setvaropts
변수에 대한 가져오기 옵션 설정
설명
opts = setvaropts(opts,Name,Value)Name,Value 인수에 포함된 조건을 기반으로 하여 opts 객체에 포함된 모든 변수를 업데이트하고 opts 객체를 반환합니다.
opts = setvaropts(opts,selection,Name,Value)Name,Value 인수에 포함된 조건을 기반으로 하여 selection 인수에 지정된 변수에 대한 opts 객체를 업데이트하고 반환합니다.
예제
import options 객체를 생성하고, 선택한 변수에 대한 옵션을 설정하고, 조정된 옵션과 readtable 함수를 사용하여 데이터를 가져옵니다.
스프레드시트 patients.xls에 대한 옵션 객체를 생성합니다.
opts = detectImportOptions('patients.xls');Smoker, Diastolic, Systolic 변수에 대한 FillValue 속성을 설정합니다.
opts = setvaropts(opts,'Smoker','FillValue',false); opts = setvaropts(opts,{'Diastolic','Systolic'},'FillValue',0);
가져올 변수를 선택합니다.
opts.SelectedVariableNames = {'Smoker','Diastolic','Systolic'};변수를 가져오고 요약을 표시합니다.
T = readtable('patients.xls',opts);
summary(T) T: 100×3 table
Variables:
Smoker: logical (34 true)
Diastolic: double
Systolic: double
Statistics for applicable variables:
NumMissing Min Median Max Mean Std
Diastolic 0 68 81.5000 99 82.9600 6.9325
Systolic 0 109 122 138 122.7800 6.7128
누락된 필드나 불완전 필드를 가지는 데이터를 가져오려면 누락된 인스턴스를 인식하고 누락된 인스턴스를 가져올 방법을 결정해야 합니다. importOptions를 사용하여 이러한 경우를 모두 포착하고 readtable을 사용하여 데이터를 가져옵니다.
파일에 대한 import options 객체를 생성하고, 누락된 데이터 가져오기를 제어하는 속성을 업데이트하고, readtable을 사용하여 데이터를 가져옵니다. 참고로, 데이터셋 airlinesmall_subset.csv는 NA로 지정된 누락된 데이터를 포함하는 두 개의 숫자형 변수 ArrDelay와 DepDelay를 가집니다.

파일에서 import options 객체를 생성합니다.
opts = detectImportOptions("airlinesmall_subset.csv");TreatAsMissing 속성을 사용하여 데이터에서 누락된 인스턴스로 간주할 자리 표시자 문자를 지정합니다. 이 예제에서 두 개의 숫자형 변수 ArrDelay와 DepDelay에는 텍스트 NA를 포함하는 누락된 필드가 있습니다.
opts = setvaropts(opts,["ArrDelay","DepDelay"],"TreatAsMissing","NA");
누락된 인스턴스를 가져올 때 가져오기 함수가 취할 동작을 지정합니다. 추가 옵션은 ImportOptions 속성 페이지를 참조하십시오.
opts.MissingRule = "fill";가져오기 함수가 누락된 인스턴스를 발견할 경우 사용할 값을 지정합니다. 여기서는 변수 ArrDelay와 DepDelay에서 누락된 인스턴스가 0으로 대체됩니다.
opts = setvaropts(opts,["ArrDelay","DepDelay"],"FillValue",0);
작업할 변수를 선택하고 readtable을 사용하여 가져옵니다.
opts.SelectedVariableNames = ["ArrDelay","DepDelay"]; T = readtable("airlinesmall_subset.csv",opts);
ArrDelay와 DepDelay의 값을 검토합니다. 가져오기 함수가 NA로 표시된 누락값을 대체했는지 확인합니다.
T(42:55,:)
ans=14×2 table
ArrDelay DepDelay
________ ________
3 -4
0 -1
11 11
0 0
0 0
0 0
-9 5
-9 -3
2 6
0 0
1 1
0 4
9 0
-2 4
readtable 함수는 0x 접두사와 0b 접두사를 통해 자동으로 16진수 숫자와 2진수 숫자를 감지합니다. 접두사가 없는 16진수 숫자와 2진수 숫자를 가져오려면 import options 객체를 사용하십시오.
