Recognize and Display Spoken Commands on Android Device
This example shows how to use the Simulink® Support Package for Android® Devices to deploy a deep learning algorithm that recognizes and displays commands spoken through your Android device such as a phone or tablet. This algorithm uses a deep learning convolutional neural network to recognize a given set of commands and displays them on the dashboard of the application. The algorithm used in this example is pretrained to recognize these commands: yes, no, up, down, left, right, on, off, stop, and go. The algorithm also recognizes silence and background noise.
Prerequisites
For more information on how to use the Simulink Support Package for Android Devices to run a Simulink model on your Android device, see Getting Started with Android Devices.
Download and install ARM® Compute Library using the Hardware Setup screen. This example uses ARM Compute Library version 20.02.1. To configure the ARM Compute Library in the Simulink model, see the section Configure ARM Compute Library Parameters in this example. For more information on the Hardware Setup screen, see Install Support for Android Devices.
Recognize Commands with Pretrained Network
This example uses a speech recognition network to identify speech commands. To load the network in your workspace, run this command in the MATLAB® Command Window.
load commandNet
For more information on how to download the data set or train the network, see the Train Speech Command Recognition Model Using Deep Learning (Deep Learning Toolbox) example.
Configure Simulink Model and Calibrate Parameters
Open the androidSpeechCommandRecognition Simulink model.
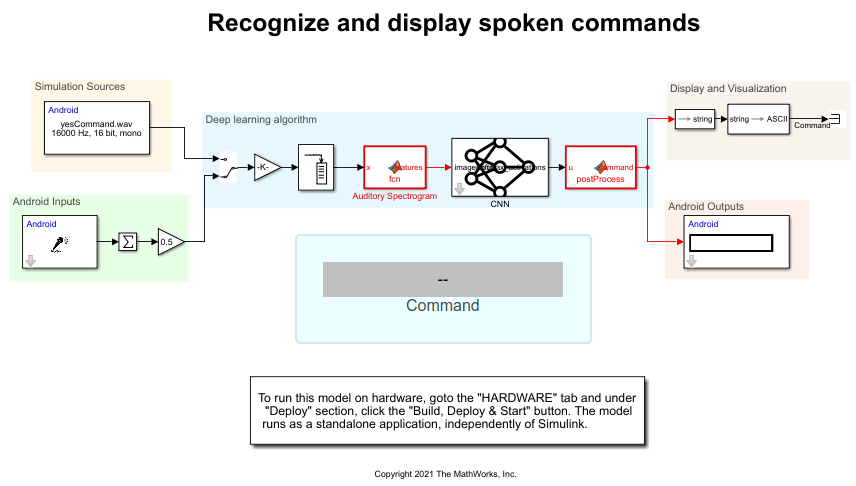
This example uses the Deep Learning template that can be found under Simulink > Simulink Start Page > Simulink Support Package for Android Devices.
Simulation Sources
This example has three prerecorded speech audios that you can use for processing.
yesCommand.wav
goCommand.wav
stopCommand.wav
From the Simulation Sources area, you can provide any one of the three WAV files to the Audio File Read block. You can also provide any prerecorded WAV or MP3 files to this block. Make sure that the audio file you record has a 16kHz sampling rate and has only one channel with the int16 datatype.
Configure these parameters in the Block Parameters dialog box of the Audio File Read block.
Set File name to
yesCommand.wav. To simulate the model for the go or stop commands, set this parameter togoCommand.wavandstopCommand.wav, respectively.Set Frame size to
400.
Android Inputs
From the Android Inputs area, capture an audio signal using a built-in microphone attached to your Android device using the Audio Capture block. The 16-bit stereo audio stream from this block is converted to the 16-bit mono audio stream.
Configure these parameters in the Block Parameters dialog box of the Audio Capture block.
Set Audio sampling frequency to
16000.Set Frame size to
400.
The Sum block adds the audio signals from the left and right channels. Configure these parameters in the Block Parameters dialog box of the Sum block.
Set Icon shape to
rectangular.Set list of signs to
+.Set Sum over to
Specified dimension.Set Dimension to
2.
The Gain block converts the stereo audio stream to the mono audio stream by dividing the output from the Sum block by two. Configure these parameters in the Block Parameters dialog box of the Gain block.
In the Main tab, set Gain to
0.5.In the Signal Attributes tab, set Output data type to
int16.
Deep Learning Algorithm
Use the Gain block to scale down the 16-bit mono audio stream to the 1-bit single datatype mono audio stream. Configure these parameters in the Block Parameters dialog box of the Gain block.
