centrality
노드 중요도 측정
설명
예제
가상의 웹사이트 6개를 포함하는 그래프를 생성하고 플로팅합니다.
s = [1 1 2 2 3 3 3 4 5];
t = [2 5 3 4 4 5 6 1 1];
names = {'http://www.example.com/alpha', 'http://www.example.com/beta', ...
'http://www.example.com/gamma', 'http://www.example.com/delta', ...
'http://www.example.com/epsilon', 'http://www.example.com/zeta'};
G = digraph(s,t,[],names);
plot(G,'NodeLabel',{'alpha','beta','gamma','delta','epsilon','zeta'})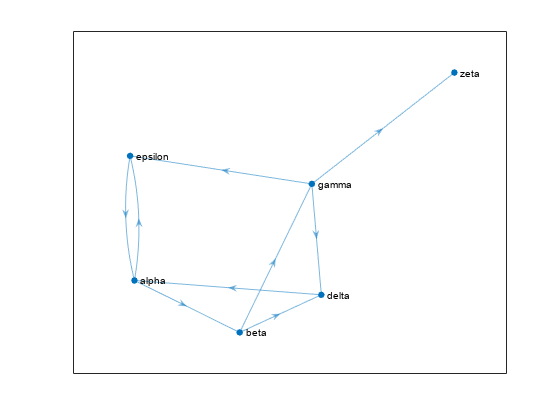
centrality 함수를 사용하여 각 웹사이트의 페이지 랭크를 계산합니다. 그래프의 Nodes 테이블에 이 정보를 그래프 노드의 특성으로 추가합니다.
pg_ranks = centrality(G,'pagerank')pg_ranks = 6×1
0.3210
0.1706
0.1066
0.1368
0.2008
0.0643
G.Nodes.PageRank = pg_ranks; G.Nodes
ans=6×2 table
Name PageRank
__________________________________ ________
{'http://www.example.com/alpha' } 0.32098
{'http://www.example.com/beta' } 0.17057
{'http://www.example.com/gamma' } 0.10657
{'http://www.example.com/delta' } 0.13678
{'http://www.example.com/epsilon'} 0.20078
{'http://www.example.com/zeta' } 0.06432
또한 centrality를 사용하여 hubs와 authorities에 해당하는 노드를 확인하고 Nodes 테이블에 점수를 추가합니다.
hub_ranks = centrality(G,'hubs'); auth_ranks = centrality(G,'authorities'); G.Nodes.Hubs = hub_ranks; G.Nodes.Authorities = auth_ranks;
G.Nodes
ans=6×4 table
Name PageRank Hubs Authorities
__________________________________ ________ __________ ___________
{'http://www.example.com/alpha' } 0.32098 0.24995 7.3237e-05
{'http://www.example.com/beta' } 0.17057 0.24995 0.099993
{'http://www.example.com/gamma' } 0.10657 0.49991 0.099993
{'http://www.example.com/delta' } 0.13678 9.1536e-05 0.29998
{'http://www.example.com/epsilon'} 0.20078 9.1536e-05 0.29998
{'http://www.example.com/zeta' } 0.06432 0 0.19999
임의의 희소 인접 행렬을 사용하여 가중 그래프(Weighted Graph)를 생성하고 플로팅합니다. 간선이 많이 있으므로 EdgeAlpha에 매우 작은 값을 사용하여 간선을 거의 투명하게 만듭니다.
A = sprand(1000,1000,0.15); A = A + A'; G = graph(A,'omitselfloops'); p = plot(G,'Layout','force','EdgeAlpha',0.005,'NodeColor','r');

각 노드의 연결 중심성을 계산합니다. 간선 가중치를 사용하여 각 간선의 중요도를 지정합니다.
deg_ranks = centrality(G,'degree','Importance',G.Edges.Weight);
discretize를 사용하여 노드 중심성 점수에 따라 간격이 같은 7개의 Bin에 노드를 배치합니다.
edges = linspace(min(deg_ranks),max(deg_ranks),7); bins = discretize(deg_ranks,edges);
플롯에서 각 노드의 크기를 해당 중심성 점수에 비례하게 만듭니다. 각 노드의 마커 크기는 Bin 숫자(1-7)와 같습니다.
p.MarkerSize = bins;