파일 hexAndBinary.txt에 대한 import options 객체를 만듭니다. 세 번째 열에 0x 접두사가 없는 16진수 숫자가 있습니다.

opts = detectImportOptions('hexAndBinary.txt')opts =
DelimitedTextImportOptions with properties:
Format Properties:
Delimiter: {','}
Whitespace: '\b\t '
LineEnding: {'\n' '\r' '\r\n'}
CommentStyle: {}
ConsecutiveDelimitersRule: 'split'
LeadingDelimitersRule: 'keep'
TrailingDelimitersRule: 'ignore'
EmptyLineRule: 'skip'
Encoding: 'UTF-8'
Replacement Properties:
MissingRule: 'fill'
ImportErrorRule: 'fill'
ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype
VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableTypes: {'auto', 'auto', 'char' ... and 1 more}
SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableOptions: Show all 4 VariableOptions
Access VariableOptions sub-properties using setvaropts/getvaropts
VariableNamingRule: 'modify'
Location Properties:
DataLines: [1 Inf]
VariableNamesLine: 0
RowNamesColumn: 0
VariableUnitsLine: 0
VariableDescriptionsLine: 0
To display a preview of the table, use preview
접두사가 없어도 세 번째 열을 16진수 값으로 가져오도록 지정하려면 setvaropts 함수를 사용하십시오. 세 번째 변수의 변수 유형을 int32로 설정합니다. 세 번째 열을 가져오기 위한 진법을 hex로 설정합니다.
opts = setvaropts(opts,3,'NumberSystem','hex','Type','int32')
opts =
DelimitedTextImportOptions with properties:
Format Properties:
Delimiter: {','}
Whitespace: '\b\t '
LineEnding: {'\n' '\r' '\r\n'}
CommentStyle: {}
ConsecutiveDelimitersRule: 'split'
LeadingDelimitersRule: 'keep'
TrailingDelimitersRule: 'ignore'
EmptyLineRule: 'skip'
Encoding: 'UTF-8'
Replacement Properties:
MissingRule: 'fill'
ImportErrorRule: 'fill'
ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype
VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableTypes: {'auto', 'auto', 'int32' ... and 1 more}
SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableOptions: Show all 4 VariableOptions
Access VariableOptions sub-properties using setvaropts/getvaropts
VariableNamingRule: 'modify'
Location Properties:
DataLines: [1 Inf]
VariableNamesLine: 0
RowNamesColumn: 0
VariableUnitsLine: 0
VariableDescriptionsLine: 0
To display a preview of the table, use preview
파일을 읽어서 처음 세 개의 열을 숫자형 값으로 가져옵니다. readtable 함수는 첫 번째 열과 두 번째 열에 16진수 값과 2진수 값이 포함되어 있음을 자동으로 감지합니다. import options 객체는 세 번째 열에도 16진수 값이 포함되어 있음을 지정합니다.
T = readtable('hexAndBinary.txt',opts)T=3×4 table
Var1 Var2 Var3 Var4
_____ ____ _____ ___________
255 255 51193 {'Device1'}
256 4 1471 {'Device2'}
43981 129 61455 {'Device3'}
setvaropts 함수를 사용하여 텍스트 데이터 가져오기를 제어하는 속성을 업데이트합니다. 우선, 파일에 대한 import options 객체를 가져옵니다. 다음으로, 텍스트 변수에 대한 옵션을 검토하고 업데이트합니다. 마지막으로, readtable 함수를 사용하여 변수를 가져옵니다.
patients.xls의 데이터를 미리 봅니다. 열 LastName에 텍스트 데이터가 있는 것을 알 수 있습니다. 여기에는 처음 10개 행의 미리보기만 표시되어 있습니다.
