이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
로지스틱 회귀 모델에 대한 베이즈 분석
이 예제에서는 slicesample을 사용하여 로지스틱 회귀 모델에 베이즈 추론을 수행하는 방법을 보여줍니다.
통계적 추론은 일반적으로 최대가능도 추정(MLE)을 기반으로 합니다. MLE는 데이터의 가능도를 최대화하는 모수를 선택하므로 직관적인 측면에서 우수합니다. MLE에서 모수는 알려지지 않았지만 고정된 것으로 간주되어 어느 정도의 신뢰수준으로 추정됩니다. 베이즈 통계에서는 알려지지 않은 모수에 대한 불확실성이 확률을 사용하여 정량화됩니다. 즉, 알려지지 않은 모수가 확률 변수로 간주됩니다.
베이즈 추론
베이즈 추론은 모델 또는 모델 모수에 대한 사전 지식을 종합하여 통계적 모델을 분석하는 과정입니다. 베이즈 추론은 다음 베이즈 정리를 기반으로 합니다.
예를 들어, 다음과 같은 정규 관측값이 있다고 가정하겠습니다.
여기서 시그마는 알려진 값이며 세타에 대한 사전분포는 다음과 같습니다.
이 식에서 하이퍼파라미터인 뮤와 타우도 알려진 값입니다. 정규분포된 관측값 X의 n개 표본을 관측하는 경우 세타에 대한 정규 켤레 사후분포를 다음과 같이 구할 수 있습니다.
다음 그래프는 세타에 대한 사전분포(Prior), 가능도(Likelihood), 사후분포(Posterior)를 보여줍니다.
rng(0,'twister'); n = 20; sigma = 50; x = normrnd(10,sigma,n,1); mu = 30; tau = 20; theta = linspace(-40, 100, 500); y1 = normpdf(mean(x),theta,sigma/sqrt(n)); y2 = normpdf(theta,mu,tau); postMean = tau^2*mean(x)/(tau^2+sigma^2/n) + sigma^2*mu/n/(tau^2+sigma^2/n); postSD = sqrt(tau^2*sigma^2/n/(tau^2+sigma^2/n)); y3 = normpdf(theta, postMean,postSD); plot(theta,y1,'-', theta,y2,'--', theta,y3,'-.') legend('Likelihood','Prior','Posterior') xlabel('\theta')

차량 실험 데이터
앞에서 살펴본 정규 평균 추론 예제와 같이 단순한 문제에서는 닫힌 형식에서 손쉽게 사후분포를 파악할 수 있습니다. 그러나, 비켤레 사전분포와 관련된 일반적인 문제에서는 사후분포를 해석적으로 계산하는 것이 어렵거나 불가능합니다. 로지스틱 회귀를 예로 살펴보겠습니다. 이 예제에서는 다양한 중량의 차량에서 주행 거리 검정에 실패한 차량의 비율을 모델링하는 데 도움이 되는 실험을 다룹니다. 데이터는 중량, 검정된 차량 수, 실패한 차량 수에 대한 관측값을 포함합니다. 중량을 변환하여 회귀 모수의 추정값에서 상관관계를 줄여 보겠습니다.
% A set of car weights weight = [2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300]'; weight = (weight-2800)/1000; % recenter and rescale % The number of cars tested at each weight total = [48 42 31 34 31 21 23 23 21 16 17 21]'; % The number of cars that have poor mpg performances at each weight poor = [1 2 0 3 8 8 14 17 19 15 17 21]';
로지스틱 회귀 모델
일반화 선형 모델의 특수한 사례인 로지스틱 회귀는 응답 변수가 이항이기 때문에 이러한 데이터에 적합합니다. 로지스틱 회귀 모델은 다음과 같이 작성할 수 있습니다.
