이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
MapReduce 시작하기
해마다 데이터 수집 장치가 늘어나고 다양해짐에 따라 수집되는 데이터의 크기와 수집 속도도 가파르게 증가하고 있습니다. 이러한 빅데이터 세트는 기가바이트 또는 테라바이트급의 데이터를 담고 있을 수 있으며 하루에도 메가바이트 또는 기가바이트 단위로 증가할 수 있습니다. 이렇게 수집된 정보는 통찰력을 얻을 수 있는 가능성을 주기도 하지만, 동시에 많은 어려움을 주기도 합니다. 대다수 알고리즘은 빅데이터 세트를 적절한 시간 내에 적절한 메모리 양을 사용하여 처리하도록 설계되어 있지 않습니다. MapReduce는 이러한 많은 어려움을 해결하여 대규모 데이터 세트에서 중요한 통찰력을 얻을 수 있게 해 줍니다.
MapReduce란?
MapReduce는 메모리에 담을 수 없을 정도로 큰 데이터 세트를 분석하기 위한 프로그래밍 기법입니다. 많은 사람에게 친숙한 Hadoop® MapReduce는 HDFS™(Hadoop Distributed File System)와 함께 작동하는 인기 있는 구현 버전입니다. MATLAB®은 mapreduce 함수를 사용하여 MapReduce 기법을 약간 다르게 구현해 제공합니다.
mapreduce는 데이터저장소를 사용해서 데이터를 메모리에 담을 수 있는 각각의 작은 블록으로 나눠 처리합니다. 각 블록은 처리할 데이터의 형식을 지정하는 Map 단계를 거칩니다. Map 단계를 거친 데이터 블록은 Map 단계에서 얻은 중간 결과들을 집계해 하나의 최종 결과를 산출하는 Reduce 단계를 거칩니다. Map 단계와 Reduce 단계는 map 함수와 reduce 함수로 인코딩되는데, 이 두 함수는 mapreduce에 대한 기본 입력값입니다. 데이터를 처리할 때 이 map 함수와 reduce 함수를 얼마든지 다양하게 조합할 수 있기 때문에, MapReduce 기법을 통해 유연하면서도 강력하게 대규모 데이터 처리 작업을 해결할 수 있습니다.
mapreduce는 그 자체가 여러 환경에서 실행되도록 확장됩니다. 이러한 기능에 대한 자세한 내용은 Speed Up and Deploy MapReduce Using Other Products 항목을 참조하십시오.
mapreduce 함수가 유용한 까닭은 대규모로 수집된 데이터를 계산할 수 있기 때문입니다. 따라서 일반적인 규모의 데이터 세트를 계산할 때에는 mapreduce가 적합하지 않습니다. 이러한 규모의 데이터 세트는 컴퓨터 메모리로 직접 불러와서 전통적 기법으로 분석할 수 있기 때문입니다. 대신, 메모리에 담을 수 없는 데이터 세트에 대해 통계 계산이나 분석 계산을 할 때 mapreduce를 사용하십시오.
mapreduce가 map 함수 또는 reduce 함수를 호출할 때 각 호출은 다른 모든 요소에 관계없이 수행됩니다. 예를 들어, map 함수 호출은 이전 map 함수 호출에서 얻은 입력값 또는 결과에 영향을 받지 않습니다. 그러한 계산은 mapreduce를 여러 번 호출하여 분할하는 것이 가장 좋습니다.
MapReduce 알고리즘 단계
mapreduce는 입력 데이터저장소에 있는 각 데이터 블록에 몇 가지 단계를 적용하여 최종 출력값에 도달합니다. 다음은 mapreduce 알고리즘 단계를 간략히 나타낸 그림입니다.
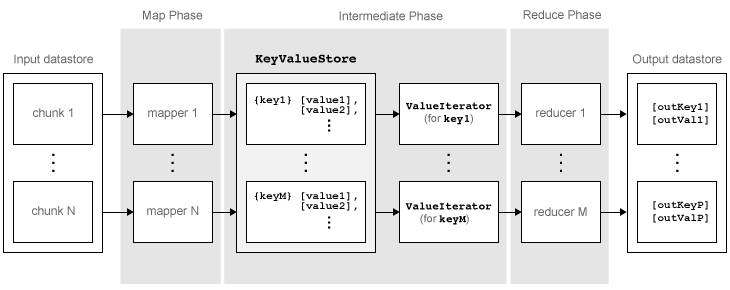
알고리즘은 다음 단계로 구성됩니다.