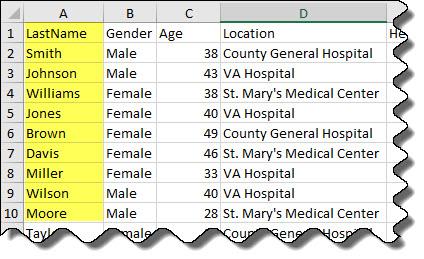
import options 객체를 가져옵니다.
opts = detectImportOptions('patients.xls');변수 LastName에 대한 VariableImportOptions를 가져오고 검토합니다.
getvaropts(opts,'LastName')ans =
TextVariableImportOptions with properties:
Variable Properties:
Name: 'LastName'
Type: 'char'
FillValue: ''
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
String Options:
WhitespaceRule: 'trim'
변수의 데이터형을 string으로 설정합니다.
opts = setvartype(opts,'LastName','string');
누락값을 'NoName'으로 대체하도록 변수의 FillValue 속성을 설정합니다.
opts = setvaropts(opts,'LastName','FillValue','NoName');
변수의 처음 10개 행에 대한 미리보기를 선택하여 읽고 표시합니다.
opts.SelectedVariableNames = 'LastName'; T = readtable('patients.xls',opts); T.LastName(1:10)
ans = 10×1 string
"Smith"
"Johnson"
"Williams"
"Jones"
"Brown"
"Davis"
"Miller"
"Wilson"
"Moore"
"Taylor"
setvaropts 함수를 사용하여 logical형 데이터 가져오기를 제어하는 속성을 업데이트합니다. 우선, 파일에 대한 import options 객체를 가져옵니다. 다음으로, 논리형 변수에 대한 옵션을 검토하고 업데이트합니다. 마지막으로, readtable 함수를 사용하여 변수를 가져옵니다.
airlinesmall_subset.xlsx의 데이터를 미리 봅니다. 열 Cancelled에 논리형 데이터가 있는 것을 알 수 있습니다. 여기에는 행 30~40의 미리보기만 표시되어 있습니다.

import options 객체를 가져옵니다.
opts = detectImportOptions('airlinesmall_subset.xlsx');변수 Cancelled에 대한 VariableImportOptions를 가져오고 검토합니다.
getvaropts(opts,'Cancelled')ans =
NumericVariableImportOptions with properties:
Variable Properties:
Name: 'Cancelled'
Type: 'double'
FillValue: NaN
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
Numeric Options:
ExponentCharacter: 'eEdD'
DecimalSeparator: '.'
ThousandsSeparator: ''
TrimNonNumeric: 0
NumberSystem: 'decimal'
변수의 데이터형을 logical로 설정합니다.
opts = setvartype(opts,'Cancelled','logical');
누락값을 true로 대체하도록 변수의 FillValue 속성을 설정합니다.
opts = setvaropts(opts,'Cancelled','FillValue',true);
변수의 요약을 선택하여 읽고 표시합니다.
opts.SelectedVariableNames = 'Cancelled'; T = readtable('airlinesmall_subset.xlsx',opts); summary(T)
T: 1338×1 table
Variables:
Cancelled: logical (29 true)
DatetimeVariableImportOptions 속성을 사용하여 datetime형 데이터 가져오기를 제어합니다. 먼저, 파일에 대한 ImportOptions 객체를 가져옵니다. 다음으로, datetime형 변수에 대한 VariableImportOptions를 검토하고 업데이트합니다. 마지막으로, readtable을 사용하여 변수를 가져옵니다.
outages.csv의 데이터를 미리 봅니다. 열 OutageTime과 RestorationTime에 날짜/시간 데이터가 있다는 것을 알 수 있습니다. 여기에는 처음 10개 행만 표시되어 있습니다.

import options 객체를 가져옵니다.
opts = detectImportOptions('outages.csv');datetime형 변수 OutageTime 및 RestorationTime에 대한 VariableImportOptions를 가져오고 검토합니다.
varOpts = getvaropts(opts,{'OutageTime','RestorationTime'})varOpts =
1×2 DatetimeVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
DatetimeFormat
DatetimeLocale
TimeZone
InputFormat
누락값을 현재 날짜와 시간으로 대체하도록 변수의 FillValue 속성을 설정합니다.
opts = setvaropts(opts,{'OutageTime','RestorationTime'},...
