imhistmatch
참조 영상의 히스토그램과 일치하도록 2차원 영상의 히스토그램 조정하기
구문
설명
J = imhistmatch(I,ref)I의 히스토그램이 참조 영상 ref의 히스토그램과 대략 일치하도록 조정합니다.
I및ref모두 RGB 영상인 경우imhistmatch는I의 각 색 채널을 그에 대응하는ref의 색 채널에 개별적으로 일치시킵니다.I가 RGB 영상이고ref가 회색조 영상인 경우imhistmatch는I의 각 채널을ref에서 도출된 단일 히스토그램에 일치시킵니다.I가 회색조 영상인 경우ref도 회색조 영상이어야 합니다.
영상 I와 ref는 크기가 같지 않아도 됩니다.
J = imhistmatch(I,ref,nbins)nbins개의 Bin을 사용합니다. 반환된 영상 J는 nbins개를 넘지 않는 이산 수준을 가집니다.
영상의 데이터형이
single형이거나double형이면 히스토그램 범위는 [0, 1]입니다.영상의 데이터형이
uint8형이면 히스토그램 범위는 [0, 255]입니다.영상의 데이터형이
uint16형이면 히스토그램 범위는 [0, 65535]입니다.영상의 데이터형이
int16형이면 히스토그램 범위는 [-32768, 32767]입니다.
예제
이 항공 영상은 매사추세츠주 콩코드에 있는 한 지형을 서로 다른 시간에 촬영한 뷰를 겹친 것입니다. 이 예제에서는 입력 영상 A와 Ref의 크기 및 영상 유형이 다를 수도 있음을 보여줍니다.
RGB 영상 및 참조 회색조 영상을 불러옵니다.
A = imread("westconcordaerial.png"); Ref = imread("westconcordorthophoto.png");
A의 크기를 확인합니다.
size(A)
ans = 1×3
394 369 3
Ref의 크기를 확인합니다.
size(Ref)
ans = 1×2
366 364
영상 A와 Ref가 크기와 유형이 다름을 확인할 수 있습니다. 영상 A는 트루컬러 RGB 영상이지만, 영상 Ref는 회색조 영상입니다. 두 영상 모두 uint8 데이터형입니다.
히스토그램 매칭을 적용한 출력 영상을 생성합니다. 이 예제에서는 A의 각 채널을 Ref의 단일 히스토그램과 일치시킵니다. 출력 영상 B는 영상 A의 특성을 물려받아서 크기와 데이터형이 영상 A와 같은 RGB 영상입니다. 영상 B의 각 RGB 채널에 있는 고유한 수준의 개수가 회색조 영상 Ref에서 생성된 히스토그램의 Bin 개수와 같습니다. 이 예제에서는 Ref 및 B의 히스토그램의 Bin 개수가 디폴트 값인 64입니다.
B = imhistmatch(A,Ref);
RGB 영상 A, 참조 영상 Ref, 히스토그램 매칭을 적용한 RGB 영상 B를 표시합니다. 이 영상은 표시되기 전에 크기가 조정됩니다.
imshow(A)
title("RGB Image with Color Cast")
imshow(Ref)
title("Reference Grayscale Image")
imshow(B)
title("Histogram Matched RGB Image")
컬러 영상 및 참조 영상을 읽어 들입니다. polynomial 방법을 시연하기 위해 두 영상 중에서 참조 영상에 더 어두운 영상을 할당합니다.
I = imread('office_4.jpg'); ref = imread('office_2.jpg'); montage({I,ref}) title('Input Image (Left) vs Reference Image (Right)');

polynomial 방법으로 영상 I의 명암을 조정해서 이 영상의 히스토그램을 참조 영상 ref의 히스토그램에 일치시킵니다. 비교를 위해 uniform 방법을 사용하여 영상 I의 명암도 조정합니다.
