openl3Embeddings
Description
embeddings = openl3Embeddings(audioIn,fs)audioIn
with sample rate fs. Columns of the input are treated as individual
channels.
embeddings = openl3Embeddings(audioIn,fs,Name=Value)embeddings
= openl3Embeddings(audioIn,fs,OverlapPercentage=75) applies a 75% overlap
between consecutive frames used to create the audio embeddings.
This function requires both Audio Toolbox™ and Deep Learning Toolbox™.
Examples
Download and unzip the Audio Toolbox™ model for OpenL3.
Type openl3Embeddings at the command line. If the Audio Toolbox model for OpenL3 is not installed, the function provides a link to the location of the network weights. To download the model, click the link. Unzip the file to a location on the MATLAB® path.
Alternatively, execute the following commands to download and unzip the OpenL3 model to your temporary directory.
downloadFolder = fullfile(tempdir,"OpenL3Download"); loc = websave(downloadFolder,"https://ssd.mathworks.com/supportfiles/audio/openl3.zip"); OpenL3Location = tempdir; unzip(loc,OpenL3Location) addpath(fullfile(OpenL3Location,"openl3"))
Read in an audio file.
[audioIn,fs] = audioread('MainStreetOne-16-16-mono-12secs.wav');Call the openl3Embeddings function with the audio and sample rate to extract OpenL3 feature embeddings from the audio. Using the openl3Embeddings function requires installing the pretrained OpenL3 network. If the network is not installed, the function provides a link to download the pretrained model.
embeddings = openl3Embeddings(audioIn,fs);
The openl3Embeddings function returns a matrix of 512-element feature vectors over time.
[numHops,numElementsPerHop,numChannels] = size(embeddings)
numHops = 111
numElementsPerHop = 512
numChannels = 1
Create a 10-second pink noise signal and then extract OpenL3 embeddings. The openl3Embeddings function extracts feature embeddings from mel spectrograms with 90% overlap. Using the openl3Embeddings function requires installing the pretrained OpenL3 network. If the network is not installed, the function provides a link to download the pretrained model.
fs = 16e3;
dur = 10;
audioIn = pinknoise(dur*fs,1,"single");
embeddings = openl3Embeddings(audioIn,fs);Plot the OpenL3 feature embeddings over time.
surf(embeddings,EdgeColor="none") view([30 65]) axis tight xlabel("Feature Index") ylabel("Frame") xlabel("Feature Value") title("OpenL3 Feature Embeddings")
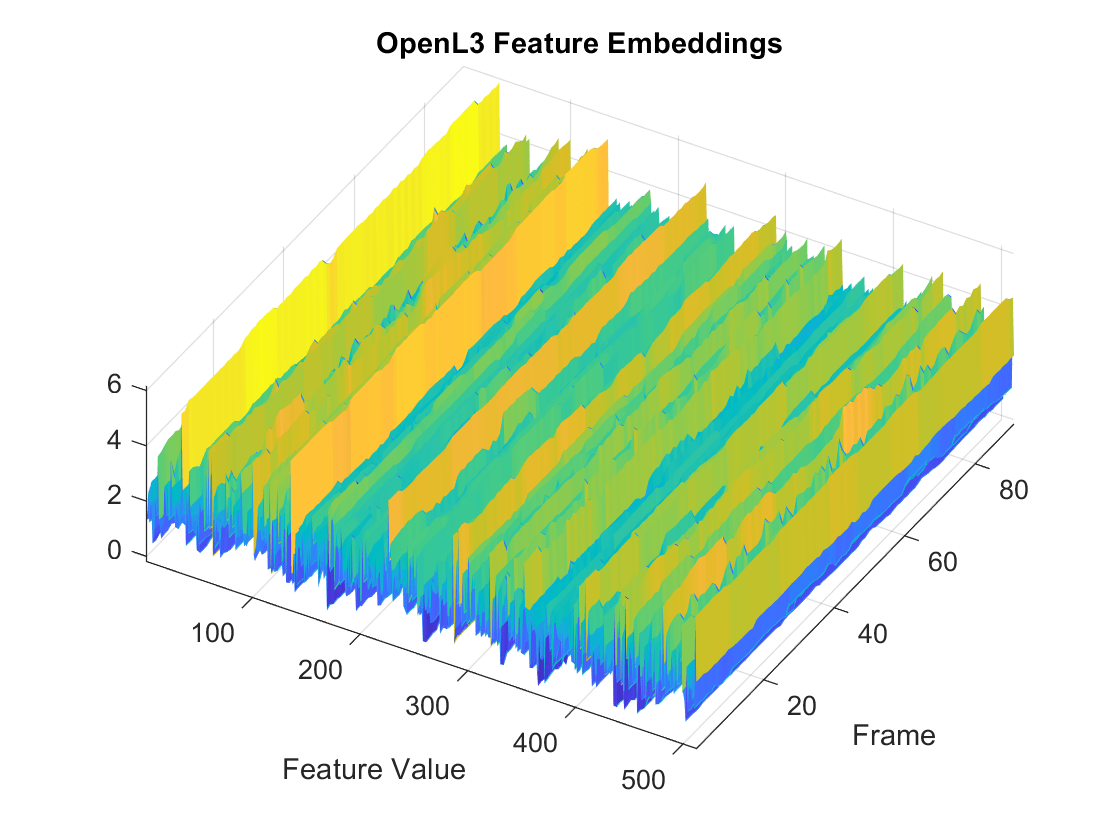
To decrease the resolution of OpenL3 feature embeddings over time, specify the percent overlap between mel spectrograms. Plot the results.
