Use the Compiler Output for System Integration
To integrate the generated deep learning processor IP core into your system reference
design, use the compile method outputs. The compile method:
Generates the external memory address map.
Optimizes the network layers for deployment.
Splits networks into smaller series networks called legs for deployment.
External Memory Address Map
Reduce the time to integrate the generated deep learning processor IP core into your
reference design by using the compile method external memory address map.
Use the address map to:
Load the inputs to the deep learning processor IP core.
Load the deep learning processor IP core instructions.
Load the network weights and biases.
Retrieve the prediction results.
The external memory address map consists of these address offsets:
InputDataOffset— Address offset where the input images are loaded.OutputResultOffset— Output results are written starting at this address offset.SchedulerDataOffset— Address offset where the scheduler runtime activation data is written. The runtime activation data includes information such as hand off between the different deep learning processor kernels, instructions for the different deep learning processor kernels, and so on.SystemBufferOffset— Do not use the memory address starting at this offset and ending at the start of theInstructionDataOffset.InstructionDataOffset— All layer configuration (LC) instructions are written starting at this address offset.ConvWeightDataOffset— All conv processing module weights are written starting at this address offset.FCWeightDataOffset— All fully connected (FC) processing module weights are written starting at this address offset.EndOffset— DDR memory end offset for generated deep learning processor IP.
For an example of the generated external memory address map, see the Compile dagnet Network Object. The example displays the external memory map generated for the ResNet-18 image recognition network and the Xilinx® Zynq® UltraScale+™ MPSoC ZCU102 FPGA development board.
Compiler Optimizations
Optimize your custom deep learning network deployment by identifying layers that you can
execute in a single operation on hardware by fusing these layers together. The
compile method performs these layer fusions and optimizations:
Batch normalization layer (
batchNormalizationLayer) and 2-D convolution layer (convolution2dLayer).2-D zero padding layer (
nnet.keras.layer.ZeroPadding2dLayer) and 2-D convolution layer (convolution2dLayer).2-D zero padding layer (
nnet.keras.layer.ZeroPadding2dLayer) and 2-D max polling layer (maxPooling2dLayer).
This code output is an example compiler optimization in the compiler log.
Optimizing series network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
Leg Level Compilations
Identify subsets of your deep learning networks that could be split into smaller series
networks, by using the compile method generated legs. A leg is a subset of
the DAG network that you can convert into a series network. The compile
function groups the legs based on the output format of the layers. The layer output format
is defined as the data format of the deep learning processor module that processes that
layer. The layer output format is conv, fc, or adder. For example, in this image, the
compile function groups all the layers in Leg 2
together because they have a conv output format. To learn about the layer output formats,
see Supported Layers.
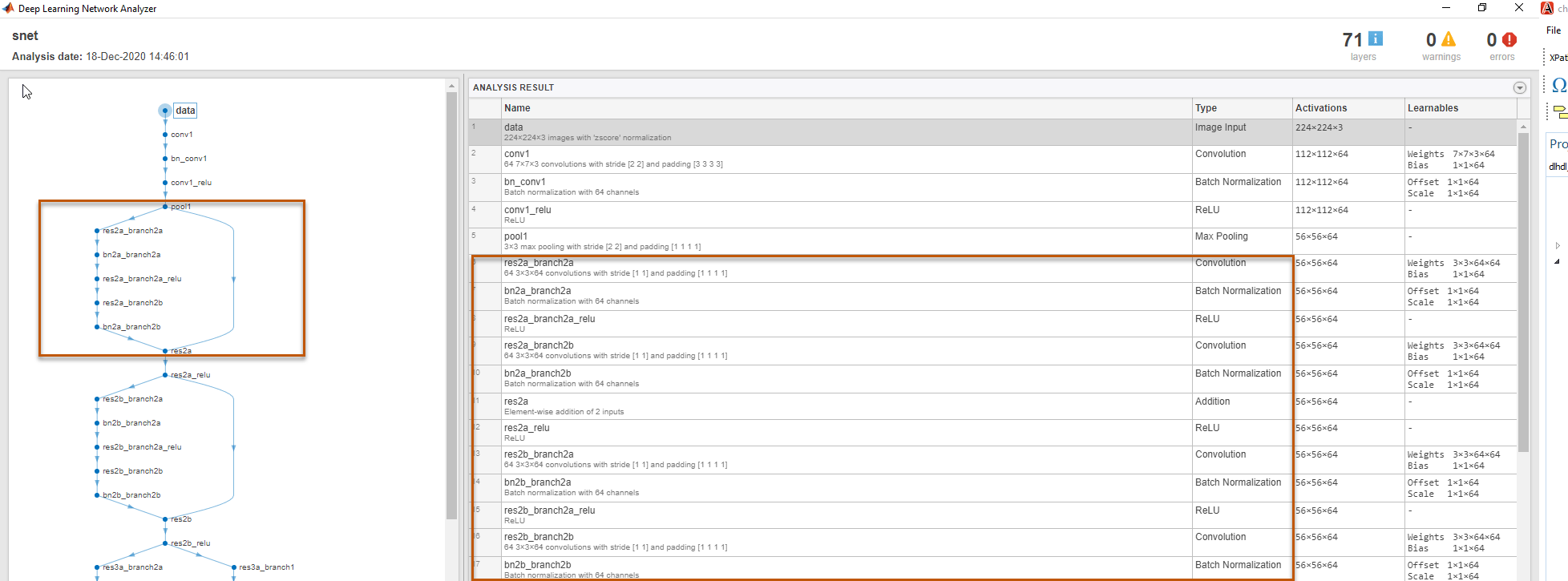
This image shows the legs of the ResNet-18 network created by the
compile function and those legs highlighted on the ResNet-18 layer
architecture.