J = imhistmatch(I,ref,'method','polynomial'); K = imhistmatch(I,ref,'method','uniform'); montage({J,K}) title('Histogram-Matched Image Using Polynomial Method (Left) vs Uniform Method (Right)');
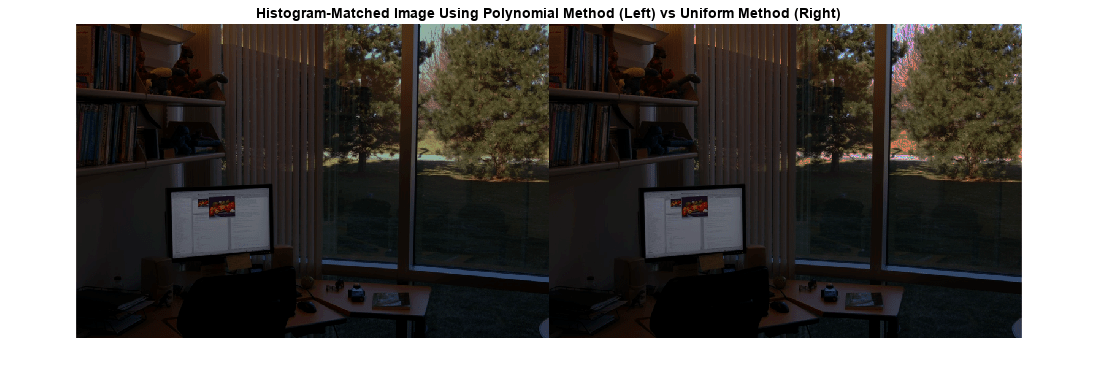
uniform 방법을 사용하여 히스토그램 매칭을 수행한 영상에서는 하늘과 길에 가색상이 나타납니다. polynomial 방법을 사용하여 히스토그램 매칭을 수행한 영상에는 이 아티팩트가 나타나지 않습니다.
이 예제에서는 목표 히스토그램의 Bin 개수를 달리하여 히스토그램 평활화를 개선하는 방법을 보여줍니다.
uint8 데이터형의 영상 두 개를 작업 공간으로 불러옵니다. 두 영상은 디지털 카메라로 촬영한 것이며, 동일한 장면을 2가지 노출로 보여줍니다. A는 과소 노출된 영상으로 어둡게 표시됩니다. ref는 노출과 밝기가 양호한 참조 영상입니다.
A = imread('office_2.jpg'); ref = imread('office_4.jpg');
영상을 몽타주에 표시합니다.
montage({A,ref})
title('Dark Image (Left) and Reference Image (Right)')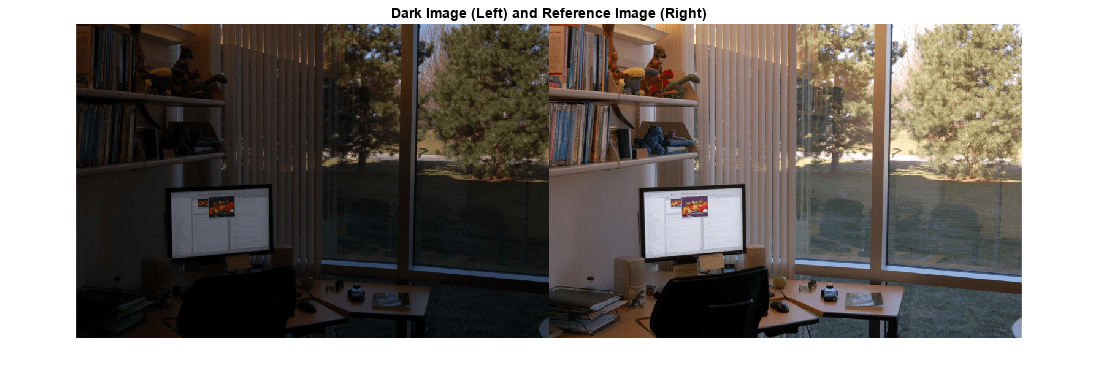
256개의 Bin을 사용하여 각 색 채널의 히스토그램을 표시합니다. 예제에 포함된 헬퍼 함수 displayHistogramChannels를 사용할 수 있습니다.
displayHistogramChannels(A,ref)
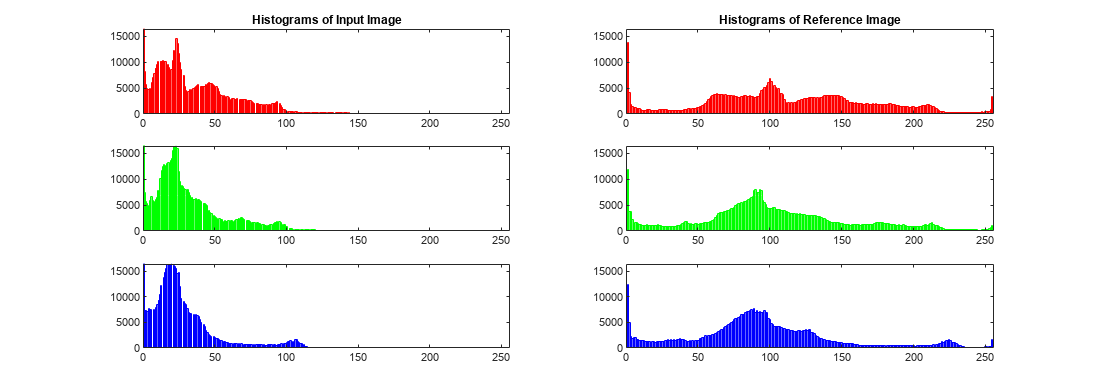
더 어두운 영상인 A는 대다수의 픽셀이 낮은 Bin에 있습니다. 참조 영상 ref는 3개 RGB 채널 모두 전체 256개의 Bin 값으로 완전히 채워져 있습니다.
