권장되지 않는 hist 및 histc 인스턴스의 대체 방법
이전 히스토그램 함수(hist, histc)
이전 버전의 MATLAB®에서는 기본적으로 hist 함수나 histc 함수를 사용하여 히스토그램을 생성하고 히스토그램 Bin 도수를 계산합니다. 이러한 함수는 일부 일반적인 용도로는 적합하지만 전반적으로 기능에 제한이 있습니다. 새 코드에서 hist나 histc를 사용하는 것은 특히 다음과 같은 이유로 권장되지 않습니다.
hist를 사용하여 히스토그램을 만든 후에는 히스토그램의 속성을 수정하기가 어려우며, 수정하려면 전체 히스토그램을 다시 계산해야 합니다.hist의 디폴트 동작은 10개의 Bin을 사용하는 것이며, 이는 많은 데이터 세트에 적합하지 않습니다.정규화된 히스토그램을 플로팅하려면 수동으로 계산해야 합니다.
hist와histc의 동작이 일관되지 않습니다.
권장되는 히스토그램 함수
histogram, histcounts, discretize 함수는 MATLAB에서 히스토그램을 생성하고 계산하는 기능을 크게 향상시키는 동시에 일관성과 사용 편의성도 높습니다. histogram, histcounts, discretize는 히스토그램 생성 및 계산을 위한 함수로, 새 코드에 권장됩니다.
특히 주목할 만한 것은 다음과 같은 변경 내용으로, 이는 hist와 histc에 대한 개선 사항입니다.
histogram은 histogram 객체를 반환할 수 있습니다. 이 객체를 사용하여 히스토그램의 속성을 수정할 수 있습니다.histogram과histcounts에는 모두 자동 비닝(Binning) 및 정규화 기능이 있으며, 두 함수는 공통적인 여러 내장 옵션을 갖고 있습니다.histcounts는histogram에 대한 주 계산 함수입니다. 따라서 이 두 함수는 일관되게 동작합니다.discretize는 각 요소의 Bin 배치를 결정할 수 있는 추가적인 옵션과 유연성을 제공합니다.
코드 업데이트가 필요한 차이점
앞에서 언급한 개선 사항에도 불구하고, 이전 함수와 권장되는 새 함수 간에는 여러 가지 중요한 차이점이 있으며, 이로 인해 코드를 업데이트해야 할 수도 있습니다. 다음 표에는 함수 간의 차이점이 요약되어 있으며 코드 업데이트를 위한 제안 사항도 나와 있습니다.
hist의 코드 업데이트
| 차이점 | 이전 hist의 동작 | 새로운 histogram의 동작 |
|---|---|---|
입력 행렬 |
A = randn(100,2); hist(A) |
A = randn(100,2); h1 = histogram(A(:,1),10) edges = h1.BinEdges; hold on h2 = histogram(A(:,2),edges) 위의 코드 예제에서는 각 히스토그램에 동일한 Bin 경계값을 사용하지만, 경우에 따라서는 이 대신 각 히스토그램의 |
Bin 지정 |
|
참고
histogram(A,'BinLimits',[-3,3],'BinMethod','integers') |
출력 인수 |
A = randn(100,1); [N, Centers] = hist(A) |
A = randn(100,1); h = histogram(A); N = h.Values Edges = h.BinEdges 참고 히스토그램을 플로팅하지 않고 Bin 도수를 계산하려면 |
Bin의 디폴트 개수 |
|
A = randn(100,1); histogram(A) histcounts(A) |
Bin 제한 |
|
유한 데이터 값( A = randi(5,100,1); histogram(A,10,'BinLimits',[min(A) max(A)]) |
histc의 코드 업데이트
| 차이점 | 이전 histc의 동작 | 새로운 histcounts의 동작 |
|---|---|---|
| 입력 행렬 |
A = randn(100,10); edges = -4:4; N = histc(A,edges) |
A = randn(100,10); edges = -4:4; N = histcounts(A,edges) 각 열에 대해 Bin 도수를 계산하려면 for 루프를 사용하십시오. A = randn(100,10); nbins = 10; N = zeros(nbins, size(A,2)); for k = 1:size(A,2) N(:,k) = histcounts(A(:,k),nbins); end 행렬의 열 개수가 많아 성능이 문제가 된다면, 각 열에 대한 Bin 도수 계산 시에 계속해서 |
| 마지막 Bin에 포함된 값 |
|
A = 1:4; edges = [1 2 2.5 3] N = histcounts(A) N = histcounts(A,edges)
N = histcounts(A,'BinMethod','integers'); |
| 출력 인수 |
A = randn(15,1); edges = -4:4; [N,Bin] = histc(A,edges) |
|
Bin 중심값을 Bin 경계값으로 변환
hist 함수는 Bin 중심값을 받는 반면, histogram 함수는 Bin 경계값을 받습니다. histogram을 사용하도록 코드를 업데이트하려면 Bin 중심값을 Bin 경계값으로 변환하여 hist에서 얻은 결과를 재현해야 할 수 있습니다.
예를 들어, hist에서 사용할 Bin 중심값을 지정합니다. 이러한 Bin은 너비가 균일합니다.
A = [-9 -6 -5 -2 0 1 3 3 4 7]; centers = [-7.5 -2.5 2.5 7.5]; hist(A,centers)
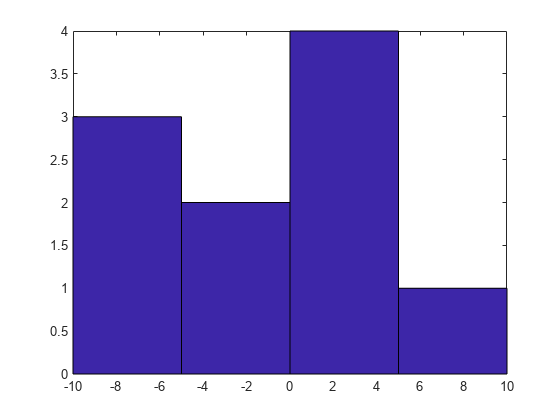
Bin 중심값을 Bin 경계값으로 변환하기 위해서는 centers에서 연속 값 사이의 중간점을 계산해야 합니다. 이 방법은 균일하거나 균일하지 않은 Bin 너비 모두에 대해 hist의 결과를 재현할 수 있습니다.
d = diff(centers)/2; edges = [centers(1)-d(1), centers(1:end-1)+d, centers(end)+d(end)];
hist 함수는 각 Bin의 오른쪽 경계값을 포함합니다(첫 번째 Bin은 양쪽 경계값을 모두 포함함). 반면 histogram은 각 Bin의 왼쪽 경계값을 포함합니다(마지막 Bin은 양쪽 경계값을 모두 포함함). Bin 경계값을 약간 이동시키면 hist와 동일한 Bin 도수를 얻을 수 있습니다.
edges(2:end) = edges(2:end)+eps(edges(2:end))
edges = 1×5
-10.0000 -5.0000 0.0000 5.0000 10.0000
이제 histogram에 Bin 경계값을 사용합니다.
histogram(A,edges)