'FillValue','now');두 개의 변수를 선택하여 읽고 미리 봅니다. RestorationTime의 두 번째 행에서 누락값이 현재 날짜와 시간으로 채워져 있는 것을 알 수 있습니다.
opts.SelectedVariableNames = {'OutageTime','RestorationTime'};
T = readtable('outages.csv',opts);
T(1:10,:)ans=10×2 table
OutageTime RestorationTime
________________ ________________
2002-02-01 12:18 2002-02-07 16:50
2003-01-23 00:49 2026-01-24 21:54
2003-02-07 21:15 2003-02-17 08:14
2004-04-06 05:44 2004-04-06 06:10
2002-03-16 06:18 2002-03-18 23:23
2003-06-18 02:49 2003-06-18 10:54
2004-06-20 14:39 2004-06-20 19:16
2002-06-06 19:28 2002-06-07 00:51
2003-07-16 16:23 2003-07-17 01:12
2004-09-27 11:09 2004-09-27 16:37
setvaropts 함수를 사용하여 categorical형 데이터 가져오기를 제어하는 속성을 업데이트합니다. 우선, 파일에 대한 import options 객체를 가져옵니다. 다음으로, categorical형 변수에 대한 옵션을 검토하고 업데이트합니다. 마지막으로, readtable 함수를 사용하여 변수를 가져옵니다.
outages.csv의 데이터를 미리 봅니다. 열 Region 및 Cause에 categorical형 데이터가 있는 것을 알 수 있습니다. 다음 표에는 처음 10개 행만 표시되어 있습니다.
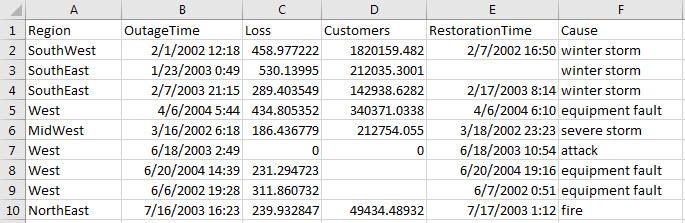
import options 객체를 가져옵니다.
opts = detectImportOptions('outages.csv');변수 Region 및 Cause에 대한 옵션을 가져오고 검토합니다.
getvaropts(opts,{'Region','Cause'})ans =
1×2 TextVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
WhitespaceRule
변수의 데이터형을 categorical로 설정합니다.
opts = setvartype(opts,{'Region','Cause'},'categorical');누락값을 범주 이름 'Miscellaneous'로 대체하도록 변수의 FillValue 속성을 설정합니다. TreatAsMissing 속성을 'unknown'으로 설정합니다.
opts = setvaropts(opts,{'Region','Cause'},...
'FillValue','Miscellaneous',...
'TreatAsMissing','unknown');두 개 변수의 요약을 선택하여 읽고 표시합니다.
opts.SelectedVariableNames = {'Region','Cause'};
T = readtable('outages.csv',opts);
summary(T)T: 1468×2 table
Variables:
Region: categorical (5 categories)
Cause: categorical (10 categories)
Statistics for applicable variables:
NumMissing
Region 0
Cause 0
원치 않는 접두사 문자와 접미사 문자를 포함하는 변수를 갖는 테이블 형식 데이터를 가져옵니다. 먼저 import options 객체를 생성하여 데이터를 미리 봅니다. 그런 다음 원하는 변수를 선택하고 해당 변수의 변수 유형과 속성을 설정하여 원치 않는 문자를 제거합니다. 마지막으로 원하는 데이터를 가져옵니다.
