Normalized Reciprocal HDL Optimized
Computes normalized reciprocal using CORDIC algorithm and generates optimized HDL code

Libraries:
Fixed-Point Designer HDL Support /
Math Operations
Description
The Normalized Reciprocal HDL Optimized block computes the normalized reciprocal of u, returned as y and e such that 0.5 < |y| ≤ 1 and 2ey = 1/u.
If u = 0 and u is a fixed-point or scaled-double data type, then y = 1 – eps(y) and e = 2nextpow2(w) – w + f, where
wis the word length of u and f is the fraction length of u.If u = 0 and u is a floating-point data type, then y =
Infand e = 1.
Examples
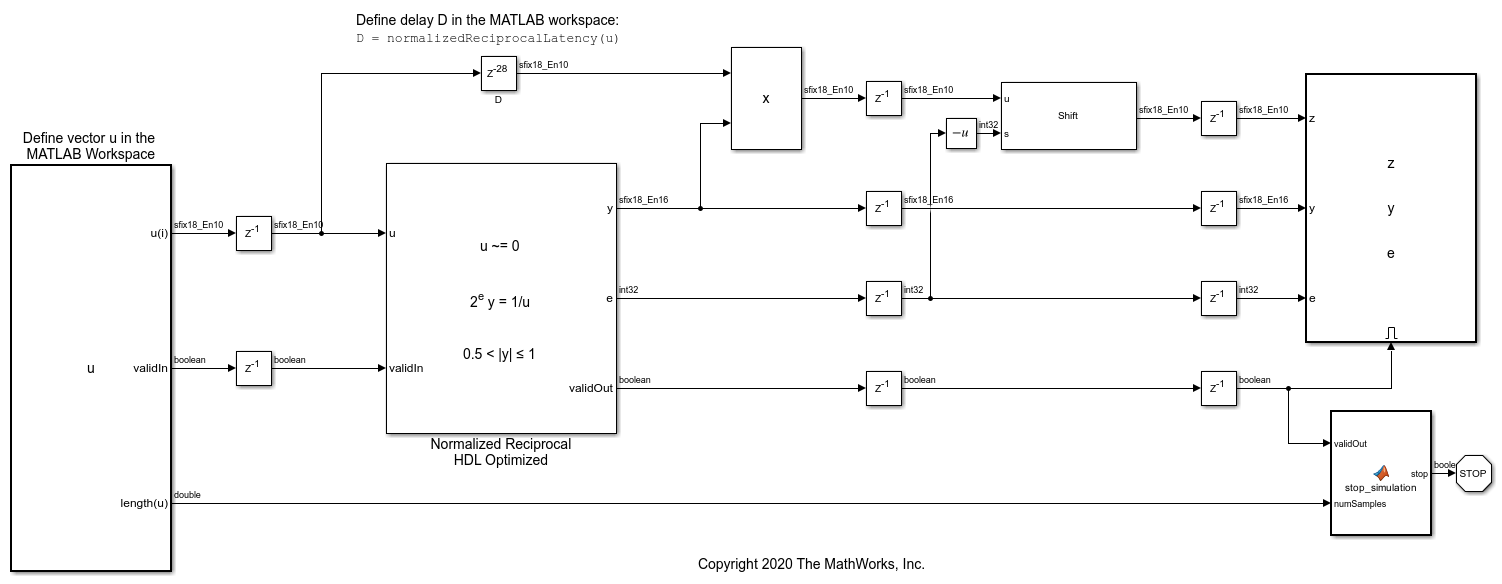
How to Use HDL Optimized Normalized Reciprocal
How and when to use the normalizedReciprocal function and the Normalized Reciprocal HDL Optimized block to compute the normalized reciprocal of an input.
