이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
의미론적 분할 신경망을 위한 코드 생성
이 예제에서는 딥러닝을 사용하여 영상을 분할하는 응용 사례를 위한 코드를 생성합니다. 영상 분할에 사용되는 딥러닝 신경망인 SegNet [1]의 DAG Network 객체에 대해 예측을 수행하는 MEX 함수를 codegen 명령을 사용하여 생성합니다.
타사 선행 조건
필수
이 예제는 CUDA MEX를 생성하며, 다음과 같은 타사 요구 사항이 있습니다.
CUDA® 지원 NVIDIA® GPU 및 호환되는 드라이버.
선택 사항
정적, 동적 라이브러리 또는 실행 파일과 같은 비 MEX 빌드의 경우, 이 예제에는 다음과 같은 추가 요구 사항이 있습니다.
NVIDIA 툴킷.
NVIDIA cuDNN 라이브러리.
컴파일러 및 라이브러리 환경 변수. 자세한 내용은 타사 하드웨어 항목과 필수 제품 설정하기 항목을 참조하십시오.
GPU 환경 확인하기
coder.checkGpuInstall 함수를 사용하여 이 예제를 실행하는 데 필요한 컴파일러와 라이브러리가 올바르게 설치되었는지 확인합니다.
envCfg = coder.gpuEnvConfig('host'); envCfg.DeepLibTarget = 'cudnn'; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; coder.checkGpuInstall(envCfg);
분할 신경망
SegNet [1]은 의미론적 영상 분할을 위해 설계되어 사용되는 CNN(컨벌루션 신경망)의 일종입니다. 심층 인코더-디코더 방식의 다중 클래스 픽셀 분할 신경망으로서, CamVid [2] 데이터셋에 대해 훈련시켜 추론을 위해 MATLAB®으로 가져옵니다. SegNet [1]은 하늘, 건물, 기둥, 도로, 보도, 나무, 기호, 울타리, 자동차, 보행자, 자전거 운전자 등의 11개 클래스에 속하는 픽셀을 분할하도록 훈련되었습니다.
CamVid [2] 데이터셋을 사용하여 MATLAB에서 의미론적 분할 신경망을 훈련시키는 방법에 대한 자세한 내용은 딥러닝을 사용한 의미론적 분할 (Computer Vision Toolbox) 항목을 참조하십시오.
segnet_predict 진입점 함수
segnet_predict.m 진입점 함수는 영상을 입력값으로 받아 SegNet.mat 파일에 저장된 딥러닝 신경망을 사용하여 이 영상에 대해 예측을 수행합니다. 이 함수는 SegNet.mat 파일의 network 객체를 영속 변수 mynet으로 불러온 다음 후속 예측 호출에서 영속 변수를 재사용합니다.
type('segnet_predict.m')function out = segnet_predict(in)
%#codegen
% Copyright 2018-2021 The MathWorks, Inc.
persistent mynet;
if isempty(mynet)
mynet = coder.loadDeepLearningNetwork('SegNet.mat');
end
% pass in input
out = predict(mynet,in);
사전 훈련된 SegNet DAG Network 객체 가져오기
net = getSegNet();
DAG 신경망은 컨벌루션 계층, 배치 정규화 계층, 풀링 계층, 언풀링 계층, 픽셀 분류 출력 계층을 비롯한 91개의 계층으로 이루어져 있습니다. analyzeNetwork (Deep Learning Toolbox) 함수를 사용하여 딥러닝 신경망 아키텍처의 대화형 시각화를 표시합니다.
analyzeNetwork(net);
MEX 코드 생성 실행하기
segnet_predict.m 진입점 함수에 대한 CUDA 코드를 생성하려면 MEX 타깃에 대한 GPU 코드 구성 객체를 만들고 타깃 언어를 C++로 설정하십시오. coder.DeepLearningConfig 함수를 사용하여 CuDNN 딥러닝 구성 객체를 만들고 이 객체를 GPU 코드 구성 객체의 DeepLearningConfig 속성에 할당합니다. 입력 크기를 [360,480,3]으로 지정하여 codegen 명령을 실행합니다. 이 값은 SegNet의 입력 계층 크기입니다.
cfg = coder.gpuConfig('mex'); cfg.TargetLang = 'C++'; cfg.DeepLearningConfig = coder.DeepLearningConfig('cudnn'); codegen -config cfg segnet_predict -args {ones(360,480,3,'uint8')} -report
Code generation successful: View report
생성된 MEX 실행하기
입력 영상을 하나 불러와서 표시합니다. 입력 영상에 대해 segnet_predict_mex를 호출합니다.
im = imread('gpucoder_segnet_image.png');
imshow(im);
predict_scores = segnet_predict_mex(im);
predict_scores 변수는 모든 클래스의 픽셀별 예측 점수에 대응하는 11개의 채널을 갖는 3차원 행렬입니다. 채널의 최대 예측 점수를 계산하여 픽셀별 레이블을 얻습니다.
[~,argmax] = max(predict_scores,[],3);
입력 영상 위에 분할된 레이블을 중첩하고 분할된 영역을 표시합니다.
classes = [
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
];
cmap = camvidColorMap();
SegmentedImage = labeloverlay(im,argmax,'ColorMap',cmap);
figure
imshow(SegmentedImage);
pixelLabelColorbar(cmap,classes);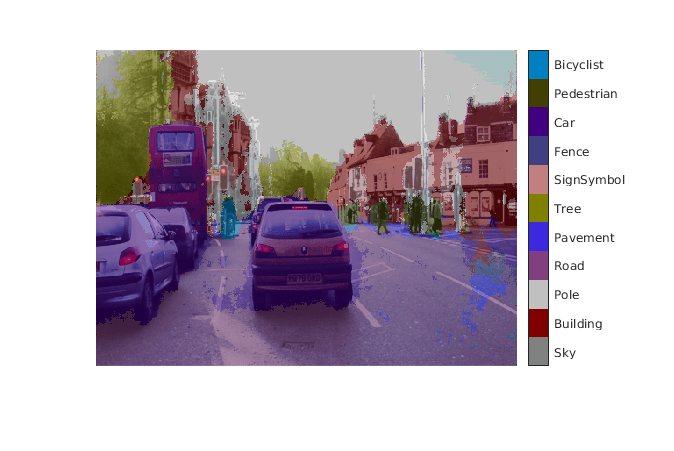
참고 문헌
[1] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." arXiv preprint arXiv:1511.00561, 2015.
[2] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla. "Semantic object classes in video: A high-definition ground truth database." Pattern Recognition Letters Vol 30, Issue 2, 2009, pp 88-97.
참고 항목
함수
객체
도움말 항목
- 딥러닝을 사용한 의미론적 분할 (Computer Vision Toolbox)
- Semantic Segmentation on NVIDIA DRIVE
- Code Generation for Semantic Segmentation Network That Uses U-net
- 딥러닝을 사용한 의미론적 분할 시작하기 (Computer Vision Toolbox)