희소 행렬 재정렬
이 예제에서는 희소 행렬의 행과 열 재정렬(Reordering) 방식이 행렬 연산의 속도와 저장 측면에 어떻게 영향을 미치는지 알아봅니다.
희소 행렬 시각화
spy 플롯은 행렬에서 0이 아닌 요소를 보여줍니다.
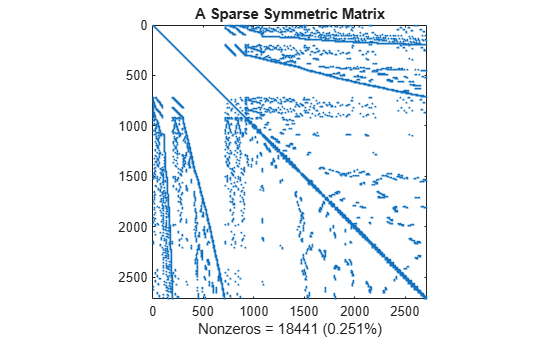
이 spy 플롯은 바벨형 행렬의 일부에서 파생된 양의 정부호 대칭 희소 행렬을 보여줍니다. 이 행렬은 바벨 모양의 그래프에 사용된 연결을 나타냅니다.
load barbellgraph.mat S = A + speye(size(A)); pct = 100 / numel(A); spy(S) title('A Sparse Symmetric Matrix') nz = nnz(S); xlabel(sprintf('Nonzeros = %d (%.3f%%)',nz,nz*pct));
바벨형 그래프의 플롯은 다음과 같습니다.
G = graph(S,'omitselfloops'); p = plot(G,'XData',xy(:,1),'YData',xy(:,2),'Marker','.'); axis equal
촐레스키 인수(Cholesky Factor) 계산
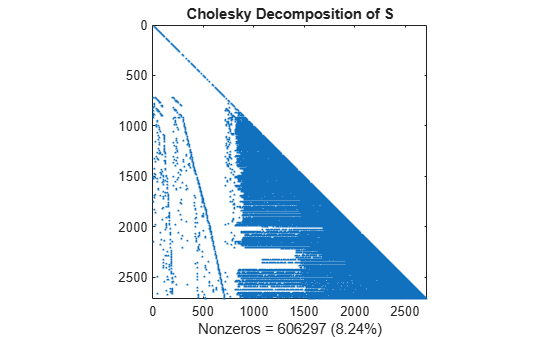
촐레스키 인수 L을 계산해 보겠습니다(여기서 S = L*L'). 이때 L은 행렬 분해되지 않은 상태의 S보다 0이 아닌 요소를 더 많이 포함하고 있습니다. 왜냐하면 촐레스키 분해를 계산하면 필인(Fill-in)으로 0이 아닌 요소가 생성되기 때문입니다. 이 필인(Fill-in) 값으로 인해 알고리즘 실행 속도가 저하되고 저장 비용이 증가합니다.
L = chol(S,'lower'); spy(L) title('Cholesky Decomposition of S') nc(1) = nnz(L); xlabel(sprintf('Nonzeros = %d (%.2f%%)',nc(1),nc(1)*pct));
계산 속도 개선을 위한 재정렬
행렬의 행과 열을 재정렬하면 행렬 분해를 통해 생성되는 필인 요소의 개수를 줄여서 후속 계산에 소요되는 시간과 저장 비용을 절감할 수도 있습니다.
다음은 MATLAB®에서 지원하는 여러 가지 재정렬 방법입니다.
colperm: 열 개수symrcm: 컷힐-맥키 역치환amd: 최소 차수dissect: 중첩 분할
바벨형 행렬에서 이 희소 행렬 재정렬 방법들의 효과를 테스트해 보겠습니다.
열 개수 재정렬
colperm 명령은 열 개수 재정렬 알고리즘을 사용하여 0이 아닌 요소의 개수가 많은 행과 열을 행렬의 끝 쪽으로 이동시킵니다.
q = colperm(S); spy(S(q,q)) title('S(q,q) After Column Count Ordering') nz = nnz(S); xlabel(sprintf('Nonzeros = %d (%.3f%%)',nz,nz*pct));
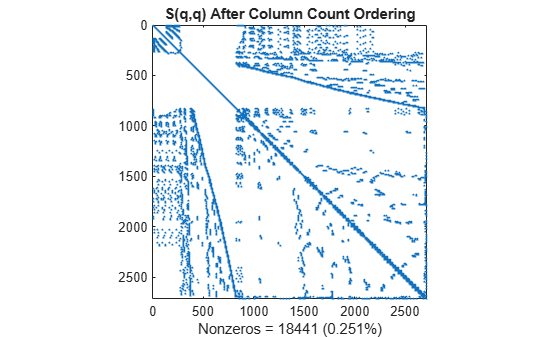
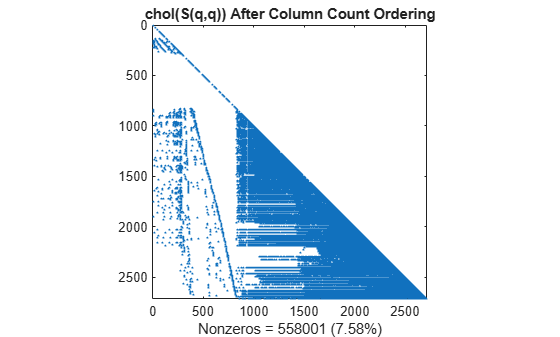
이 행렬에서는 열 개수 정렬을 수행해도 촐레스키 분해에 드는 시간과 저장공간을 거의 줄일 수 없습니다.
