이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
trainbfg
BFGS 준뉴턴 역전파
설명
net.trainFcn = 'trainbfg'는 신경망의 trainFcn 속성을 설정합니다.
[은 trainedNet,tr] = train(net,...)trainbfg를 사용하여 신경망을 훈련시킵니다.
trainbfg는 BFGS 준뉴턴(quasi-Newton) 방법에 따라 가중치와 편향 값을 업데이트하는 신경망 훈련 함수입니다.
아래에 디폴트 값과 함께 표시된 다음의 trainbfg 훈련 파라미터에 따라 훈련이 이루어집니다.
net.trainParam.epochs— 훈련할 최대 Epoch 횟수. 디폴트 값은 1000입니다.net.trainParam.showWindow— 훈련 GUI 표시. 디폴트 값은true입니다.net.trainParam.show— 다음 표시까지 진행할 Epoch 횟수(표시하지 않으려면NaN). 디폴트 값은 25입니다.net.trainParam.showCommandLine— 명령줄 출력값 생성. 디폴트 값은false입니다.net.trainParam.goal— 성능 목표. 디폴트 값은 0입니다.net.trainParam.time— 훈련을 진행할 최대 시간(단위: 초). 디폴트 값은inf입니다.net.trainParam.min_grad— 최소 성능 기울기. 디폴트 값은1e-6입니다.net.trainParam.max_fail— 최대 검증 실패 횟수. 디폴트 값은6입니다.net.trainParam.searchFcn— 사용할 직선 탐색 루틴의 이름. 디폴트 값은'srchbac'입니다.
직선 탐색 방법과 관련된 파라미터는 다음과 같습니다. (모든 파라미터가 모든 방법에 사용되는 것은 아닙니다.)
net.trainParam.scal_tol— 선형 탐색의 허용오차를 구하기 위해 델타로 나눔. 디폴트 값은 20입니다.net.trainParam.alpha— perf의 충분한 감소를 결정하는 스케일링 인자. 디폴트 값은0.001입니다.net.trainParam.beta— 충분히 큰 스텝 크기를 결정하는 스케일링 인자. 디폴트 값은0.1입니다.net.trainParam.delta— 간격 위치 스텝의 초기 스텝 크기. 디폴트 값은0.01입니다.net.trainParam.gamma— 성능의 작은 감소를 방지하는 파라미터(보통 0.1로 설정,srch_cha참조). 디폴트 값은0.1입니다.net.trainParam.low_lim— 스텝 크기 변경 하한. 디폴트 값은0.1입니다.net.trainParam.up_lim— 스텝 크기 변경 상한. 디폴트 값은0.5입니다.net.trainParam.maxstep— 최대 스텝 길이. 디폴트 값은100입니다.net.trainParam.minstep— 최소 스텝 길이. 디폴트 값은1.0e-6입니다.net.trainParam.bmax— 최대 스텝 크기. 디폴트 값은26입니다.net.trainParam.batch_frag— 여러 개의 배치가 있는 경우, 각각 독립적인 것으로 간주됩니다. 0이 아닌 값은 모두 조각화된 배치를 의미하므로, 이전에 훈련된 Epoch의 마지막 계층 조건은 다음 Epoch의 초기 조건으로 사용됩니다. 디폴트 값은0입니다.
예제
이 예제에서는 trainbfg 훈련 함수를 사용하여 신경망을 훈련시키는 방법을 다룹니다.
체지방 비율을 예측하도록 신경망을 훈련시킵니다.
[x, t] = bodyfat_dataset;
net = feedforwardnet(10, 'trainbfg');
net = train(net, x, t);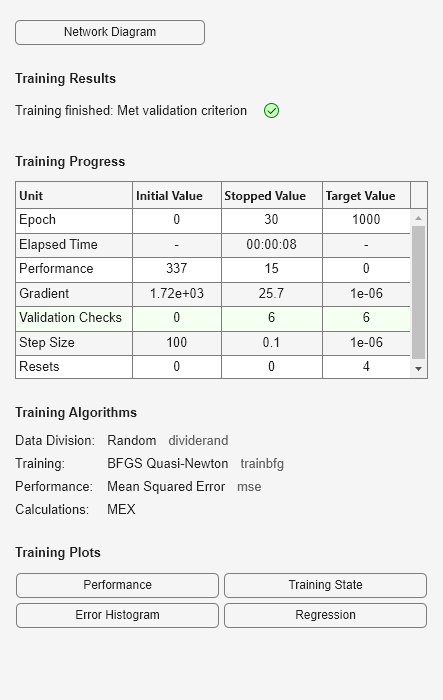
y = net(x);
입력 인수
출력 인수
세부 정보
알고리즘
trainbfg는 신경망의 가중치, 순 입력값, 전달 함수가 도함수를 갖는 한 어떤 신경망도 훈련시킬 수 있습니다.
역전파는 가중치와 편향 변수 X에 대한 성능 perf의 도함수를 계산하기 위해 사용됩니다. 각 변수는 다음에 따라 조정됩니다.
X = X + a*dX;
여기서 dX는 탐색 방향입니다. 파라미터 a는 탐색 방향을 따라 성능이 최소화되도록 선택됩니다. 직선 탐색 함수 searchFcn을 사용하여 극솟점을 찾습니다. 첫 번째 탐색 방향은 성능 기울기의 음수 값입니다. 이후 이어지는 반복에서 탐색 방향은 다음 수식에 따라 계산됩니다.
dX = -H\gX;
여기서 gX는 기울기이고 H는 근사 헤세 행렬입니다. BFGS 준뉴턴 방법에 대한 자세한 내용은 Gill, Murray, Wright의 Practical Optimization(1981)의 119페이지를 참조하십시오.
다음 조건 중 하나라도 충족되면 훈련이 중지됩니다.
epochs(반복)의 최대 횟수에 도달함.time의 최대 값이 초과됨.성능이
goal로 최소화됨.성능 기울기가
min_grad아래로 떨어짐.(검증을 사용하는 경우) 검증 성능(검증 오류)이 마지막으로 감소한 이후로
max_fail배 넘게 증가함.
참고 문헌
[1] Gill, Murray, & Wright, Practical Optimization, 1981
버전 내역
R2006a 이전에 개발됨