trainClassifier
Train i-vector classifier
Description
trainClassifier(
trains the ivs,data,labels)ivectorSystem
object ivs to classify i-vectors as labels.
trainClassifier(
specifies options using one or more name-value arguments. For example,
ivs,data,labels,Name=Value)trainClassifier(ivs,data,labels,NumEigenvectors=A) specifies the number
of eigenvectors used to perform dimensionality reduction.
Examples
Use the Pitch Tracking Database from Graz University of Technology (PTDB-TUG) [1]. The data set consists of 20 English native speakers reading 2342 phonetically rich sentences from the TIMIT corpus. Download and extract the data set.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","ptdb-tug.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"ptdb-tug");
Create an audioDatastore object that points to the data set. The data set was originally intended for use in pitch-tracking training and evaluation and includes laryngograph readings and baseline pitch decisions. Use only the original audio recordings.
ads = audioDatastore([fullfile(dataset,"SPEECH DATA","FEMALE","MIC"),fullfile(dataset,"SPEECH DATA","MALE","MIC")], ... IncludeSubfolders=true, ... FileExtensions=".wav");
The file names contain the speaker IDs. Decode the file names to set the labels in the audioDatastore object.
ads.Labels = extractBetween(ads.Files,"mic_","_"); countEachLabel(ads)
ans=20×2 table
F01 236
F02 236
F03 236
F04 236
F05 236
F06 236
F07 236
F08 234
F09 236
F10 236
M01 236
M02 236
M03 236
M04 236
⋮
Read an audio file from the data set, listen to it, and plot it.
[audioIn,audioInfo] = read(ads); fs = audioInfo.SampleRate; t = (0:size(audioIn,1)-1)/fs; sound(audioIn,fs) plot(t,audioIn) xlabel("Time (s)") ylabel("Amplitude") axis([0 t(end) -1 1]) title("Sample Utterance from Data Set")
Separate the audioDatastore object into four: one for training, one for enrollment, one to evaluate the detection-error tradeoff, and one for testing. The training set contains 16 speakers. The enrollment, detection-error tradeoff, and test sets contain the other four speakers.
speakersToTest = categorical(["M01","M05","F01","F05"]); adsTrain = subset(ads,~ismember(ads.Labels,speakersToTest)); ads = subset(ads,ismember(ads.Labels,speakersToTest)); [adsEnroll,adsTest,adsDET] = splitEachLabel(ads,3,1);
Display the label distributions of the audioDatastore objects.
countEachLabel(adsTrain)
ans=16×2 table
F02 236
F03 236
F04 236
F06 236
F07 236
F08 234
F09 236
F10 236
M02 236
M03 236
M04 236
M06 236
M07 236
M08 236
countEachLabel(adsEnroll)
ans=4×2 table
F01 3
F05 3
M01 3
M05 3
countEachLabel(adsTest)
ans=4×2 table
F01 1
F05 1
M01 1
M05 1
countEachLabel(adsDET)
ans=4×2 table
F01 232
F05 232
M01 232
M05 232
Create an i-vector system. By default, the i-vector system assumes the input to the system is mono audio signals.
speakerVerification = ivectorSystem(SampleRate=fs)
speakerVerification =
ivectorSystem with properties:
InputType: 'audio'
SampleRate: 48000
DetectSpeech: 1
Verbose: 1
EnrolledLabels: [0×2 table]
To train the extractor of the i-vector system, call trainExtractor. Specify the number of universal background model (UBM) components as 128 and the number of expectation maximization iterations as 5. Specify the total variability space (TVS) rank as 64 and the number of iterations as 3.
trainExtractor(speakerVerification,adsTrain, ... UBMNumComponents=128,UBMNumIterations=5, ... TVSRank=64,TVSNumIterations=3)
Calculating standardization factors ....done. Training universal background model ........done. Training total variability space ......done. i-vector extractor training complete.
To train the classifier of the i-vector system, use trainClassifier. To reduce dimensionality of the i-vectors, specify the number of eigenvectors in the projection matrix as 16. Specify the number of dimensions in the probabilistic linear discriminant analysis (PLDA) model as 16, and the number of iterations as 3.
trainClassifier(speakerVerification,adsTrain,adsTrain.Labels, ... NumEigenvectors=16, ... PLDANumDimensions=16,PLDANumIterations=3)
Extracting i-vectors ...done. Training projection matrix .....done. Training PLDA model ......done. i-vector classifier training complete.
To calibrate the system so that scores can be interpreted as a measure of confidence in a positive decision, use calibrate.
calibrate(speakerVerification,adsTrain,adsTrain.Labels)
Extracting i-vectors ...done. Calibrating CSS scorer ...done. Calibrating PLDA scorer ...done. Calibration complete.
