Configure for Spark Clusters
Submit parallel MATLAB® code that contains tall (MATLAB) arrays and mapreduce (MATLAB) functions to a Spark™ cluster from suitably configured MATLAB clients.
Cluster Configuration
Follow these instructions to interface MATLAB Parallel Server™ installation into your Spark cluster.
Integrate MATLAB Parallel Server with your cluster infrastructure. For instructions, see License and Install MATLAB Parallel Server in Cluster.
MATLAB Parallel Server supports Spark clusters running in different environments such as Spark Standalone or Databricks™.
If your cluster requires Kerberos authentication, ensure your MATLAB Parallel Server installation have been configured correctly. For instructions, see Kerberos Authentication.
Client Configuration
To configure the client to run MATLAB code on the cluster, you must already be able to submit to the cluster from the intended client machine. The client machine must have a Spark installation that can access the cluster outside of MATLAB.
Many Spark distributions do not support direct access of Linux® based clusters from Windows® clients. Users of Windows clients typically need to set up a Linux gateway node that can be accessed from the Windows client via SSH or VNC. The cluster can then be accessed from this gateway node.
You must ensure your MATLAB client installation has been configured for Kerberos authentication if your cluster requires it. For instructions, see Kerberos Authentication.
Create a Cluster Profile
In this step you create a cluster profile that enables the MATLAB client to connect to the cluster.
Start the Cluster Profile Manager. On the Home tab, in the Environment area, select Parallel > Create and Manage Clusters.
Create a new profile in the Cluster Profile Manager by selecting Add Cluster Profile > Spark.
With the new profile selected in the list, click Rename and edit the profile name to be
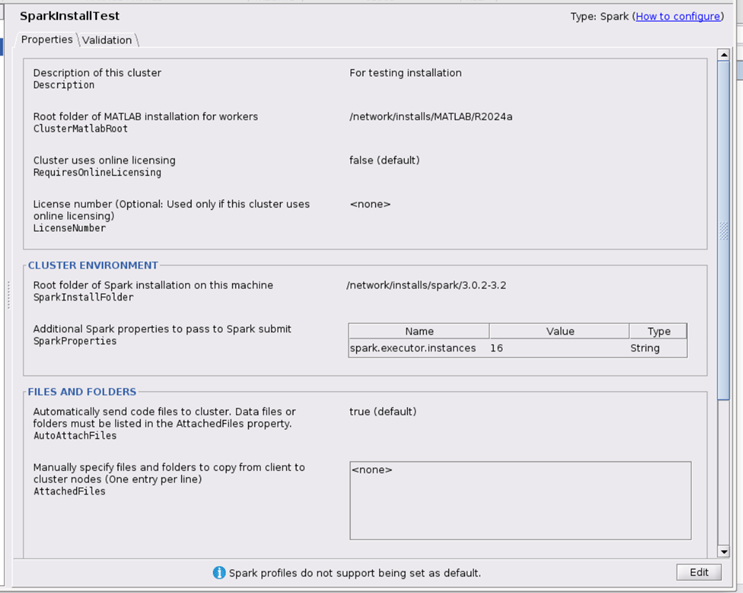
SparkInstallTest. Press Enter.In the Properties tab, select Edit and provide settings for the following fields:
Set the Description field to For testing installation.
Set ClusterMatlabRoot to the installation location of MATLAB to run on the worker machines.
If the cluster uses online licensing, set RequiresOnlineLicensing to true.
If you set RequiresOnlineLicensing to
true, in the LicenseNumber field, enter your license number.Set SparkInstallFolder to the Spark installation location on the client machine.
Specify additional Spark properties in the SparkProperties table. For example, to specify the preferred number of workers to 16, under the SparkProperties table, select Add. Specify a new property with the name
spark.executor.instances, enter the16for the value, and selectStringas the data type.Click Done to save your cluster profile changes. The dialog box looks as follows:
Validate the Cluster Profile
In this step you verify your cluster profile, and thereby your installation.
If it is not already open, start the Cluster Profile Manager from the MATLAB desktop. On the Home tab, in the Environment area, select Parallel > Create and Manage Clusters.
Select the SparkInstallTest cluster profile in the listing.
Click Validation tab.
Use the checkboxes to choose all tests, or a subset of the validation stages, and specify the number of workers to use when validating your profile.
Click Validate.
After the client completes the cluster validation, the Validation tab shows the output. The following figure shows the results of a profile that passed all validation tests.

Note
If your validation does not pass, contact the MathWorks install support team.
If your validation passed, you now have a valid profile that you can use to access
the cluster from a MATLAB client. You can make any modifications to your profile appropriate for
your applications, such as specifying additional Spark properties,
NumWorkersRange, AttachedFiles,
AdditionalPaths, and so on.
To save your profile for other users, select the profile and click Export, then save your profile to a file in a convenient location. Later, when running the Cluster Profile Manager, other users can import your profile by clicking Import.
Examples
Use mapreducer (MATLAB) function to change the
execution environment to the Spark cluster.
For examples of how to run parallel MATLAB code on your Spark cluster, see Use Tall Arrays on a Spark Cluster (Parallel Computing Toolbox).
Kerberos Authentication
If the cluster uses Kerberos authentication that requires the Oracle® Java® Cryptography Extension, you must configure all installations of MATLAB and MATLAB Parallel Server. If you are using Spark on Hadoop®, for example Cloudera® distributions, it is likely that you need to complete these configuration steps.
The configuration instructions are the same for client and worker MATLAB installations.
Starting in R2018b, configure your MATLAB installation by enabling the appropriate security policy in the Java installation.
In the MATLAB Editor, open the file
${MATLAB_ROOT}/sys/java/jre/${ARCH}/jre/lib/security/java.security.Change the line
to#crypto.policy=unlimited
crypto.policy=unlimited
Spark Version Support
Spark 2.2 or later supports MATLAB
mapreduce, tall arrays and parallel usage of datastores. For
the client, you can use tall arrays on Spark clusters supporting all architectures, while supporting Linux and Mac architectures for the cluster. This includes cross-platform
support.
Spark Executor Memory Default
The default value of the spark.executor.memory property of a
Spark job submitted from MATLAB is 2560 MB.
See Also
parallel.cluster.Spark (Parallel Computing Toolbox)
Topics
- License and Install MATLAB Parallel Server in Cluster
- Use Tall Arrays on a Spark Cluster (Parallel Computing Toolbox)