overlapPercentage =10; embeddings = openl3Embeddings(audioIn,fs,OverlapPercentage=overlapPercentage); surf(embeddings,EdgeColor="none") view([30 65]) axis tight xlabel("Feature Index") ylabel("Frame") zlabel("Feature Value") title("OpenL3 Feature Embeddings")
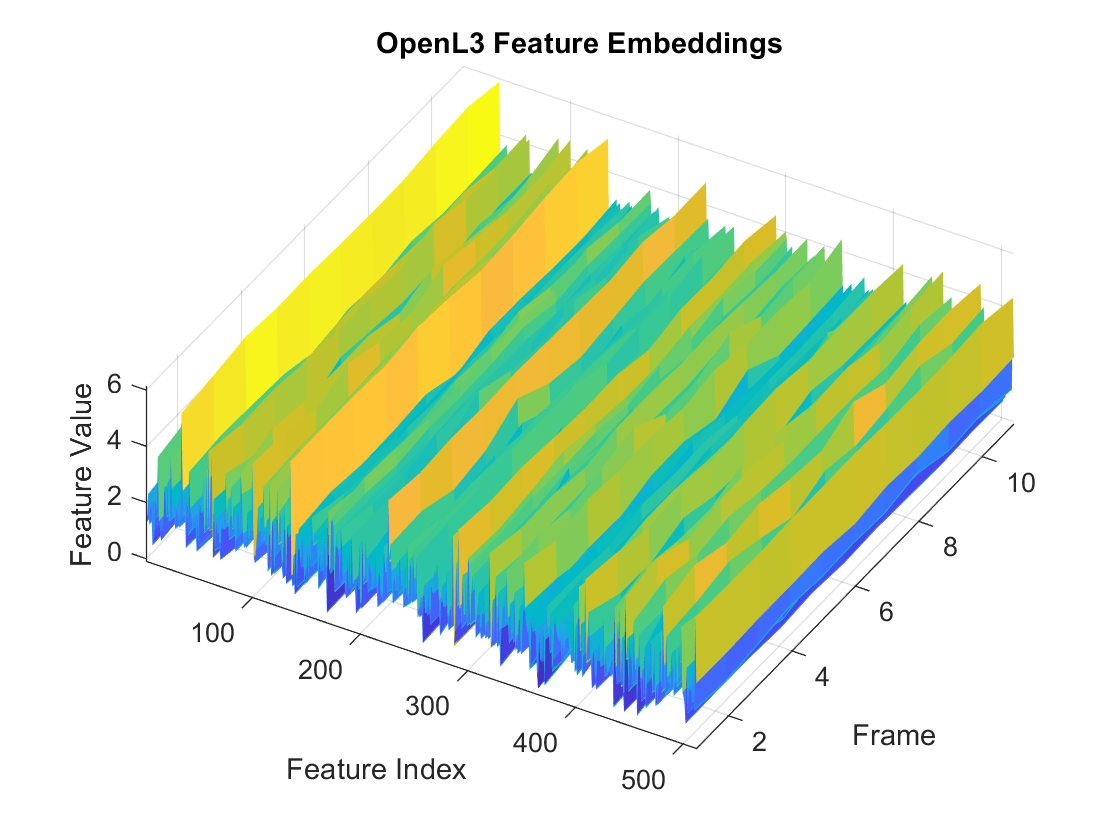
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Cramer, Jason, et al. "Look, Listen, and Learn More: Design Choices for Deep Audio Embeddings." In ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2019, pp. 3852-56. DOI.org (Crossref), doi:/10.1109/ICASSP.2019.8682475.
Extended Capabilities
Version History
Introduced in R2022a