predict
Classify observations using generalized additive model (GAM)
Syntax
Description
label = predict(Mdl,X)X, based on the generalized additive model
Mdl for binary classification. The trained model can be either full
or compact.
For each observation in X, the predicted class label corresponds to
the minimum Expected Misclassification Cost.
label = predict(Mdl,X,'IncludeInteractions',includeInteractions)
Examples
Train a generalized additive model using training samples, and then label the test samples.
Load the fisheriris data set. Create X as a numeric matrix that contains sepal and petal measurements for versicolor and virginica irises. Create Y as a cell array of character vectors that contains the corresponding iris species.
load fisheriris inds = strcmp(species,'versicolor') | strcmp(species,'virginica'); X = meas(inds,:); Y = species(inds,:);
Randomly partition observations into a training set and a test set with stratification, using the class information in Y. Specify a 30% holdout sample for testing.
rng('default') % For reproducibility cv = cvpartition(Y,'HoldOut',0.30);
Extract the training and test indices.
trainInds = training(cv); testInds = test(cv);
Specify the training and test data sets.
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
Train a generalized additive model using the predictors XTrain and class labels YTrain. A recommended practice is to specify the class names.
Mdl = fitcgam(XTrain,YTrain,'ClassNames',{'versicolor','virginica'})
Mdl =
ClassificationGAM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'logit'
Intercept: -1.1090
NumObservations: 70
Properties, Methods
Mdl is a ClassificationGAM model object.
Predict the test sample labels.
label = predict(Mdl,XTest);
Create a table containing the true labels and predicted labels. Display the table for a random set of 10 observations.
t = table(YTest,label,'VariableNames',{'True Label','Predicted Label'}); idx = randsample(sum(testInds),10); t(idx,:)
ans=10×2 table
True Label Predicted Label
______________ _______________
{'virginica' } {'virginica' }
{'virginica' } {'virginica' }
{'versicolor'} {'virginica' }
{'virginica' } {'virginica' }
{'virginica' } {'virginica' }
{'versicolor'} {'versicolor'}
{'versicolor'} {'versicolor'}
{'versicolor'} {'versicolor'}
{'versicolor'} {'versicolor'}
{'virginica' } {'virginica' }
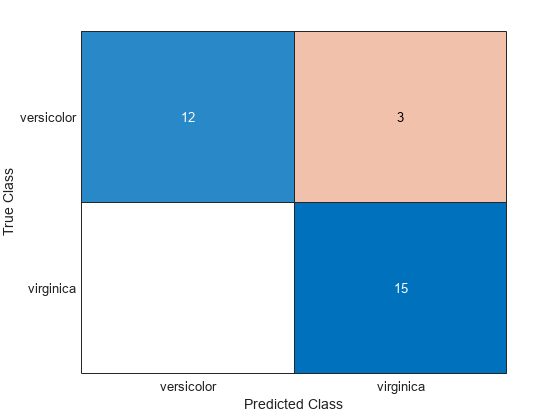
Create a confusion chart from the true labels YTest and the predicted labels label.
cm = confusionchart(YTest,label);
Estimate the logit of posterior probabilities for new observations using a classification GAM that contains both linear and interaction terms for predictors. Classify new observations using a memory-efficient model object. Specify whether to include interaction terms when classifying new observations.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionospherePartition the data set into two sets: one containing training data, and the other containing new, unobserved test data. Reserve 10 observations for the new test data set.
rng('default') % For reproducibility n = size(X,1); newInds = randsample(n,10); inds = ~ismember(1:n,newInds); XNew = X(newInds,:); YNew = Y(newInds);
Train a GAM using the predictors X and class labels Y. A recommended practice is to specify the class names. Specify to include the 10 most important interaction terms.
Mdl = fitcgam(X(inds,:),Y(inds),'ClassNames',{'b','g'},'Interactions',10);
Mdl is a ClassificationGAM model object.
Conserve memory by reducing the size of the trained model.
CMdl = compact(Mdl); whos('Mdl','CMdl')
Name Size Bytes Class Attributes CMdl 1x1 1098395 classreg.learning.classif.CompactClassificationGAM Mdl 1x1 1300464 ClassificationGAM
CMdl is a CompactClassificationGAM model object.
