compare
테스트 데이터를 유사성 모델의 과거 데이터 앙상블과 비교
설명
compare(___,는 하나 이상의 이름-값 쌍 인수를 사용하여 플로팅 옵션을 지정합니다.Name,Value)
예제
훈련 데이터를 불러옵니다.
load('pairwiseTrainTables.mat')훈련 데이터는 테이블로 구성된 셀형 배열입니다. 각 테이블은 컴포넌트에 대한 성능 저하 특징 프로파일입니다.
쌍별 유사성 모델을 만들고 훈련시킵니다.
mdl = pairwiseSimilarityModel; fit(mdl,pairwiseTrainTables,"Time","Condition")
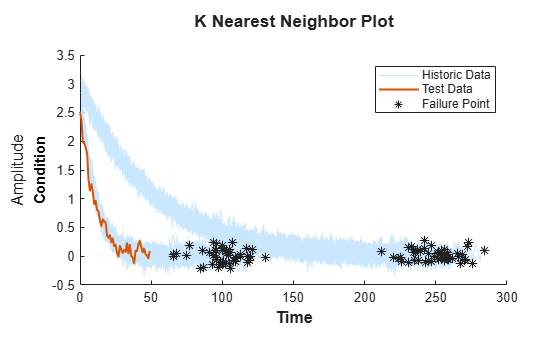
테스트 데이터를 불러옵니다.
load('pairwiseTestData.mat')테스트 데이터의 성능 저하 프로파일을 과거 데이터 앙상블의 프로파일과 비교합니다.
compare(mdl,pairwiseTestData)
훈련 데이터를 불러옵니다.
load('pairwiseTrainTables.mat')훈련 데이터는 테이블로 구성된 셀형 배열입니다. 각 테이블은 컴포넌트에 대한 성능 저하 특징 프로파일입니다.
쌍별 유사성 모델을 만들고 훈련시킵니다.
mdl = pairwiseSimilarityModel; fit(mdl,pairwiseTrainTables,"Time","Condition")
테스트 데이터를 불러옵니다.
load('pairwiseTestData.mat')테스트 데이터의 성능 저하 프로파일을 과거 데이터 앙상블의 10개의 가장 유사한 멤버 프로파일과 비교합니다.
compare(mdl,pairwiseTestData,'NumNearestNeighbors',10)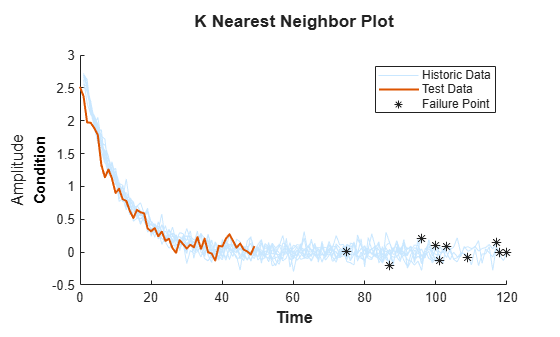
입력 인수
이름-값 인수
버전 내역
R2018a에 개발됨