여기서 X는 설계 행렬이고 b는 모델 모수를 포함하는 벡터입니다. MATLAB®에서는 이 방정식을 다음과 같이 작성할 수 있습니다.
logitp = @(b,x) exp(b(1)+b(2).*x)./(1+exp(b(1)+b(2).*x));
사전 지식이 있거나, 정보가 없는 일부 사전분포를 사용할 수 있으면 모델 모수에 대한 사전 확률 분포를 지정할 수 있습니다. 예를 들어, 이 예제에서는 절편 b1 및 기울기 b2에 대한 정규 사전분포를 사용하겠습니다.
prior1 = @(b1) normpdf(b1,0,20); % prior for intercept prior2 = @(b2) normpdf(b2,0,20); % prior for slope
베이즈 정리에 따라 모델 모수의 결합 사후분포는 가능도와 사전분포의 곱에 비례합니다.
post = @(b) prod(binopdf(poor,total,logitp(b,weight))) ... % likelihood * prior1(b(1)) * prior2(b(2)); % priors
참고로, 이 모델에서 사후분포의 정규화 상수는 해석적으로 파악하기 어렵습니다. 그러나, 정규화 상수를 알지 못하더라도 모델 모수의 근사 범위만 알고 있다면 사후분포를 시각화할 수 있습니다.
b1 = linspace(-2.5, -1, 50); b2 = linspace(3, 5.5, 50); simpost = zeros(50,50); for i = 1:length(b1) for j = 1:length(b2) simpost(i,j) = post([b1(i), b2(j)]); end; end; mesh(b2,b1,simpost) xlabel('Slope') ylabel('Intercept') zlabel('Posterior density') view(-110,30)
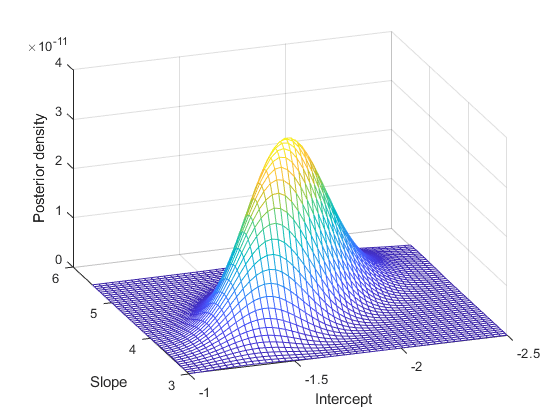
이 사후분포는 모수 공간의 대각선을 따라 길게 분포되며, 모수가 상관관계가 있음을 나타냅니다. 데이터를 수집하기 전에 데이터가 서로 독립적이라고 간주했었기 때문에 이는 흥미로운 결과입니다. 이러한 상관관계는 사전분포를 가능도 함수와 결합함으로써 얻게 됩니다.
슬라이스 표본 추출
몬테카를로 방법은 대개 베이즈 데이터 분석에서 사후분포를 요약하는 데 사용됩니다. 즉, 사후분포를 해석적으로 계산할 수 없더라도 분포에서 임의 표본을 생성하고 이러한 임의 값을 사용하여 사후분포를 추정하거나 사후 평균, 중앙값, 표준편차 등의 파생된 통계량을 추정할 수 있습니다. 슬라이스 표본 추출은 비례 상수까지밖에 모를 때 임의의 밀도 함수를 사용하여 분포에서 표본을 추출하는 것을 목적으로 하는 알고리즘입니다. 비례 상수는 정규화 상수가 알려지지 않은 복잡한 사후분포에서 표본을 추출하는 데 필요합니다. 이 알고리즘은 독립적인 표본을 생성하지 않으며, 정상 분포가 목표 분포인 마르코프 수열을 생성합니다. 따라서, 슬라이스 표집기는 마르코프 연쇄 몬테카를로(MCMC) 알고리즘입니다. 그런데, 스케일링된 사후분포만 지정해야 하고 제안 분포 또는 주변 분포는 필요로 하지 않기 때문에 잘 알려진 다른 MCMC 알고리즘과는 다릅니다.
이 예제에서는 주행 거리 검정 로지스틱 회귀 모델의 베이즈 분석의 일환으로 슬라이스 표집기를 사용하는 방법을 보여줍니다. 또한, 모델 모수에 대한 사후분포에서 임의 표본을 생성하는 과정, 표집기의 출력값을 분석하는 과정, 모델 모수에 대한 추론 과정을 보여줍니다. 첫 번째 단계는 임의 표본을 생성하는 것입니다.
initial = [1 1]; nsamples = 1000; trace = slicesample(initial,nsamples,'pdf',post,'width',[20 2]);
표집기 출력값 분석
슬라이스 표집기에서 임의 표본을 얻은 후에는 수렴 및 혼합과 같은 문제를 조사하여 표본이 목표 사후분포로부터 얻어진 임의 실현 집합으로서 타당하게 처리될 수 있는지를 확인해야 합니다. 출력값을 검토할 수 있는 가장 간단한 방법은 주변 추적 플롯을 살펴보는 것입니다.
subplot(2,1,1) plot(trace(:,1)) ylabel('Intercept'); subplot(2,1,2) plot(trace(:,2)) ylabel('Slope'); xlabel('Sample Number');

이러한 플롯을 보면 과정이 정상 과정으로 보이기 시작하기 전에 모수 시작 값의 효과가 사라질 때까지 시간이 어느 정도 필요하다(약 50개 정도의 표본)는 것을 쉽게 알 수 있습니다.
