 지속 시간 | %T | 위의 |
%{ | 위의 duration형 표시 형식에 대한 자세한 내용은 duration형 배열의 예: | |
| 범주 | %C |
|
| 패턴 일치 | %[...] | 문자형 벡터로 구성된 셀형 배열로 괄호 내부의 문자와 일치하는 문자를 읽다가 일치하지 않는 첫 번째 문자에서 중지합니다. 세트에 예: |
%[^...] | 괄호 내부의 문자와 일치하지 않는 문자를 읽다가 일치하는 첫 번째 문자에서 중지합니다. 예: |
선택적 연산자
formatSpec의 변환 지정자는 다음 순서로 표시되는 선택적 연산자를 포함할 수 있습니다(이해를 돕기 위해 공백을 포함함).
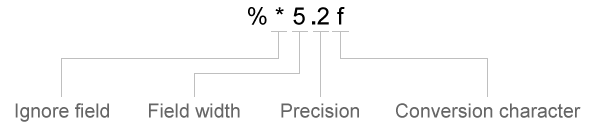
선택적 연산자에는 다음이 포함됩니다.
필드 및 문자 무시
특정 필드 또는 필드의 일부분을 무시하도록 지정하지 않을 경우
textscan은 순차적으로 파일의 모든 문자를 읽습니다.필드나 문자형 필드의 일부분을 건너뛰려면 퍼센트 문자(%) 다음에 별표 문자(*)를 삽입하십시오.
연산자
수행 동작
%*k필드를 건너뜁니다.
k는 건너뛸 필드를 식별하는 변환 지정자입니다.textscan은 이러한 필드에 대해 출력 셀을 생성하지 않습니다.예:
'%s %*s %s %s %*s %*s %s'(공백은 선택 사항임)는 텍스트
'Blackbird singing in the dead of night'를
'Blackbird' 'in' 'the' 'night'를 가진 4개의 출력 셀로 변환합니다.'%*ns'최대
n개 문자를 건너뜁니다. 여기서n은 필드의 문자 개수보다 작거나 같은 정수입니다.예:
'%*3s %s'는'abcdefg'를'defg'로 변환합니다. 구분 기호가 쉼표인 경우, 동일한 구분 기호는'abcde,fghijkl'을'de';'ijkl'이 포함된 셀형 배열로 변환합니다.'%*nc'구분 기호 문자를 포함하여
n개 문자를 건너뜁니다.필드 너비
textscan은 필드 너비나 정밀도로 지정되는 개수만큼 또는 최초의 구분 기호가 나타날 때까지 문자나 숫자를 읽습니다(둘 중 먼저 해당하는 경우 적용). 숫자형 지수의 소수점, 부호(+또는-), 지수 문자, 숫자는 필드 너비 내의 문자 및 숫자로 계산됩니다. 복소수의 경우, 필드 너비는 실수부와 허수부의 개별 너비를 나타냅니다. 허수부의 경우, 필드 너비는 + 또는 −를 포함하지만i또는j는 포함하지 않습니다. 변환 지정자의 퍼센트 문자(%) 다음에 숫자를 삽입하여 필드 너비를 지정하십시오.예:
%5f는'123.456'을123.4로 읽습니다.예:
%5c는'abcdefg'를'abcde'로 읽습니다.필드 너비 연산자가 단일 문자와 함께 사용되면(
%c),textscan은 또한 구분 기호, 공백 및 라인 끝(EOL) 문자를 읽습니다.
예:%7c는 공백을 포함하여 7개 문자를 읽습니다. 그러므로'Day and night'를'Day and'로 읽습니다.정밀도
부동소수점 숫자의 경우(
%n,%f,%f32,%f64), 읽으려는 소수점 자릿수를 지정할 수 있습니다.예:
%7.2f는'123.456'을123.45로 읽습니다.리터럴 텍스트 무시
textscan은formatSpec변환 지정자에 추가된 텍스트를 무시합니다.예:
Level%u8은'Level1'을1로 읽습니다.예:
%u8Step은'2Step'을2로 읽습니다.
데이터형: char | string
formatSpec을 적용할 횟수로, 양의 정수로 지정됩니다.
데이터형: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
읽을 텍스트를 입력합니다.
데이터형: char | string
이름-값 인수
출력 인수
알고리즘
textscan은 오버플로, 잘림 및 NaN, Inf, -Inf의 사용과 관련된 MATLAB 규칙에 따라 숫자형 필드를 지정된 출력 유형으로 변환합니다. 예를 들어, MATLAB은 정수 NaN을 0으로 나타냅니다. textscan이 정수 형식 지정자(%d 또는 %u)와 연결된 빈 필드를 찾는 경우 이 빈 값을 NaN이 아니라 0으로 반환합니다.
데이터가 텍스트 변환 지정자와 일치하는 경우 textscan은 구분 기호를 찾거나 라인 끝(EOL) 문자를 찾을 때까지 읽습니다. 데이터가 숫자형 변환 지정자와 일치하는 경우 textscan은 숫자형이 아닌 문자를 찾을 때까지 읽습니다. 특정 변환 지정자와 일치하는 부분을 더 이상 찾을 수 없게 되면 textscan은 formatSpec의 그 다음 변환 지정자와 데이터가 일치하는지 확인하기 시작합니다. 부호(+ 또는 -), 지수 문자, 소수점은 숫자형 문자로 간주됩니다.

| 부호 | 자릿수 | 소수점 | 자릿수 | 지수 문자 | 부호 | 자릿수 |
|---|---|---|---|---|---|---|
| 부호 문자 하나를 읽습니다(있는 경우). | 1자리 이상의 숫자를 읽습니다. | 소수점 하나를 읽습니다(있는 경우). | 소수점이 있는 경우 바로 다음에 오는 1자리 이상의 숫자를 읽습니다. | 지수 문자 하나를 읽습니다(있는 경우). | 지수 문자가 있는 경우 부호 문자 하나를 읽습니다. | 지수 문자가 있는 경우 다음에 오는 1자리 이상의 숫자를 읽습니다. |
textscan은 복소수를 가져오는 경우 전체 필드를 복소수 필드로 설정해, 실수부와 허수부를 지정된 숫자형으로 변환합니다(예: %d 또는 %f). 유효한 형식의 복소수는 다음과 같습니다.
±<real>±<imag>i|j | 예: |
±<imag>i|j | 예: |
textscan은 복소수에 포함된 공백을 필드 구분 기호로 해석하므로 복소수에 공백을 포함시키지 마십시오.