To inspect parameters used previously to train the i-vector system, use info.
info(speakerVerification)
i-vector system input Input feature vector length: 60 Input data type: double trainExtractor Train signals: 3774 UBMNumComponents: 128 UBMNumIterations: 5 TVSRank: 64 TVSNumIterations: 3 trainClassifier Train signals: 3774 Train labels: F02 (236), F03 (236) ... and 14 more NumEigenvectors: 16 PLDANumDimensions: 16 PLDANumIterations: 3 calibrate Calibration signals: 3774 Calibration labels: F02 (236), F03 (236) ... and 14 more
Split the enrollment set.
[adsEnrollPart1,adsEnrollPart2] = splitEachLabel(adsEnroll,1,2);
To enroll speakers in the i-vector system, call enroll.
enroll(speakerVerification,adsEnrollPart1,adsEnrollPart1.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .......done. Enrollment complete.
When you enroll speakers, the read-only EnrolledLabels property is updated with the enrolled labels and corresponding template i-vectors. The table also keeps track of the number of signals used to create the template i-vector. Generally, using more signals results in a better template.
speakerVerification.EnrolledLabels
ans=4×2 table
16×1 double 1
16×1 double 1
16×1 double 1
16×1 double 1
Enroll the second part of the enrollment set and then view the enrolled labels table again. The i-vector templates and the number of samples are updated.
enroll(speakerVerification,adsEnrollPart2,adsEnrollPart2.Labels)
Extracting i-vectors ...done. Enrolling i-vectors .......done. Enrollment complete.
speakerVerification.EnrolledLabels
ans=4×2 table
16×1 double 3
16×1 double 3
16×1 double 3
16×1 double 3
To evaluate the i-vector system and determine a decision threshold for speaker verification, call detectionErrorTradeoff.
[results, eerThreshold] = detectionErrorTradeoff(speakerVerification,adsDET,adsDET.Labels);
Extracting i-vectors ...done. Scoring i-vector pairs ...done. Detection error tradeoff evaluation complete.
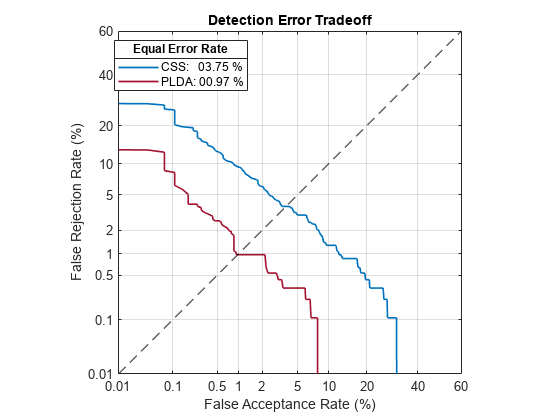
The first output from detectionErrorTradeoff is a structure with two fields: CSS and PLDA. Each field contains a table. Each row of the table contains a possible decision threshold for speaker verification tasks, and the corresponding false acceptance rate (FAR) and false rejection rate (FRR). The FAR and FRR are determined using the enrolled speaker labels and the data input to the detectionErrorTradeoff function.
results
results = struct with fields:
PLDA: [1000×3 table]
CSS: [1000×3 table]
results.CSS
ans=1000×3 table
2.3259e-10 1 0
2.3965e-10 0.9996 0
2.4693e-10 0.9993 0
2.5442e-10 0.9993 0
2.6215e-10 0.9993 0
2.7010e-10 0.9993 0
2.7830e-10 0.9993 0
2.8675e-10 0.9993 0
2.9545e-10 0.9993 0
3.0442e-10 0.9993 0
3.1366e-10 0.9993 0
3.2318e-10 0.9993 0
3.3299e-10 0.9993 0
3.4310e-10 0.9993 0
⋮
results.PLDA
ans=1000×3 table
3.2661e-40 1 0
3.6177e-40 0.9996 0
4.0072e-40 0.9996 0
4.4387e-40 0.9996 0
4.9166e-40 0.9996 0
5.4459e-40 0.9996 0
6.0322e-40 0.9996 0
6.6817e-40 0.9996 0
7.4011e-40 0.9996 0
8.1980e-40 0.9996 0
9.0806e-40 0.9996 0
1.0058e-39 0.9996 0
1.1141e-39 0.9996 0
1.2341e-39 0.9996 0
⋮
The second output from detectionErrorTradeoff is a structure with two fields: CSS and PLDA. The corresponding value is the decision threshold that results in the equal error rate (when FAR and FRR are equal).
eerThreshold
eerThreshold = struct with fields:
PLDA: 0.0398
CSS: 0.9369
The first time you call detectionErrorTradeoff, you must provide data and corresponding labels to evaluate. Subsequently, you can get the same information, or a different analysis using the same underlying data, by calling detectionErrorTradeoff without data and labels.