미네소타의 도로망을 나타내는 graph 객체 G가 포함된 minnesota.mat의 데이터를 불러옵니다. 그래프 노드에는 G.Nodes 테이블의 XCoord 변수와 YCoord 변수에 들어 있는 xy 좌표가 포함되어 있습니다.
load minnesota.mat
xy = [G.Nodes.XCoord G.Nodes.YCoord];도로의 길이와 대략적으로 일치하는 간선 가중치를 그래프에 추가합니다. 간선 가중치는 각 간선 끝 노드의 xy 좌표 간 유클리드 거리(Euclidean Distance)를 사용하여 계산됩니다.
[s,t] = findedge(G); G.Edges.Weight = hypot(xy(s,1)-xy(t,1), xy(s,2)-xy(t,2));
노드에 xy 좌표를 사용하여 그래프를 플로팅합니다.
p = plot(G,'XData',xy(:,1),'YData',xy(:,2),'MarkerSize',5); title('Minnesota Road Network')

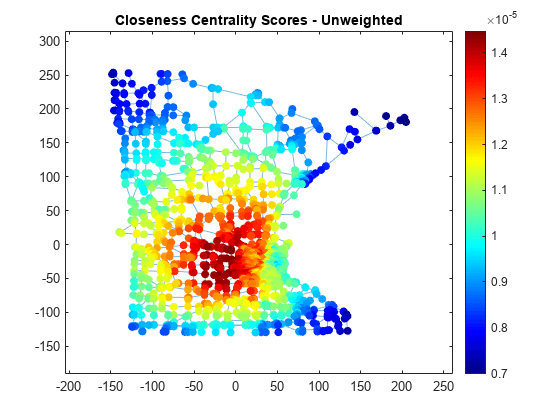
각 노드의 근접 중심성을 계산합니다. 노드 색 NodeCData를 중심성 점수에 비례하도록 스케일링합니다.
ucc = centrality(G,'closeness'); p.NodeCData = ucc; colormap jet colorbar title('Closeness Centrality Scores - Unweighted')
또한 간선 가중치를 각 간선을 순회하는 비용으로 사용하여 가중 근접 중심성 점수를 계산합니다. 이제 거리가 이동한 간선의 수가 아니라 이동한 간선 길이의 총합으로 측정되므로 도로 길이를 간선 가중치로 사용하면 점수 품질이 개선됩니다.
wcc = centrality(G,'closeness','Cost',G.Edges.Weight); p.NodeCData = wcc; title('Closeness Centrality Scores - Weighted')

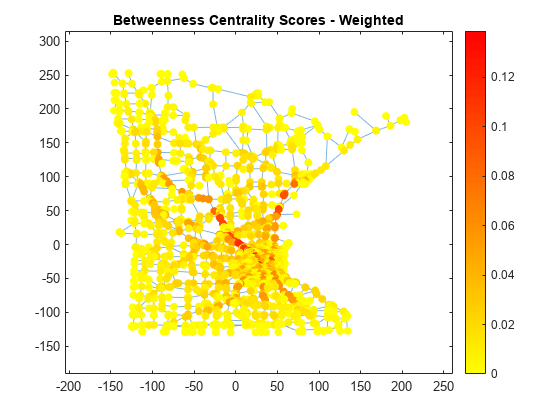
그래프의 가중 매개 중심성(Betweenness centrality) 점수를 계산하여 두 노드 간 최단 경로에서 가장 자주 발견되는 도로를 확인합니다. 인수 을 사용하여 중심성 점수를 정규화하므로 점수는 이동자(Traveler)가 임의의 두 노드 간 최단 경로를 따라 지정된 노드를 통해 이동할 확률을 나타냅니다. 플롯에는 도시로 들어오고 나가는 매우 중요한 도로가 여러 개인 것으로 나타나 있습니다.
wbc = centrality(G,'betweenness','Cost',G.Edges.Weight); n = numnodes(G); p.NodeCData = 2*wbc./((n-2)*(n-1)); colormap(flip(autumn,1)); title('Betweenness Centrality Scores - Weighted')
입력 인수
이름-값 인수
출력 인수
확장 기능
버전 내역
R2016a에 개발됨