partition
데이터저장소 파티셔닝
구문
설명
예제
대규모 파일 모음을 저장할 데이터저장소를 만듭니다. 이 예제에서는 샘플 파일 airlinesmall.csv의 복사본 10개를 사용합니다. 테이블 형식 데이터의 누락된 필드를 처리하기 위해 이름-값 쌍 TreatAsMissing과 MissingValue를 지정합니다.
files = repmat({'airlinesmall.csv'},1,10);
ds = tabularTextDatastore(files,...
'TreatAsMissing','NA','MissingValue',0);데이터저장소를 3개의 파티션으로 분할하고 첫 번째 파티션을 반환합니다. partition 함수는 데이터저장소 ds에 들어 있는 데이터 중에서 약 삼분의 일 분량에 해당하는 첫 번째 부분을 반환합니다.
subds = partition(ds,3,1);
데이터저장소의 Files 속성은 데이터저장소에 들어 있는 파일의 목록을 포함합니다. 데이터저장소 ds와 분할된 데이터저장소 subds의 Files 속성에서 파일 개수를 확인합니다. 데이터저장소 ds에는 10개의 파일이 들어 있고, 파티션 subds에는 처음 4개의 파일이 들어 있습니다.
length(ds.Files)
ans = 10
length(subds.Files)
ans = 4
샘플 파일 mapredout.mat에서 데이터저장소를 만듭니다. 이 파일은 mapreduce 함수의 출력 파일입니다.
ds = datastore('mapredout.mat');ds의 디폴트 파티션 개수를 가져옵니다.
n = numpartitions(ds);
데이터저장소를 디폴트 파티션 개수로 파티셔닝하고 첫 번째 파티션에 대응하는 데이터저장소를 반환합니다.
subds = partition(ds,n,1);
subds에서 데이터를 읽습니다.
while hasdata(subds) data = read(subds); end
3개의 이미지 파일이 포함된 데이터저장소를 만듭니다.
ds = imageDatastore({'street1.jpg','peppers.png','corn.tif'})
ds =
ImageDatastore with properties:
Files: {
' ...\folder1\street1.jpg';
' ...\folder1\peppers.png';
' ...\folder1\corn.tif'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
파일을 기준으로 데이터저장소를 파티셔닝하고 두 번째 파일에 대응하는 파트를 반환합니다.
subds = partition(ds,'Files',2)
subds =
ImageDatastore with properties:
Files: {
' ...\folder1\peppers.png'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
subds에는 하나의 파일이 포함됩니다.
샘플 파일 mapredout.mat에서 데이터저장소를 만듭니다. 이 파일은 mapreduce 함수의 출력 파일입니다.
ds = datastore('mapredout.mat');병렬 풀의 3개의 워커에 대한 데이터저장소를 3개의 파트로 파티셔닝합니다.
numWorkers = 3; p = parpool('local',numWorkers); n = numpartitions(ds,p); parfor ii=1:n subds = partition(ds,n,ii); while hasdata(subds) data = read(subds); end end
성기게 세분한 파티션을 정교하게 세분한 서브셋과 비교합니다.
비디오 파일 xylophone.mp4에서 모든 프레임을 읽어 들이고 반복을 수행할 ArrayDatastore 객체를 만듭니다. 결과로 생성되는 객체에는 141개의 프레임이 있습니다.
v = VideoReader("xylophone.mp4"); allFrames = read(v); arrds = arrayDatastore(allFrames,IterationDimension=4,OutputType="cell",ReadSize=4);
인접한 프레임들의 특정 집합을 추출하기 위해 arrds로부터 16개의 성기게 세분한 파티션을 만듭니다. 두 번째 파티션을 추출합니다. 이 파티션에는 9개의 프레임이 있습니다.
partds = partition(arrds,16,2); imshow(imtile(partds.readall()))
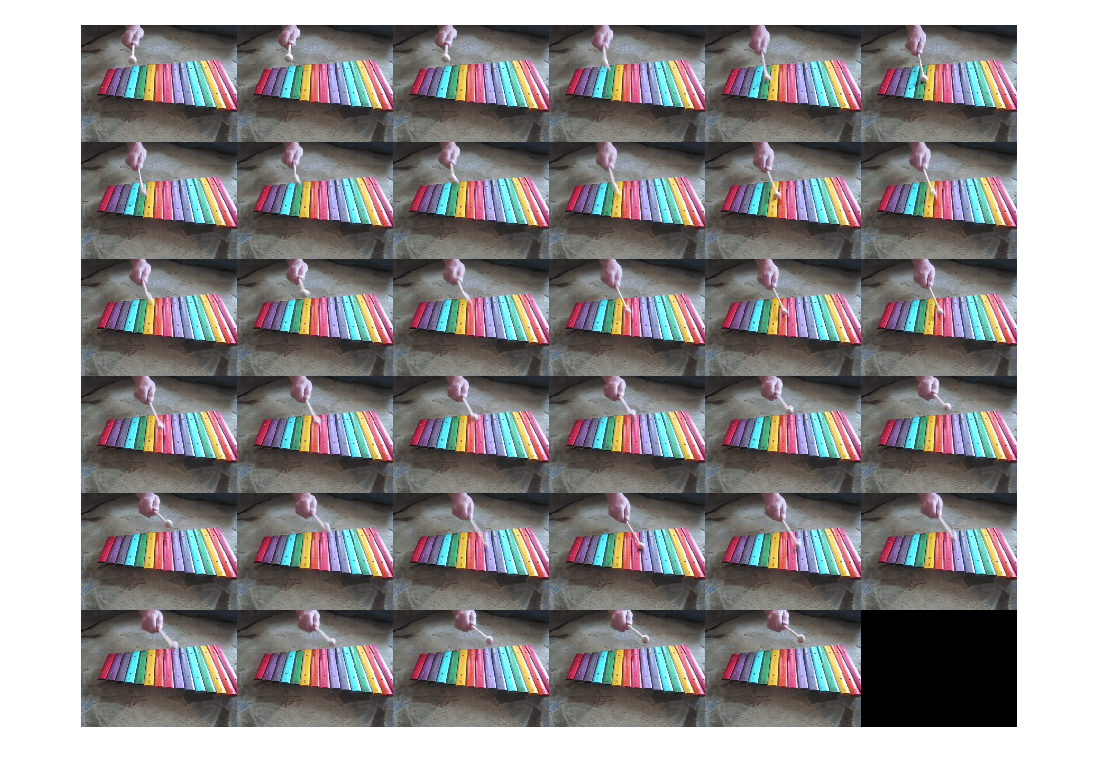
정교하게 세분한 서브셋을 사용하여 arrds로부터 지정된 인덱스에 있는 2개의 서로 인접하지 않은 프레임을 추출합니다.
subds = subset(arrds,[67 79]); imshow(imtile(subds.readall()))

입력 인수
출력 인수
확장 기능
버전 내역
R2015a에 개발됨
참고 항목
datastore | numpartitions | subset
도움말 항목
- Partition a Datastore in Parallel (Parallel Computing Toolbox)