강화 학습이란?
강화 학습은 에이전트가 동적 환경과 상호 작용하여 작업을 수행하는 방법을 학습하는 목표 지향 계산 방식입니다. 이 학습 방식에서는 사람의 개입 없이 그리고 목표 달성을 위한 명시적인 프로그래밍 없이도 에이전트가 작업에 대한 누적 보상을 최대화하는 일련의 결정을 내릴 수 있습니다. 다음 다이어그램은 일반적인 형태로 강화 학습 시나리오를 표현한 것입니다.
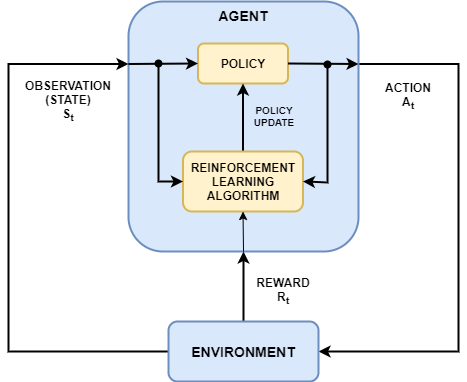
에이전트는 2개의 구성요소인 정책과 학습 알고리즘을 포함합니다.
정책은 환경의 관측값에 기반하여 행동을 선택하는 일종의 매핑입니다. 일반적으로 정책은 조정 가능형 파라미터를 사용하는 함수 근사기(예: 심층 신경망)입니다.
학습 알고리즘은 행동, 관측값, 보상에 기반하여 정책 파라미터를 계속해서 업데이트합니다. 학습 알고리즘의 목표는 작업을 수행하면서 받는 누적 보상을 최대화하는 최적의 정책을 찾는 것입니다.
강화 학습 알고리즘은 (에이전트에게 알려지지 않은) 환경 내에서 에이전트가 작업을 완료하도록 훈련시킵니다. 에이전트는 환경으로부터 관측값과 보상을 받고, 환경으로 행동을 보냅니다. 보상은 작업 목표를 최종적으로 완료하는 데 있어서 행동이 얼마나 성공적이었는지 측정한 것입니다.
즉, 강화 학습은 인간의 개입 없이 에이전트가 환경과 반복적인 시행착오를 거치며 상호 작용함으로써 최적의 동작을 학습하는 과정입니다.
예를 들어 자율 주행 시스템을 사용하여 차량을 주차하는 작업이 있다고 가정해 보겠습니다. 이 작업의 목표는 차량 컴퓨터(에이전트)가 차량을 올바른 위치와 방향으로 주차하는 것입니다. 이를 위해 제어기는 카메라, 가속도계, 자이로스코프, GPS 수신기 및 라이다로부터 수신된 측정값(관측값)을 사용하여 조향, 제동 및 가속 명령(행동)을 생성합니다. 행동 명령은 차량을 제어하는 액추에이터에 전송됩니다. 결과로 생성되는 관측값은 액추에이터, 센서, 차량 동특성, 도로 표면, 바람, 기타 여러 사소한 요소에 따라 달라집니다. 이러한 모든 요소 즉, 에이전트에 해당하지 않는 모든 항목이 강화 학습의 환경을 구성합니다.
관측값에서 올바른 행동을 생성하는 방법을 학습하기 위해 컴퓨터는 시행착오 과정을 거치며 차량 주차를 반복적으로 시도합니다. 학습 과정을 지도하기 위해, 차량이 올바른 위치와 방향으로 제대로 주차된 경우 1에 해당하는 신호를 제공하고, 그 외의 경우에는 0에 해당하는 신호를 제공합니다(보상). 각 시도 시 컴퓨터는 디폴트 값으로 초기화된 매핑(정책)을 사용하여 행동을 선택합니다. 각 시도가 끝나면 컴퓨터는 매핑을 업데이트하여 보상을 최대화합니다(학습 알고리즘). 이 과정은 컴퓨터가 차량을 제대로 주차하는 최적 매핑을 학습할 때까지 계속됩니다.
강화 학습에 사용되는 일반 워크플로에 대한 소개는 강화 학습 워크플로 항목을 참조하십시오.