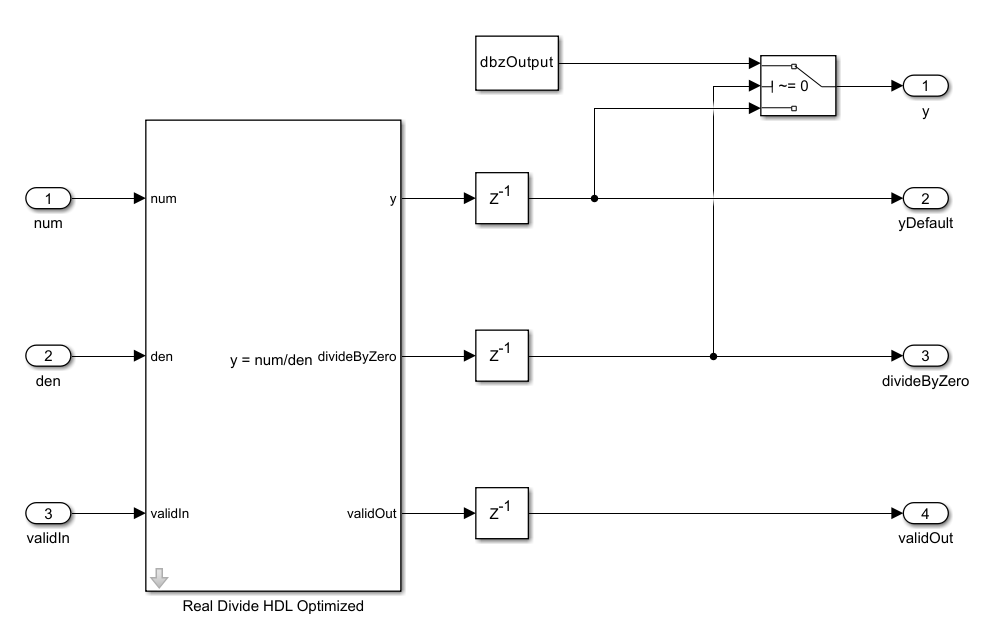
Customize Output Value of Real Divide HDL Optimized Block When Denominator Is Zero
Use the divideByZero port to customize the value of the block output when division by zero occurs.
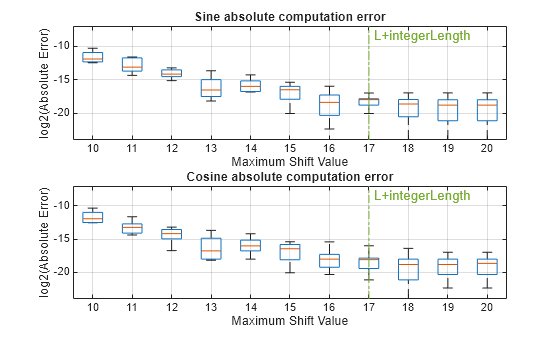
How to Set CORDIC Input Word Length and Maximum Shift Value to Achieve Desired Precision
Provides a starting point for the input data type and number of iterations or maximum shift value required for the CORDIC algorithm to achieve a desired accuracy.
Ports
Input
Output
Parameters
Tips
The behavior of the Normalized Reciprocal HDL Optimized block is equivalent to the
normalizedReciprocalfunction. When the data type of the input is fixed point with binary-point scaling, the function and block provide bit-exact results.
Algorithms
References
[1] Volder, Jack E. “The CORDIC Trigonometric Computing Technique.” IRE Transactions on Electronic Computers EC-8, no. 3 (Sept. 1959): 330–334.
[2] Andraka, Ray. “A Survey of CORDIC Algorithm for FPGA Based Computers.” In Proceedings of the 1998 ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays, 191–200. https://dl.acm.org/doi/10.1145/275107.275139.
[3] Walther, J.S. “A Unified Algorithm for Elementary Functions.” In Proceedings of the May 18-20, 1971 Spring Joint Computer Conference, 379–386. https://dl.acm.org/doi/10.1145/1478786.1478840.
[4] Schelin, Charles W. “Calculator Function Approximation.” The American Mathematical Monthly, no. 5 (May 1983): 317–325. https://doi.org/10.2307/2975781.