Call detectionErrorTradeoff a second time with no data arguments or output arguments to visualize the detection-error tradeoff.
detectionErrorTradeoff(speakerVerification)
Call detectionErrorTradeoff again. This time, visualize only the detection-error tradeoff for the PLDA scorer.
detectionErrorTradeoff(speakerVerification,Scorer="plda")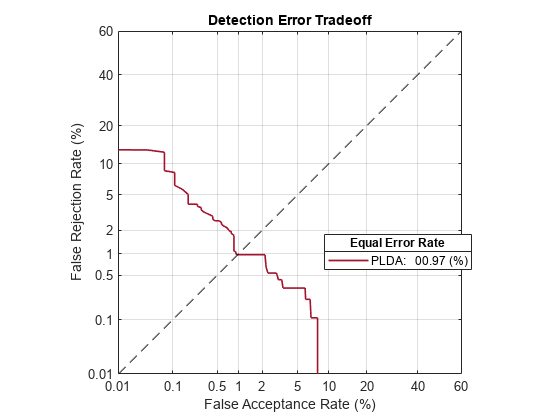
Depending on your application, you may want to use a threshold that weights the error cost of a false acceptance higher or lower than the error cost of a false rejection. You may also be using data that is not representative of the prior probability of the speaker being present. You can use the minDCF parameter to specify custom costs and prior probability. Call detectionErrorTradeoff again, this time specify the cost of a false rejection as 1, the cost of a false acceptance as 2, and the prior probability that a speaker is present as 0.1.
costFR = 1;
costFA = 2;
priorProb = 0.1;
detectionErrorTradeoff(speakerVerification,Scorer="plda",minDCF=[costFR,costFA,priorProb])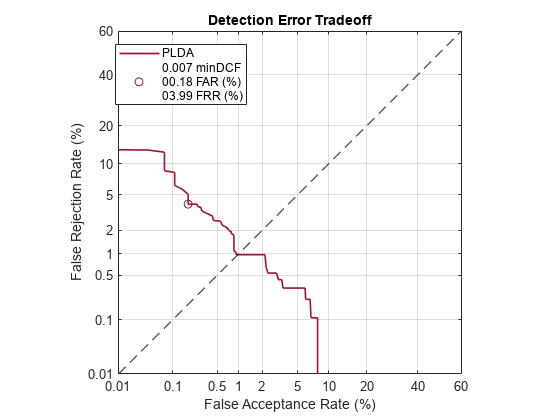
Call detectionErrorTradeoff again. This time, get the minDCF threshold for the PLDA scorer and the parameters of the detection cost function.
[~,minDCFThreshold] = detectionErrorTradeoff(speakerVerification,Scorer="plda",minDCF=[costFR,costFA,priorProb])minDCFThreshold = 0.4709
Test Speaker Verification System
Read a signal from the test set.
adsTest = shuffle(adsTest); [audioIn,audioInfo] = read(adsTest); knownSpeakerID = audioInfo.Label
knownSpeakerID = 1×1 cell array
{'F01'}
To perform speaker verification, call verify with the audio signal and specify the speaker ID, a scorer, and a threshold for the scorer. The verify function returns a logical value indicating whether a speaker identity is accepted or rejected, and a score indicating the similarity of the input audio and the template i-vector corresponding to the enrolled label.
[tf,score] = verify(speakerVerification,audioIn,knownSpeakerID,"plda",eerThreshold.PLDA); if tf fprintf('Success!\nSpeaker accepted.\nSimilarity score = %0.2f\n\n',score) else fprinf('Failure!\nSpeaker rejected.\nSimilarity score = %0.2f\n\n',score) end
Success! Speaker accepted. Similarity score = 1.00
Call speaker verification again. This time, specify an incorrect speaker ID.
possibleSpeakers = speakerVerification.EnrolledLabels.Properties.RowNames; imposterIdx = find(~ismember(possibleSpeakers,knownSpeakerID)); imposter = possibleSpeakers(imposterIdx(randperm(numel(imposterIdx),1)))
imposter = 1×1 cell array
{'M05'}
[tf,score] = verify(speakerVerification,audioIn,imposter,"plda",eerThreshold.PLDA); if tf fprintf('Failure!\nSpeaker accepted.\nSimilarity score = %0.2f\n\n',score) else fprintf('Success!\nSpeaker rejected.\nSimilarity score = %0.2f\n\n',score) end
Success! Speaker rejected. Similarity score = 0.00
References
[1] Signal Processing and Speech Communication Laboratory. https://www.spsc.tugraz.at/databases-and-tools/ptdb-tug-pitch-tracking-database-from-graz-university-of-technology.html. Accessed 12 Dec. 2019.
Input Arguments
Name-Value Arguments
Version History
Introduced in R2021a
See Also
trainExtractor | calibrate | enroll | unenroll | detectionErrorTradeoff | verify | identify | ivector | info | addInfoHeader | release | ivectorSystem | speakerRecognition