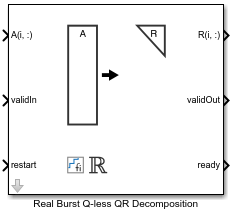
Real Burst Q-less QR Decomposition
Q-less QR decomposition for real-valued matrices
Libraries:
Fixed-Point Designer HDL Support /
Matrices and Linear Algebra /
Matrix Factorizations
Description
The Real Burst Q-less QR Decomposition block uses QR decomposition to compute the economy size upper-triangular R factor of the QR decomposition A = QR, where A is a real-valued matrix, without computing Q. The solution to A'Ax = B is x = R\R'\b.
When Regularization parameter is nonzero, the Real Burst Q-less QR Decomposition block computes the upper-triangular factor R of the economy size QR decomposition of where λ is the regularization parameter.
Examples

Implement Hardware-Efficient Real Burst Q-less QR Decomposition
How to use the Real Burst Q-less QR Decomposition block.
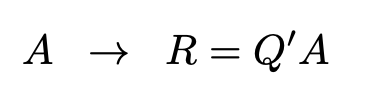
Determine Fixed-Point Types for Q-less QR Decomposition
Use fixed.qlessqrFixedpointTypes to determine fixed-point types for
computation of Q-less QR decomposition.
Ports
Input
Output
Parameters
Tips
Use fixed.getQlessQRDecompositionModel(A) to generate a template model
containing a Real Burst Q-less QR Decomposition block for real-valued input
matrix A.
Algorithms
The Burst Q-less QR Decomposition blocks accept and process the matrix A row by row. After accepting m rows, the block outputs the matrix R row by row continuously. The matrix is output from the last row to the first row.
For example, assume that the input A matrix is 3-by-3. Additionally
assume that validIn asserts before ready, meaning that
the upstream data source is faster than the QR decomposition.

In the figure,
A1r1is the first row of the first A matrix,R1r3is the third row of the first R matrix, and so on.validIntoready— From a successful row input to the block being ready to accept the next row.Last row
validIntovalidOut— From the last row input to the block starting to output the solution.validOuttoready— From the block starting to output the solution to the block ready to accept the next matrix input.
The following table provides details of the timing for the Burst Q-less QR Decomposition blocks.
| Block | validIn to ready (cycles) | Last Row validIn to validOut
(cycles) | validOut to ready (cycles) |
|---|---|---|---|
| Real Burst Q-less QR Decomposition | (wl + 5)*min(m,n) + 2 | (wl + 5)*min(m,n) + 2 | min(m,n) + 1 |
| Complex Burst Q-less QR Decomposition | (wl*2 + 11)*min(m,n) + 2 | (wl*2 + 11)*min(m,n) + 2 | min(m,n) + 1 |
In the table, m represents the number of rows in matrix A, and n is the number of columns in matrix A. wl represents the word length of the input data.
If the data type of A is double, then wl is 53.
If the data type of A is single, then wl is 24.
If the data type of A is fixed point, then wl is the word length.
References
[1] "AMBA AXI and ACE Protocol Specification Version E." https://developer.arm.com/documentation/ihi0022/e/