또한, 수렴 여부를 확인하기 위해 이동 윈도우를 사용하여 표본 평균, 중앙값 또는 표준편차와 같은 표본에 대한 통계량을 계산하는 것도 도움이 됩니다. 그러면 원시 표본 추적보다 더욱 매끄러운 플롯이 생성되며, 더욱 쉽게 비정상 상태를 식별하고 이해할 수 있습니다.
movavg = filter( (1/50)*ones(50,1), 1, trace); subplot(2,1,1) plot(movavg(:,1)) xlabel('Number of samples') ylabel('Means of the intercept'); subplot(2,1,2) plot(movavg(:,2)) xlabel('Number of samples') ylabel('Means of the slope');

이는 50회 반복 간의 이동평균이므로 처음 50개 값은 플롯의 나머지 부분과 비교가 불가능합니다. 그러나, 각 플롯의 나머지 부분을 통해 모수 사후 평균이 100회 정도의 반복 후 정상 상태로 수렴되었음을 확인할 수 있습니다. 또한, 앞의 사후 밀도 함수에 대한 플롯과 동일하게 두 모수가 서로 상관관계에 있다는 점을 명백히 알 수 있습니다.
정착(settling-in) 기간이 목표 분포에서 임의 실현으로서 타당하게 처리될 수 없는 표본을 나타내므로 슬라이스 표집기의 출력값 시작 부분의 처음 50개 정도의 값은 사용하지 않는 것이 바람직할 수 있습니다. 단순하게 출력값에서 이 행들을 삭제할 수 있지만, "번인(burn-in)" 기간을 지정할 수도 있습니다. 이 방법은 이전 실행 등을 통해 적합한 번인 길이를 이미 아는 경우에 편리합니다.
trace = slicesample(initial,nsamples,'pdf',post, ... 'width',[20 2],'burnin',50); subplot(2,1,1) plot(trace(:,1)) ylabel('Intercept'); subplot(2,1,2) plot(trace(:,2)) ylabel('Slope');

이러한 추적 플롯에는 비정상 상태가 표시되지 않는 것으로 보이며, 이는 번인 기간이 해당 작업을 완료했음을 나타냅니다.
그러나 추적 플롯에는 살펴봐야 할 두 번째 측면이 있습니다. 절편에 대한 추적 플롯은 고주파 잡음처럼 보이지만 기울기에 대한 추적 플롯은 더 낮은 주파수 성분을 갖는 것처럼 보이며, 이는 인접 반복에서의 값 간에 자기상관이 있음을 나타냅니다. 여전히 이 자기상관 관계에 있는 표본에서 평균을 계산할 수 있지만, 표본에서 중복된 요소를 제거하여 필요한 저장공간을 줄이는 것이 편리한 경우가 많습니다. 이를 통해 자기상관이 제거되면 이를 독립된 값 표본으로 처리할 수도 있습니다. 예를 들어, 10번째 값만 유지하여 표본을 솎아 낼 수 있습니다.
trace = slicesample(initial,nsamples,'pdf',post,'width',[20 2], ... 'burnin',50,'thin',10);
이 솎아내기(thinning) 과정의 효과를 확인하려면 추적 플롯에서 표본 자기상관 함수를 추정하고 이 추정값을 사용하여 표본이 신속하게 혼합되는지 여부를 확인하는 것이 유용합니다.
