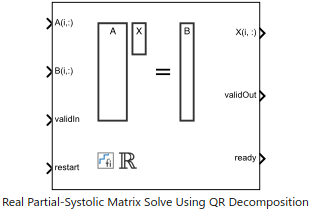
Real Partial-Systolic Matrix Solve Using QR Decomposition
Compute value of x in the equation Ax = B for real-valued matrices using QR decomposition

Libraries:
Fixed-Point Designer HDL Support /
Matrices and Linear Algebra /
Linear System Solvers
Description
The Real Partial-Systolic Matrix Solve Using QR Decomposition block solves the system of linear equations Ax = B using QR decomposition, where A and B are real-valued matrices. To compute x = A-1, set B to be the identity matrix.
When Regularization parameter is nonzero, the
Real Partial-Systolic Matrix Solve Using QR Decomposition block computes the
matrix solution of real-valued where λ is the regularization parameter,
A is an m-by-n matrix,
p is the number of columns in B,
In =
eye(n), and
0n,p =
zeros(n,p).
Examples
Implement Hardware-Efficient Real Partial-Systolic Matrix Solve Using QR Decomposition
How to use the Real Partial-Systolic Matrix Solve Using QR Decomposition block.
Implement Hardware-Efficient Real Partial-Systolic Matrix Solve Using QR Decomposition with Diagonal Loading
How to use the Real Partial-Systolic Matrix Solve Using QR Decomposition Block with diagonal loading.
Implement Hardware-Efficient Real Partial-Systolic Matrix Solve Using QR Decomposition with Tikhonov Regularization
Use the Real Partial-Systolic Matrix Solve Using QR Decomposition block to solve the regularized least-squares matrix equation

Algorithms to Determine Fixed-Point Types for Real Least-Squares Matrix Solve AX=B
Derivation of algorithms for determining fixed-point types for real least-squares matrix solve.
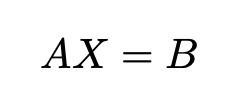
Determine Fixed-Point Types for Real Least-Squares Matrix Solve AX=B
Use fixed.realQRMatrixSolveFixedpointTypes to determine fixed-point
types for computation of the real least-squares matrix equation.
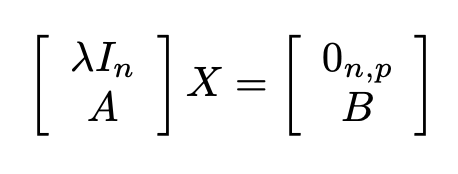
Determine Fixed-Point Types for Real Least-Squares Matrix Solve with Tikhonov Regularization
Use the fixed.realQRMatrixSolveFixedpointTypes function to analytically determine fixed-point types for the solution of the real least-squares matrix equation
Ports
Input
Output
Parameters
Algorithms
The Partial-Systolic Matrix Solve Using QR Decomposition blocks accept and process A and B matrices row by row. After accepting m rows, the block outputs the matrix X as a single vector. The partial-systolic implementation uses a pipelined structure, so the block can accept new matrix inputs before outputting the result of the current matrix.
For example, assume that the input A and B
matrices are 3-by-3. Additionally assume that validIn asserts before
ready, meaning that the upstream data source is faster than the QR
decomposition.

In the figure,
A1r1is the first row of the first A matrix andX1is the matrix X, output as a vector.validIntoready— From a successful row input to the block being ready to accept the next row.Last row
validIntovalidOut— From the last row input to the block starting to output the solution.
The following table provides details of the timing for the Real Partial-Systolic Matrix Solve Using QR Decomposition block. Latency depends on the size of matrix A and the data types of the A and B matrices. In the table:
m represents the number of rows in matrix A and n is the number of columns in matrix A.
wl represents the word length of the input data. If the data types of A and B are fixed point or scaled double
fi, then wl is given bymax(A.WordLength + ~issigned(A), B.WordLength + ~issigned(B)).
| Input Data Type | validIn to ready (cycles) | Last Row validIn to validOut
(cycles) |
|---|---|---|
Fixed point fi | max(wl + 7, ceil((3.5*n2 + n*(nextpow2(wl) + wl + 8.5) + 6)/m)) | (wl + 6)*n + 3.5*n2 + n*(nextpow2(wl) + wl + 9.5) + 9 - n |
Scaled double fi | max(wl + 7, ceil((3.5*n2 + n*(wl + 7.5) + 6)/m)) | (wl + 6)*n + 3.5*n2 + n*(wl + 7.5) + 9 |
double | max(60, ceil((3.5*n2 + 6.5*n + 6)/m)) | 3.5*n2 + 65.5*n + 9 |
single | max(31, ceil((3.5*n2 + 6.5*n + 6)/m)) | 3.5*n2 + 36.5*n + 9 |
References
[1] "AMBA AXI and ACE Protocol Specification Version E." https://developer.arm.com/documentation/ihi0022/e/