파일의 가져오기 옵션을 생성하고 테이블을 미리 봅니다.
filename = 'pref_suff_trim.csv';
opts = detectImportOptions(filename);
preview(filename,opts)Warning: Column headers from the file were modified to make them valid MATLAB identifiers before creating variable names for the table. The original column headers are saved in the VariableDescriptions property. Set 'VariableNamingRule' to 'preserve' to use the original column headers as table variable names.
ans=8×5 table
'Timestamp:1/1/06 0:00' '& Sun %20' '54.5448 MW' '$1.23' '-7.2222 C'
'Timestamp:1/2/06 1:00' '& Thu %20' '.3898 MW' '$300.00' '-7.3056 C'
'Timestamp:1/3/06 2:00' '& Sun %20' '51.6344 MW' '£2.50' '-7.8528 C'
'Timestamp:1/4/06 3:00' '& Sun %20' '51.5597 MW' '$0.00' '-8.1778 C'
'Timestamp:1/5/06 4:00' '& Wed %20' '51.7148 MW' '¥4.00' '-8.9343 C'
'Timestamp:1/6/06 5:00' '& Sun %20' '52.6898 MW' '$0.00' '-8.7556 C'
'Timestamp:1/7/06 6:00' '& Mon %20' '55.341 MW' '$50.70' '-8.0417 C'
'Timestamp:1/8/06 7:00' '& Sat %20' '57.9512 MW' '$0.00' '-8.2028 C'
원하는 변수를 선택하고 선택한 변수의 유형을 지정한 다음 변수 가져오기 옵션 값을 검토합니다.
opts.SelectedVariableNames = {'Time','Total_Fees','Temperature'};
opts = setvartype(opts,'Time','datetime');
opts = setvaropts(opts,'Time','InputFormat','MM/dd/uu HH:mm'); % Specify datetime format
opts = setvartype(opts,{'Total_Fees','Temperature'},'double');
getvaropts(opts,{'Time','Total_Fees','Temperature'})ans =
1×3 VariableImportOptions array with properties:
Variable Options:
(1) | (2) | (3)
Name: 'Time' | 'Total_Fees' | 'Temperature'
Type: 'datetime' | 'double' | 'double'
FillValue: NaT | NaN | NaN
TreatAsMissing: {} | {} | {}
EmptyFieldRule: 'missing' | 'missing' | 'missing'
QuoteRule: 'remove' | 'remove' | 'remove'
Prefixes: {} | {} | {}
Suffixes: {} | {} | {}
To access sub-properties of each variable, use getvaropts
변수 가져오기 옵션의 Prefixes 속성, Suffixes 속성, TrimNonNumeric 속성이 변수 Time에서 'Timestamp:'를 제거하고, 변수 Temperature에서 접미사 'C'를 제거하고, 변수 Total_Fees에서 숫자형이 아닌 모든 문자를 제거하도록 설정합니다. 새로운 가져오기 옵션을 갖는 테이블을 미리 봅니다.
opts = setvaropts(opts,'Time','Prefixes','Timestamp:'); opts = setvaropts(opts,'Temperature','Suffixes','C'); opts = setvaropts(opts,'Total_Fees','TrimNonNumeric',true); preview(filename,opts)
ans=8×3 table
01/01/06 00:00 1.2300 -7.2222
01/02/06 01:00 300 -7.3056
01/03/06 02:00 2.5000 -7.8528
01/04/06 03:00 0 -8.1778
01/05/06 04:00 4 -8.9343
01/06/06 05:00 0 -8.7556
01/07/06 06:00 50.7000 -8.0417
01/08/06 07:00 0 -8.2028
readtable을 사용하여 데이터를 가져옵니다.
T = readtable(filename,opts);
빈 필드를 포함하는 파일에 대한 import options 객체를 생성합니다. EmptyFieldRule 파라미터를 사용하여 데이터의 빈 필드에 대한 가져오기를 관리합니다. 먼저 데이터를 미리 본 다음 특정 변수에 대해 EmptyFieldRule 파라미터를 설정합니다. 마지막으로, 모든 변수에 대해 EmptyFieldRule을 설정하고 데이터를 가져옵니다.
빈 필드를 포함하는 파일에 대한 import options 객체를 생성합니다. preview 함수를 사용하여 테이블의 처음 8개 행을 가져옵니다. EmptyFieldRule의 디폴트 값은 'missing'입니다. 따라서 가져오기 함수는 빈 필드를 누락된 것으로 처리하고 해당 필드를 이 변수의 FillValue 값으로 대체합니다. 세 번째 변수에 대해 VariableOptions를 사용하여 데이터를 미리 봅니다. 이때 preview 함수는 세 번째 변수의 빈 필드를 NaN으로 가져옵니다.
filename = 'DataWithEmptyFields.csv'; opts = detectImportOptions(filename); opts.VariableOptions(3) % Display the Variable Options for the 3rd Variable
ans =
NumericVariableImportOptions with properties:
Variable Properties:
Name: 'Double'
Type: 'double'
FillValue: NaN
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
Numeric Options:
ExponentCharacter: 'eEdD'
DecimalSeparator: '.'