In the Main tab, set Gain to
1/2^15.In the Signal Attributes tab, set Output data type to
single.
The example uses the Buffer block to match the sampling time of the word you speak through the microphone with the algorithm sampling time. The most recent spoken word is stored in the Buffer block. Configure these parameters in the Block Parameters dialog box of the Buffer (DSP System Toolbox) block.
Set Output buffer size to
fs.Set Buffer overlap to
fs - samplesPerFrame.
The MATLAB function in the Auditory Spectrogram MATLAB Function block uses the extractSpeechFeatures function to extract features from the raw audio signal.
The Predict block from Deep Learning Toolbox™ predicts the audio speech signal using a trained deep learning neural network. Configure these parameters in the Predict (Deep Learning Toolbox) Block Parameters dialog box.
Set Network to
Network from MAT-file.Set File path to
commandNet.mat. This is the same data set file as the one generated in the Train Speech Command Recognition Model Using Deep Learning (Deep Learning Toolbox) example.Set Mini-batch size to
1.Clear Predictions.
The MATLAB function performs the postprocessing thresholding operation and predicts the maximum probability on the audio speech signal.
Display and Visualization
The predicted commands from the Deep learning algorithm area are converted from string to ASCII using the String to ASCII block and are displayed on the mobile application.
Android Outputs
The value corresponding to the command that is recognized using the neural network is displayed on the App tab of the androidSpeechCommandRecognition application.
Silence – 0
Down – 1
Go – 2
Left – 3
No – 4
Off – 5
On – 6
Right – 7
Stop –8
Up – 9
Yes – 10
Unknown – 11
Background – 12
Configure ARM Compute Library Parameters
Select a version of ARM Compute Library from the Configuration Parameters dialog box.
1. On the Hardware tab of the androidSpeechCommandRecognition Simulink model, select Configuration Parameters > Code Generation. In the Target selection section, set Language to C++.
2 Select Code Generation > Interface. In the Deep Learning section, set these parameters.
a. Set Target library to ARM Compute.
b. Set ARM Compute Library version to 20.02.1. This example supports the latest version of ARM Compute Library.
c. Set ARM Compute Library architecture to armv7.
3. Click Apply > OK.
Run Simulink Model
1. Ensure that the position of the Manual Switch in the Deep learning algorithm area is connected to the output of the Simulation Sources area.
2. Select the audio file in the Audio File Read Block Parameters dialog box. In this example, the yesCommand.wav file is selected for simulation.
3. On the Simulation tab of the Simulink model, click Run. Observe that the command Yes is displayed on the dashboard panel in the model.

Deploy Simulink on Android Device
1. Ensure that the position of the Manual Switch in the Deep learning algorithm area is connected to the output of the Android Inputs area.
2. On the Hardware tab of the Simulink model, in the Mode section, select Run on board and then click Build, Deploy & Start. The androidSpeechCommandRecognition application launches automatically.
3. Speak all the 10 commands one at a time through your Android device. On the Dashboard app, observe the command on the panel.

On the App tab of the application, observe the number corresponding to the recognized command on the panel.

The application displays Silence when you do not speak, Unknown when it does not recognize words other than the 10 words that the neural network is trained for, and Background when it detects any noise in the background.
See Also
Train Speech Command Recognition Model Using Deep Learning (Deep Learning Toolbox)
Predict (Deep Learning Toolbox)