map 함수 쓰기
MapReduce에서 map 함수의 역할
mapreduce에는 데이터 블록을 받아 중간 결과를 출력하는 입력 map 함수와 중간 결과를 읽고 최종 결과를 생성하는 입력 reduce 함수가 모두 필요합니다. 따라서, map 함수와 reduce 함수가 개별적으로 처리되도록 계산을 관련된 두 부분으로 나누는 것이 일반적입니다. 예를 들어, 데이터 세트에서 최댓값을 구하는 경우 map 함수가 입력 데이터의 각 블록에서 최댓값을 구한 후 reduce 함수가 중간 결과로 구한 모든 최댓값 중에서 가장 큰 최댓값 하나를 구할 수 있습니다.
다음 그림은 mapreduce 알고리즘의 Map 단계를 보여줍니다.
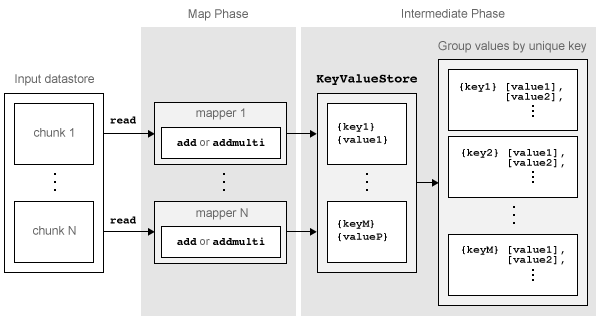
mapreduce 알고리즘의 Map 단계는 다음 단계로 구성됩니다.
mapreduce가 입력 데이터저장소에서read함수를 사용하여 단일 데이터 블록을 읽은 후 map 함수를 호출하여 블록에 대한 작업을 수행합니다.그런 다음 map 함수가 개별 데이터 블록에 대해 작업을 수행하고
add함수 또는addmulti함수를 사용하여 하나 이상의 키-값 쌍을 중간KeyValueStore객체에 추가합니다.mapreduce는 데이터 블록 수만큼 map 함수를 호출하면서 입력 데이터저장소의 각 데이터 블록에 대해 이 과정을 반복합니다. 데이터저장소의ReadSize속성에 따라 데이터 블록 개수가 결정됩니다.
map 함수가 입력 데이터저장소의 각 데이터 블록을 처리하면 mapreduce 알고리즘의 Map 단계가 완료됩니다. mapreduce 알고리즘에서 이 단계의 결과는 map 함수에 의해 추가된 모든 키-값 쌍을 포함하는 KeyValueStore 객체입니다. Map 단계 후 mapreduce는 고유 키를 기준으로 KeyValueStore 객체의 모든 값을 그룹화하여 Reduce 단계를 준비합니다.
map 함수의 요건
mapreduce는 입력 데이터저장소의 각 데이터 블록에 대해 map 함수를 자동으로 호출합니다. 이렇게 자동으로 호출되는 동안 map 함수가 제대로 실행되려면 특정 기본 요건을 충족해야 합니다. 이러한 요건은 함께 작동하여 mapreduce 알고리즘의 Map 단계를 통해 데이터가 올바로 이동되도록 합니다.
map 함수에 대한 입력값이 data, info, intermKVStore여야 합니다.
data와info는 입력 데이터저장소에서read함수를 호출한 결과입니다. 이 함수는 map 함수를 호출하기 전마다mapreduce가 자동으로 실행합니다.intermKVStore는 map 함수가 키-값 쌍을 추가해야 하는 중간KeyValueStore객체의 이름입니다.add함수와addmulti함수가 이 객체 이름을 사용하여 키-값 쌍을 추가합니다. map 함수가intermKVStore객체에 어떠한 키-값 쌍도 추가하지 않으면mapreduce는 reduce 함수를 호출하지 않으며, 결과로 생성된 데이터저장소는 비어 있게 됩니다.
map 함수에 대한 이러한 기본 요건 외에 map 함수에 의해 추가된 키-값 쌍도 다음 조건을 충족해야 합니다.