어두운 영상과 참조 영상의 각 색 채널에 대해 고유한 8비트 수준 값의 개수를 셉니다. 예제에 포함된 헬퍼 함수 countUniqueValues를 사용할 수 있습니다.
numVals = countUniqueValues(A,ref); table(numVals(:,1),numVals(:,2),numVals(:,3), ... 'VariableNames',["Red" "Green" "Blue"], ... 'RowNames',["A" "ref"])
ans=2×3 table
Red Green Blue
___ _____ ____
A 205 193 224
ref 256 256 256
nbins에 각기 다른 3개 값 64, 128, 256을 사용하여 어두운 영상의 히스토그램을 평활화합니다. 64는 디폴트 Bin 개수이고 256은 uint8형 픽셀 데이터의 최대 Bin 개수입니다.
[B64,hgram64] = imhistmatch(A,ref,64);
[B128,hgram128] = imhistmatch(A,ref,128);
[B256,hgram256] = imhistmatch(A,ref,256);
figure
montage({B64,B128,B256},'Size',[1 3])
title('Output Image B64 | Output Image B128 | Output Image B256')
256개의 Bin을 사용하여 각 색 채널의 히스토그램을 표시합니다. 예제에 포함된 헬퍼 함수 displayThreeHistogramChannels를 사용할 수 있습니다.
displayThreeHistogramChannels(B64,B128,B256)
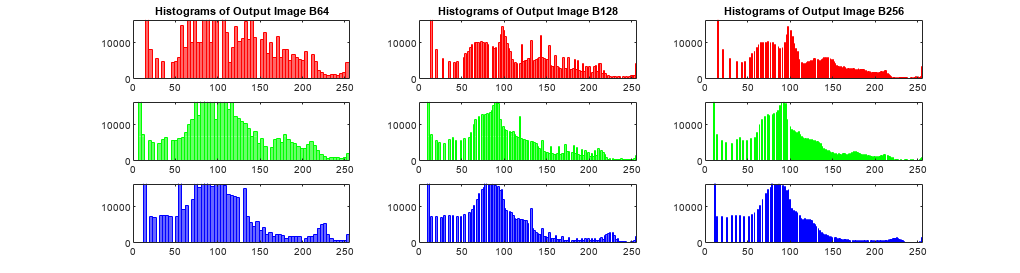
히스토그램 평활화된 3개 영상의 각 색 채널에 대해 고유한 8비트 수준 값의 개수를 셉니다. nbins가 증가하면 출력 영상 B의 각 RGB 채널에 있는 수준 개수도 늘어납니다.
numVals = countUniqueValues(B64,B128,B256); table(numVals(:,1),numVals(:,2),numVals(:,3), ... 'VariableNames',["Red" "Green" "Blue"], ... 'RowNames',["B64" "B128" "B256"])
ans=3×3 table
Red Green Blue
___ _____ ____
B64 57 60 58
B128 101 104 104
B256 134 135 136
이 예제에서는 여러 다른 개수의 Bin을 사용하여 히스토그램 매칭을 수행하는 방법을 보여줍니다.
무릎을 MRI로 촬영한 16비트 DICOM 영상을 불러옵니다.
K = dicomread('knee1.dcm'); % read in original 16-bit image LevelsK = unique(K(:)); % determine number of unique code values disp(['image K: ',num2str(length(LevelsK)),' distinct levels']);
image K: 448 distinct levels
disp(['max level = ' num2str( max(LevelsK) )]);max level = 473
disp(['min level = ' num2str( min(LevelsK) )]);min level = 0
448개의 이산 값이 모두 낮은 코드 값이며, 따라서 영상이 어둡게 보입니다. 이를 수정하기 위해 영상 데이터를 스케일링하여 16비트 전체 범위 [0, 65535]를 포괄하도록 합니다.