mapreduce가[data,info] = read(ds)를 사용하여 입력 데이터저장소에서 데이터 블록을 읽어온 다음, 해당 블록에 대해 작업할 map 함수를 호출합니다.map 함수가 데이터 블록을 받거나 구성하거나 예비 계산을 수행한 다음,
add함수와addmulti함수를 사용하여 키-값 쌍을 중간 데이터 저장공간 객체인KeyValueStore에 추가합니다.mapreduce가 map 함수를 호출하는 횟수는 입력 데이터저장소의 블록 수와 같습니다.map 함수가 데이터저장소에 있는 모든 데이터 블록에 대해 작업하고 나면,
mapreduce가 모든 값을 중간KeyValueStore객체에 고유 키별로 그룹화합니다.그런 다음
mapreduce는 map 함수에 의해 추가된 각 고유 키에 대해 reduce 함수를 한 번씩 호출합니다. 각 고유 키에는 많은 값이 연결되어 있을 수 있습니다.mapreduce는 그 값들을 reduce 함수에ValueIterator객체(값을 반복해서 처리하기 위해 사용됨)로 전달합니다. 각 고유 키에 대한ValueIterator객체에는 해당 키에 연결된 모든 값이 포함되어 있습니다.reduce 함수는
hasnext함수와getnext함수를 사용하여ValueIterator객체에 있는 값에 한 번씩 반복됩니다. 그런 다음 reduce 함수는 map 함수에서 얻은 중간 결과를 집계한 후, 최종 키-값 쌍을add함수와addmulti함수를 사용하여 출력값에 추가합니다. 출력값의 키 순서는 reduce 함수가 최종KeyValueStore객체에 키를 추가한 순서와 동일합니다. 즉,mapreduce는 출력값을 명시적으로 정렬하지 않습니다.참고
reduce 함수는 최종 키-값 쌍을 최종
KeyValueStore객체에 씁니다.mapreduce는 이 객체에서 키-값 쌍을 출력 데이터저장소로 끌어옵니다(Pull). 이 데이터저장소는 기본적으로KeyValueDatastore객체입니다.
예제 MapReduce 계산
이 예제에서는 간단한 계산(항공편 데이터 세트에서의 평균 비행 거리)으로 mapreduce를 실행하는 데 필요한 단계를 설명합니다.
데이터 준비하기
mapreduce를 사용하기 위한 첫 번째 단계는 데이터 세트용 데이터저장소를 생성하는 것입니다. map 함수 및 reduce 함수와 더불어 데이터 세트용 데이터저장소는 mapreduce에 대한 필수 입력값이며, 데이터저장소가 있어야 mapreduce가 데이터를 블록으로 나누어 처리할 수 있습니다.
mapreduce는 대부분의 데이터저장소 유형에서 작동합니다. 예를 들어, airlinesmall.csv 데이터 세트에 대한 TabularTextDatastore 객체를 생성합니다.
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA')
ds =
TabularTextDatastore with properties:
Files: {
' ...\matlab\toolbox\matlab\demos\airlinesmall.csv'
}
Folders: {
' ...\matlab\toolbox\matlab\demos'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
PreserveVariableNames: false
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: 'NA'
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"앞에 설명된 옵션 중 몇몇 옵션은 mapreduce의 맥락에서 유용합니다. mapreduce 함수는 map 함수에 전달할 데이터를 가져오기 위해 데이터저장소에서 read를 실행합니다. 따라서 사용자가 SelectedVariableNames, SelectedFormats 및 ReadSize 옵션을 사용하여, mapreduce가 map 함수에 전달할 데이터의 블록 크기와 유형을 직접 구성할 수 있습니다.
예를 들어, Distance(총 비행 거리) 변수를 유일한 관심 변수로 선택하려면 SelectedVariableNames를 지정하십시오.
ds.SelectedVariableNames = 'Distance';이제 read, readall 또는 preview 함수가 ds에서 실행될 때마다 함수는 Distance 변수에 대한 정보만 반환합니다. 이 정보는 데이터저장소에 있는 데이터의 처음 몇 개 행을 미리 보아 확인할 수 있습니다. 미리보기를 통해 mapreduce 함수가 map 함수에 전달할 데이터의 형식도 살펴볼 수 있습니다.
preview(ds)
ans =
8×1 table
Distance
________
308
296
480
296
373
308
447
954 mapreduce가 map 함수에 전달할 정확한 데이터를 보려면 read를 사용하십시오.
사용 가능한 옵션에 대한 추가 정보와 전체 개요를 보려면 데이터저장소 항목을 참조하십시오.
Map 함수와 Reduce 함수 작성하기
mapreduce 함수는 실행되는 동안 map 함수와 reduce 함수를 자동으로 호출합니다. 따라서 두 함수는 올바로 실행되기 위해 특정 요구 사항을 만족해야 합니다.
map 함수에 대한 입력값이
data,info,intermKVStore여야 합니다.data와info는 입력 데이터저장소에서read함수를 호출한 결과입니다. 이 함수는 map 함수를 호출하기 전마다mapreduce가 자동으로 실행합니다.intermKVStore는 map 함수가 키-값 쌍을 추가해야 하는 중간KeyValueStore객체의 이름입니다.add함수와addmulti함수가 이 객체 이름을 사용하여 키-값 쌍을 추가합니다. map 함수를 호출해도intermKVStore에 키-값 쌍이 전혀 추가되지 않으면mapreduce는 reduce 함수를 호출하지 않으며, 결과로 생성된 데이터저장소는 비어 있게 됩니다.