Predict the labels using both linear and interaction terms, and then using only linear terms. To exclude interaction terms, specify 'IncludeInteractions',false. Estimate the logit of posterior probabilities by specifying the ScoreTransform property as 'none'.
CMdl.ScoreTransform = 'none'; [labels,scores] = predict(CMdl,XNew); [labels_nointeraction,scores_nointeraction] = predict(CMdl,XNew,'IncludeInteractions',false); t = table(YNew,labels,scores,labels_nointeraction,scores_nointeraction, ... 'VariableNames',{'True Labels','Predicted Labels','Scores' ... 'Predicted Labels Without Interactions','Scores Without Interactions'})
t=10×5 table
True Labels Predicted Labels Scores Predicted Labels Without Interactions Scores Without Interactions
___________ ________________ __________________ _____________________________________ ___________________________
{'g'} {'g'} -40.23 40.23 {'g'} -37.484 37.484
{'g'} {'g'} -41.215 41.215 {'g'} -38.737 38.737
{'g'} {'g'} -44.413 44.413 {'g'} -42.186 42.186
{'g'} {'b'} 3.0658 -3.0658 {'b'} 1.4338 -1.4338
{'g'} {'g'} -84.637 84.637 {'g'} -81.269 81.269
{'g'} {'g'} -27.44 27.44 {'g'} -24.831 24.831
{'g'} {'g'} -62.989 62.989 {'g'} -60.4 60.4
{'g'} {'g'} -77.109 77.109 {'g'} -75.937 75.937
{'g'} {'g'} -48.519 48.519 {'g'} -47.067 47.067
{'g'} {'g'} -56.256 56.256 {'g'} -53.373 53.373
The predicted labels for the test data Xnew do not vary depending on the inclusion of interaction terms, but the estimated score values are different.
Train a generalized additive model, and then plot the posterior probability regions using the probability values of the first class.
Load the fisheriris data set. Create X as a numeric matrix that contains two petal measurements for versicolor and virginica irises. Create Y as a cell array of character vectors that contains the corresponding iris species.
load fisheriris inds = strcmp(species,'versicolor') | strcmp(species,'virginica'); X = meas(inds,3:4); Y = species(inds,:);
Train a generalized additive model using the predictors X and class labels Y. A recommended practice is to specify the class names.
Mdl = fitcgam(X,Y,'ClassNames',{'versicolor','virginica'});
Mdl is a ClassificationGAM model object.
Define a grid of values in the observed predictor space.
xMax = max(X); xMin = min(X); x1 = linspace(xMin(1),xMax(1),250); x2 = linspace(xMin(2),xMax(2),250); [x1Grid,x2Grid] = meshgrid(x1,x2);
Predict the posterior probabilities for each instance in the grid.
[~,PosteriorRegion] = predict(Mdl,[x1Grid(:),x2Grid(:)]);
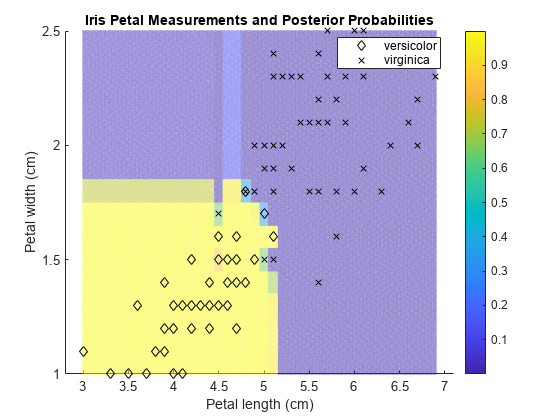
Plot the posterior probability regions using the probability values of the first class 'versicolor'.
h = scatter(x1Grid(:),x2Grid(:),1,PosteriorRegion(:,1)); h.MarkerEdgeAlpha = 0.3;
Plot the training data.
hold on gh = gscatter(X(:,1),X(:,2),Y,'k','dx'); title('Iris Petal Measurements and Posterior Probabilities') xlabel('Petal length (cm)') ylabel('Petal width (cm)') legend(gh,'Location','Best') colorbar hold off
Input Arguments
Output Arguments
More About
Version History
Introduced in R2021a
See Also
loss | margin | edge | resubPredict