Kdouble = double(K); % cast uint16 to double kmult = 65535/(max(max(Kdouble(:)))); % full range multiplier Ref = uint16(kmult*Kdouble); % full range 16-bit reference image
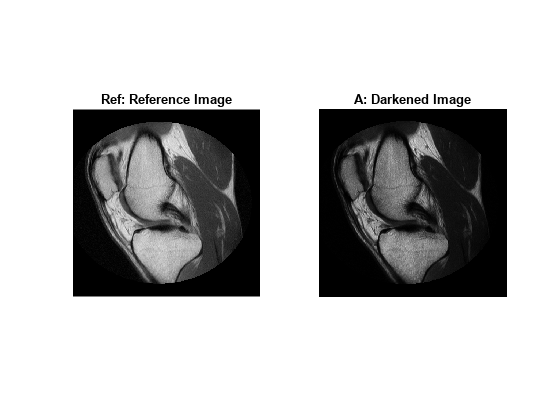
참조 영상 Ref를 어둡게 만들어서 히스토그램 일치 연산에 사용할 수 있는 영상 A를 만듭니다.
%Build concave bow-shaped curve for darkening |Ref|. ramp = [0:65535]/65535; ppconcave = spline([0 .1 .50 .72 .87 1],[0 .025 .25 .5 .75 1]); Ybuf = ppval( ppconcave, ramp); Lut16bit = uint16( round( 65535*Ybuf ) ); % Pass image |Ref| through a lookup table (LUT) to darken the image. A = intlut(Ref,Lut16bit);
참조 영상 Ref 및 더 어두워진 영상 A를 봅니다. 두 영상이 이산 코드 값의 개수는 같지만 전반적인 밝기는 다르다는 것을 알 수 있습니다.
subplot(1,2,1) imshow(Ref) title('Ref: Reference Image') subplot(1,2,2) imshow(A) title('A: Darkened Image');
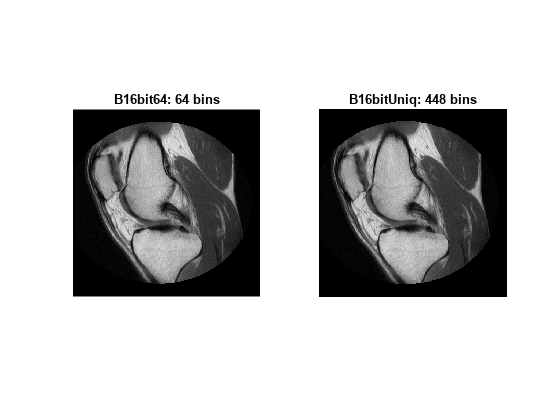
각기 다른 개수의 Bin을 가진 히스토그램을 사용하여 히스토그램 매칭을 적용한 출력 영상을 생성합니다. 먼저 기본 Bin 개수인 64를 사용합니다. 그런 다음 영상 A에 있는 값의 개수, 즉 448개의 Bin을 사용합니다.
B16bit64 = imhistmatch(A(:,:,1),Ref(:,:,1)); % default: 64 bins N = length(LevelsK); % number of unique 16-bit code values in image A. B16bitUniq = imhistmatch(A(:,:,1),Ref(:,:,1),N);
두 히스토그램의 매칭 연산 결과를 봅니다.
figure subplot(1,2,1) imshow(B16bit64) title('B16bit64: 64 bins') subplot(1,2,2) imshow(Ref) title(['B16bitUniq: ',num2str(N),' bins'])
입력 인수
출력 인수
알고리즘
imhistmatch의 목적은 영상 I를 변환하여 영상 J의 히스토그램이 영상 ref에서 도출된 히스토그램과 일치하게 하는 것입니다. 참조 영상의 히스토그램은 해당 이미지 데이터형의 전체 범위를 포괄하는 nbins개의 균일한 간격의 Bin으로 구성됩니다. 이런 방식으로 히스토그램 매칭을 수행하면 nbins는 또한 영상 J에 존재하는 이산 데이터 수준의 상한 개수를 나타내게 됩니다.
이 알고리즘에서 주목해야 할 중요한 동작 특성은 nbins의 값이 증가함에 따라 영상 J의 히스토그램에서 인접한 채워진 피크 간에 변동의 빠른 정도가 커지는 경향이 있다는 점입니다. 이는 16비트 회색조 MRI 예제에서 얻은 다음 히스토그램 플롯에서 확인할 수 있습니다.

nbins의 최적 값은 nbins의 값이 클수록 출력 수준이 많아지는 것과 nbins의 값이 작을수록 히스토그램의 피크 변동이 최소화되는 것 사이를 절충하는 값입니다.
버전 내역
R2012b에 개발됨