ThousandsSeparator: ''
TrimNonNumeric: 0
NumberSystem: 'decimal'
preview(filename,opts)
ans=8×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ __________ ________ __________
{'abc' } {'a' } 1 01/14/0018 {'TRUE' } 00:00:01 {'abc' }
{0×0 char} {'b' } 2 01/21/0018 {'FALSE' } 09:00:01 {'def' }
{'ghi' } {0×0 char} 3 01/31/0018 {'TRUE' } 02:00:01 {'ghi' }
{'jkl' } {'a' } NaN 02/23/2018 {'FALSE' } 03:00:01 {'jkl' }
{'mno' } {'a' } 4 NaT {'FALSE' } 04:00:01 {'mno' }
{'pqr' } {'b' } 5 01/23/0018 {0×0 char} 05:00:01 {'pqr' }
{'stu' } {'b' } 5 03/23/0018 {'FALSE' } NaN {'stu' }
{0×0 char} {'a' } 6 03/24/2018 {'TRUE' } 07:00:01 {0×0 char}
테이블의 두 번째 변수에 대해 EmptyFieldRule을 설정합니다. 먼저 변수를 선택한 다음 EmptyFieldRule을 'auto'로 설정합니다. 여기서 readtable 함수는 categorical형 변수의 빈 필드를 <undefined>로 가져옵니다.
opts.SelectedVariableNames = 'Categorical'; opts = setvartype(opts,'Categorical','categorical'); opts = setvaropts(opts,'Categorical','EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×1 table
Categorical
___________
a
b
<undefined>
a
a
b
b
a
a
<undefined>
그런 다음 테이블의 모든 변수에 대해 EmptyFieldRule 파라미터를 설정합니다. 먼저 변수의 데이터형을 적절히 업데이트합니다. 이 예제에서는 5번째 변수와 7번째 변수의 데이터형을 각각 logical과 string으로 설정합니다. 그런 다음 모든 변수에 대해 EmptyFieldRule을 'auto'로 설정합니다. 가져오기 함수는 변수의 데이터형을 기준으로 빈 필드를 가져옵니다. 이때 readtable 함수는 logical형 변수의 빈 필드를 0으로 가져오고 categorical형 변수의 빈 필드를 <undefined>로 가져옵니다.
VariableNames = opts.VariableNames; opts.SelectedVariableNames = VariableNames; % select all variables opts = setvartype(opts,{'Logical','String'},{'logical','string'}); opts = setvaropts(opts,VariableNames,'EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ _______ ________ _________
{'abc' } a 1 01/14/0018 true 00:00:01 "abc"
{0×0 char} b 2 01/21/0018 false 09:00:01 "def"
{'ghi' } <undefined> 3 01/31/0018 true 02:00:01 "ghi"
{'jkl' } a NaN 02/23/2018 false 03:00:01 "jkl"
{'mno' } a 4 NaT false 04:00:01 "mno"
{'pqr' } b 5 01/23/0018 false 05:00:01 "pqr"
{'stu' } b 5 03/23/0018 false NaN "stu"
{0×0 char} a 6 03/24/2018 true 07:00:01 ""
{0×0 char} a 7 03/25/2018 true 08:00:01 <missing>
{'xyz' } <undefined> NaN NaT true 06:00:01 "xyz"
EmptyFieldRule 파라미터는 'missing'과 'auto' 외에도 'error'로 설정할 수 있습니다. 'error'로 설정하는 경우 readtable 함수는 ImportErrorRule 파라미터에 지정된 방법에 따라 빈 필드를 가져옵니다.
입력 인수
이름-값 인수
버전 내역
R2016b에 개발됨