F = fft(detrend(trace,'constant')); F = F .* conj(F); ACF = ifft(F); ACF = ACF(1:21,:); % Retain lags up to 20. ACF = real([ACF(1:21,1) ./ ACF(1,1) ... ACF(1:21,2) ./ ACF(1,2)]); % Normalize. bounds = sqrt(1/nsamples) * [2 ; -2]; % 95% CI for iid normal labs = {'Sample ACF for intercept','Sample ACF for slope' }; for i = 1:2 subplot(2,1,i) lineHandles = stem(0:20, ACF(:,i) , 'filled' , 'r-o'); lineHandles.MarkerSize = 4; grid('on') xlabel('Lag') ylabel(labs{i}) hold on plot([0.5 0.5 ; 20 20] , [bounds([1 1]) bounds([2 2])] , '-b'); plot([0 20] , [0 0] , '-k'); hold off a = axis; axis([a(1:3) 1]); end

첫 번째 지연의 자기상관 값은 절편 모수에 유의미하며 기울기 모수에 대해서는 훨씬 더 유의미합니다. 상관관계를 더 줄이기 위해 더 큰 희석 모수(thinning parameter)를 사용하여 표본 추출 과정을 반복할 수 있습니다. 그러나 여기서는 이 예제의 목적에 맞게 현재 표본을 계속 사용하겠습니다.
모델 모수 추론
예상대로 표본의 히스토그램은 사후 밀도 함수의 플롯처럼 보입니다.
subplot(1,1,1) histogram2(trace(:,1),trace(:,2)); xlabel('Intercept') ylabel('Slope') zlabel('Posterior density') view(-110,30)
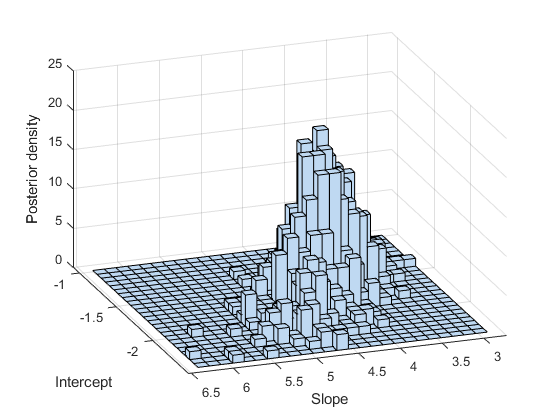
히스토그램이나 커널 평활화 밀도 추정값을 사용하여 사후 표본의 주변 분포 속성을 요약할 수 있습니다.
subplot(2,1,1) histogram(trace(:,1)) xlabel('Intercept'); subplot(2,1,2) ksdensity(trace(:,2)) xlabel('Slope');
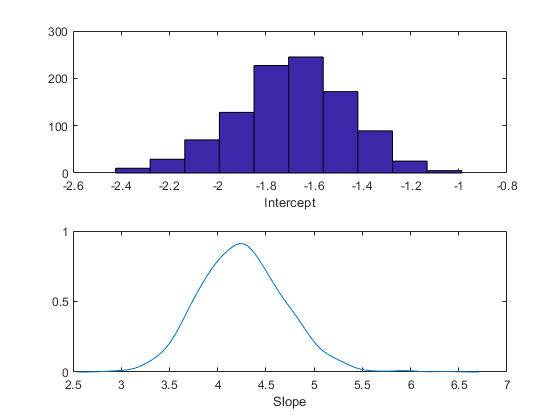
또한, 임의 표본에서 사후 평균 또는 백분위수와 같은 기술 통계량을 계산할 수도 있습니다. 표본 개수에 대한 함수로 추적 플롯의 원하는 통계량을 모니터링하면 표본 크기가 원하는 정밀도를 달성하는 데 충분히 큰지 여부를 확인하는 데 도움이 됩니다.
csum = cumsum(trace); subplot(2,1,1) plot(csum(:,1)'./(1:nsamples)) xlabel('Number of samples') ylabel('Means of the intercept'); subplot(2,1,2) plot(csum(:,2)'./(1:nsamples)) xlabel('Number of samples') ylabel('Means of the slope');

이 경우, 1000개의 표본 크기가 사후 평균 추정값에 대한 양호한 정밀도를 제공하는 데 충분해 보입니다.
bHat = mean(trace)
bHat = 1×2
-1.6931 4.2569
요약
Statistics and Machine Learning Toolbox™는 가능도와 사전분포를 손쉽게 지정할 수 있는 다양한 함수를 제공합니다. 이러한 함수를 결합하여 사후분포를 도출할 수 있습니다. slicesample 함수를 사용하면 MATLAB에서 마르코프 연쇄 몬테카를로 시뮬레이션을 사용하여 베이즈 분석을 수행할 수 있습니다. 이 함수는 표준 난수 생성기를 사용하여 표본을 추출하기 어려운 사후분포 문제에도 사용할 수 있습니다.