다음은 map 함수에 대한 간단한 예제입니다.
function MeanDistMapFun(data, info, intermKVStore) distances = data.Distance(~isnan(data.Distance)); sumLenValue = [sum(distances) length(distances)]; add(intermKVStore, 'sumAndLength', sumLenValue); end
이 map 함수는 세 개의 라인만으로 구성되고, 각 라인은 단순한 역할을 수행합니다. 첫 번째 라인은 거리 데이터 블록에 있는 모든
NaN값을 필터링합니다. 두 번째 라인은 총 거리와 블록 수로 구성된, 요소를 2개 가진 벡터를 생성하고, 세 번째 라인은 값으로 구성된 이 벡터를 키'sumAndLength'와 함께intermKVStore에 추가합니다. 이 map 함수가ds에 있는 모든 데이터 블록에 대해 실행되고 나면intermKVStore객체에 총 거리와 각 거리 데이터 블록의 개수가 들어 있게 됩니다.이 함수를 현재 폴더에
MeanDistMapFun.m으로 저장합니다.reduce 함수에 대한 입력값은
intermKey,intermValIter및outKVStore여야 합니다.intermKey는 map 함수에 의해 추가된 활성 키를 위한 것입니다.mapreduce가 reduce 함수를 호출할 때마다 중간KeyValueStore객체의 키 중에서 새로운 고유 키가 지정됩니다.intermValIter는 활성 키intermKey에 대한ValueIterator입니다. 이ValueIterator객체는 활성 키에 대한 모든 값을 포함합니다.hasnext함수와getnext함수를 사용하여 값을 스크롤합니다.outKVStore는 reduce 함수가 키-값 쌍을 추가해야 하는 최종KeyValueStore객체의 이름입니다.mapreduce는outKVStore에서 출력 키-값 쌍을 가져온 다음 출력 데이터저장소(기본적으로KeyValueDatastore객체)에 반환합니다. reduce 함수를 호출해도outKVStore에 키-값 쌍이 전혀 추가되지 않으면mapreduce는 빈 데이터저장소를 반환합니다.
다음은 reduce 함수에 대한 간단한 예제입니다.
function MeanDistReduceFun(intermKey, intermValIter, outKVStore) sumLen = [0 0]; while hasnext(intermValIter) sumLen = sumLen + getnext(intermValIter); end add(outKVStore, 'Mean', sumLen(1)/sumLen(2)); end
이 reduce 함수는
intermValIter에 있는 각 거리 값과 개수 값을 순회하며, 각 반복마다 거리와 개수의 누계를 저장합니다. 이러한 루프가 끝나면 reduce 함수는 간단한 나누기로 비행 거리의 전체 평균을 계산한 다음, 단일 키를outKVStore에 추가합니다.이 함수를 현재 폴더에
MeanDistReduceFun.m으로 저장합니다.
고급 map 함수 및 reduce 함수를 작성하는 방법에 대한 자세한 내용은 map 함수 쓰기 항목과 Write a Reduce Function 항목을 참조하십시오.
mapreduce 실행하기
데이터저장소와 map 함수, reduce 함수를 생성했으면 mapreduce를 호출하여 계산을 수행할 수 있습니다. 데이터 세트에서 평균 비행 거리를 계산하기 위해 ds, MeanDistMapFun, MeanDistReduceFun을 사용하여 mapreduce를 호출합니다.
outds = mapreduce(ds, @MeanDistMapFun, @MeanDistReduceFun);
******************************** * MAPREDUCE PROGRESS * ******************************** Map 0% Reduce 0% Map 16% Reduce 0% Map 32% Reduce 0% Map 48% Reduce 0% Map 65% Reduce 0% Map 81% Reduce 0% Map 97% Reduce 0% Map 100% Reduce 0% Map 100% Reduce 100%
기본적으로 mapreduce 함수는 명령줄에 진행률 정보를 표시하고, 현재 폴더의 파일을 가리키는 KeyValueDatastore 객체를 반환합니다. 'OutputFolder', 'OutputType', 'Display'에 Name,Value 쌍의 인수를 사용하여 이 세 가지 옵션을 모두 조정할 수 있습니다. 자세한 내용은 mapreduce 도움말 페이지를 참조하십시오.
결과 보기
readall 함수를 사용하여 출력 데이터저장소에서 키-값 쌍을 읽어옵니다.
readall(outds)
ans =
1×2 table
Key Value
________ ____________
{'Mean'} {[702.1630]}참고 항목
tabularTextDatastore | mapreduce