L = chol(S(q,q),'lower'); spy(L) title('chol(S(q,q)) After Column Count Ordering') nc(2) = nnz(L); xlabel(sprintf('Nonzeros = %d (%.2f%%)',nc(2),nc(2)*pct));
컷힐-맥키 역치환 재정렬
symrcm 명령은 컷힐-맥키 역치환 재정렬 알고리즘을 사용하여 0이 아닌 모든 요소를 대각선에 더 가까운 위치로 이동시켜 원본 행렬의 대역폭을 줄여 줍니다.
d = symrcm(S); spy(S(d,d)) title('S(d,d) After Cuthill-McKee Ordering') nz = nnz(S); xlabel(sprintf('Nonzeros = %d (%.3f%%)',nz,nz*pct));
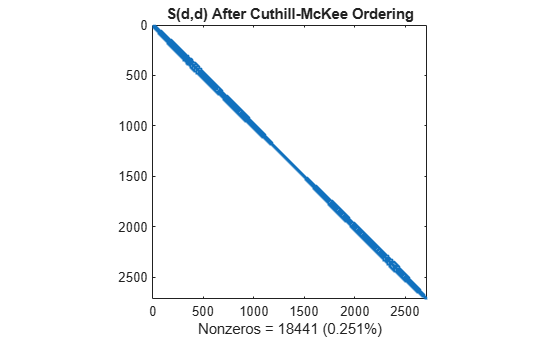
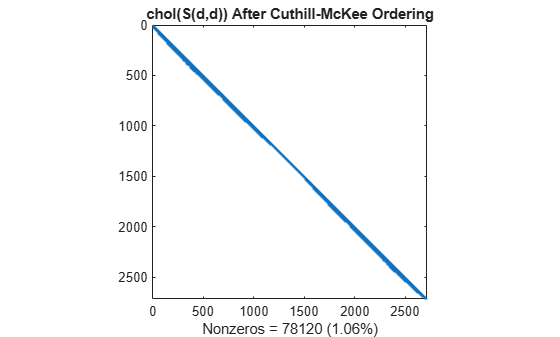
촐레스키 분해에 의해 생성되는 필인이 대역 범위 내로 국한되기 때문에 재정렬된 행렬을 분해할 때 시간과 저장공간이 적게 소요됩니다.
L = chol(S(d,d),'lower'); spy(L) title('chol(S(d,d)) After Cuthill-McKee Ordering') nc(3) = nnz(L); xlabel(sprintf('Nonzeros = %d (%.2f%%)', nc(3),nc(3)*pct));
최소 차수 재정렬
amd 명령은 그래프 이론에서 사용되는 강력한 기법인 AMD(Approximate Minimum Degree) 알고리즘을 사용하여 행렬에서 0으로 구성된 큰 블록을 생성합니다.
r = amd(S); spy(S(r,r)) title('S(r,r) After Minimum Degree Ordering') nz = nnz(S); xlabel(sprintf('Nonzeros = %d (%.3f%%)',nz,nz*pct));
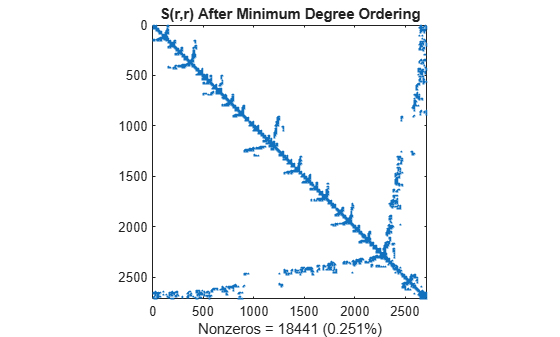
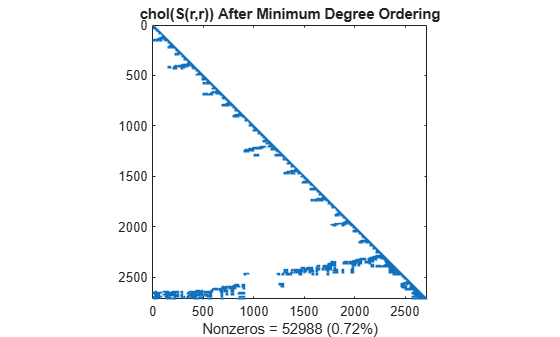
촐레스키 분해는 MD(Minimum Degree) 알고리즘이 생성한 0으로 구성된 블록을 그대로 유지합니다. 따라서 이 구조는 시간과 저장 비용을 크게 줄일 수 있습니다.