키는 숫자형 스칼라, 문자형 벡터 또는 string형이어야 합니다. 숫자형 키는
NaN, 복소수형, 논리형, 희소 형식일 수 없습니다.map 함수에 의해 추가된 모든 키는 동일한 클래스를 가져야 합니다.
값은 모든 유효한 MATLAB® 데이터형을 포함하는 모든 MATLAB 객체일 수 있습니다.
참고
다른 제품에서 mapreduce를 사용할 경우 위의 키-값 쌍 요구 사항이 다를 수 있습니다. 제품별 키-값 쌍 요구 사항을 알아보려면 해당 제품의 설명서를 참조하십시오.
샘플 map 함수
다음은 mapreduce 예제에 사용된 몇 가지 map 함수를 보여줍니다.
항등 map 함수
mapreduce가 전달하는 항목을 단순히 반환하는 map 함수를 항등 매퍼라고 합니다. 항등 매퍼는 reduce 함수에서 계산을 수행하기 전에 고유 키를 기준으로 값을 그룹화하는 데 유용합니다. identityMapper 매퍼 파일은 예제 Tall Skinny QR (TSQR) Matrix Factorization Using MapReduce에 사용된 매퍼 중 하나입니다.
function identityMapper(data, info, intermKVStore) % This mapper function simply copies the data and add them to the % intermKVStore as intermediate values. x = data.Value{:,:}; add(intermKVStore,'Identity', x); end
단순 map 함수
비항등 매퍼에 대한 가장 단순한 예제 중 하나는 maxArrivalDelayMapper로, 예제 MapReduce로 최댓값 찾기에 사용된 매퍼입니다. 이 매퍼는 각 입력 데이터 청크에 대해 최대 도착 지연 시간을 계산하고 키-값 쌍을 중간 KeyValueStore에 추가합니다.
function maxArrivalDelayMapper (data, info, intermKVStore) partMax = max(data.ArrDelay); add(intermKVStore, 'PartialMaxArrivalDelay',partMax); end
고급 map 함수
매퍼에 대한 고급 예제는 statsByGroupMapper로, 예제 Compute Summary Statistics by Group Using MapReduce에 사용된 매퍼입니다. 이 매퍼는 중첩 함수를 사용하여 각 입력 데이터 청크에 대한 여러 통계량(도수, 평균, 분산 등)을 계산한 후 여러 키-값 쌍을 중간 KeyValueStore 객체에 추가합니다. 또한, mapreduce는 3개의 입력 인수를 갖는 하나의 map 함수만 받는 데 비해 이 매퍼는 4개의 입력 인수를 사용합니다. 이를 확인하기 위해 이 예제에 설명된 대로 mapreduce에 대한 호출 중에 익명 함수를 사용하여 추가 파라미터를 전달해 보겠습니다.
function statsByGroupMapper(data, ~, intermKVStore, groupVarName) % Data is a n-by-3 table. Remove missing values first delays = data.ArrDelay; groups = data.(groupVarName); notNaN =~isnan(delays); groups = groups(notNaN); delays = delays(notNaN); % Find the unique group levels in this chunk [intermKeys,~,idx] = unique(groups, 'stable'); % Group delays by idx and apply @grpstatsfun function to each group intermVals = accumarray(idx,delays,size(intermKeys),@grpstatsfun); addmulti(intermKVStore,intermKeys,intermVals); function out = grpstatsfun(x) n = length(x); % count m = sum(x)/n; % mean v = sum((x-m).^2)/n; % variance s = sum((x-m).^3)/n; % skewness without normalization k = sum((x-m).^4)/n; % kurtosis without normalization out = {[n, m, v, s, k]}; end end
참고 항목
mapreduce | tabularTextDatastore | add | addmulti | KeyValueStore