L = chol(S(r,r),'lower'); spy(L) title('chol(S(r,r)) After Minimum Degree Ordering') nc(4) = nnz(L); xlabel(sprintf('Nonzeros = %d (%.2f%%)',nc(4),nc(4)*pct));
중첩 분할 치환
dissect 함수는 그래프 이론에서 사용되는 기법을 사용하여 필인(fill-in) 감소 정렬을 생성합니다. 이 알고리즘은 행렬을 그래프의 인접 행렬로 처리하고, 정점과 간선을 축소하여 그래프의 밀도를 줄이고, 작아진 그래프를 재정렬한 다음, 미세 조정 단계를 사용하여 작은 그래프의 밀도를 되돌려 원래 그래프의 재정렬을 도출합니다. 그 결과 다른 재정렬 알고리즘에 비해 높은 빈도로 가장 적은 양의 필인을 생성하는 강력한 알고리즘이 됩니다.
p = dissect(S); spy(S(p,p)) title('S(p,p) After Nested Dissection Ordering') nz = nnz(S); xlabel(sprintf('Nonzeros = %d (%.3f%%)',nz,nz*pct));
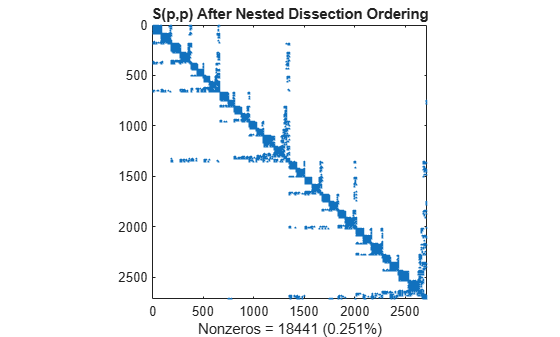
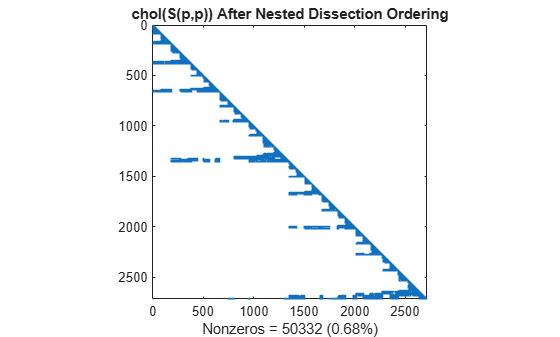
최소 차수 정렬처럼 중첩 분할 정렬의 촐레스키 분해는 주대각선 아래에서 S(d,d)의 0이 아닌 요소의 구조를 대부분 유지합니다.
L = chol(S(p,p),'lower'); spy(L) title('chol(S(p,p)) After Nested Dissection Ordering') nc(5) = nnz(L); xlabel(sprintf('Nonzeros = %d (%.2f%%)',nc(5),nc(5)*pct));
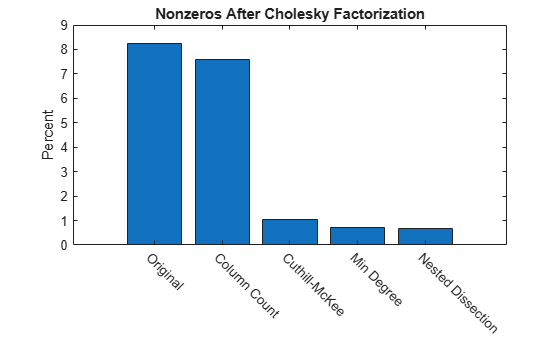
결과 요약하기
다음 막대 차트에는 촐레스키 분해를 수행하기 전 행렬 재정렬의 효과가 요약되어 있습니다. 원래 행렬에 촐레스키 분해를 사용하면 0이 아닌 요소의 밀도가 약 8%인 반면, dissect 또는 symamd를 사용하면 이 밀도가 1% 미만으로 줄어듭니다.
labels = {'Original','Column Count','Cuthill-McKee',...
'Min Degree','Nested Dissection'};
bar(nc*pct)
title('Nonzeros After Cholesky Factorization')
ylabel('Percent');
ax = gca;
ax.XTickLabel = labels;
ax.XTickLabelRotation = -45;