Deep Learning with Big Data
Typically, training deep neural networks requires large amounts of data that often do not fit in memory. You do not need multiple computers to solve problems using data sets too large to fit in memory. Instead, you can divide your training data into mini-batches that contain a portion of the data set. By iterating over the mini-batches, networks can learn from large data sets without needing to load all data into memory at once.
If your data is too large to fit in memory, use a datastore to work with mini-batches of data for training and inference. MATLAB® provides many different types of datastore tailored for different applications. For more information about datastores for different applications, see Datastores for Deep Learning.
augmentedImageDatastore is specifically designed to preprocess and augment
batches of image data for machine learning and computer vision applications. For more
information, see Preprocess Images for Deep Learning.
Work with Big Data in Parallel
If you want to use large amounts of data to train a network, it can be helpful to train in parallel. Doing so can reduce the time it takes to train a network, because you can train using multiple mini-batches at the same time.
It is recommended to train using a GPU or multiple GPUs. Only use single CPU or multiple CPUs if you do not have a GPU. CPUs are normally much slower than GPUs for both training and inference. Running on a single GPU typically offers much better performance than running on multiple CPU cores.
For more information about training in parallel, see Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud.
Preprocess Data in the Background
Preprocessing large amounts of data can significantly increase training time. To speed up this preprocessing, you can fetch and preprocess training data from a datastore in the background or in parallel.
As shown in this diagram, fetching, preprocessing, and performing training computations in serial can result in downtime where your GPU (or other hardware) utilization is low. Using the background pool or parallel workers to fetch and preprocess the next batch of training data while your GPU is processing the current batch can increase hardware utilization, resulting in faster training. Use background or parallel preprocessing if your training data requires significant preprocessing, such as if you are manipulating large images.
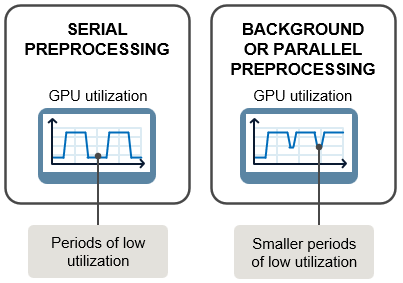
Background and parallel preprocessing use parallel pools to fetch and preprocess data
during training. Background preprocessing uses the backgroundPool, which is a thread-based environment, and parallel
preprocessing uses the current parallel pool or, if no pool is open, starts a pool
using the default cluster profile which is a process-based environment by default.
Thread-based pools have several advantages over process-based pools, and you should
therefore use background preprocessing when possible. However, if your preprocessing
is not supported on threads, or if you need to control the number of workers in the
pool, then use parallel preprocessing. For more information about thread-based and
process-based environments, see Choose Between Thread-Based and Process-Based Environments (Parallel Computing Toolbox).
To preprocess data in the background or in parallel, use one of these options:
For built-in training, specify the
PreprocessingEnvironmentoption as"background"or"parallel"using thetrainingOptionsfunction.For custom training loops, set the
PreprocessingEnvironmentproperty of yourminibatchqueueto"background"or"parallel".
Setting the PreprocessingEnvironment option to
"parallel" is supported for local parallel pools only and
requires Parallel Computing Toolbox™.
To use the "background" or "parallel" options, the input datastore must be subsettable or partitionable. Custom datastores must implement the matlab.io.datastore.Subsettable class.
Work with Big Data in the Cloud
Storing data in the cloud can make it easier for you to access for cloud applications without needing to upload or download large amounts of data each time you create cloud resources. Both AWS® and Azure® offer data storage services, such as AWS S3 and Azure Blob Storage, respectively.
To avoid the time and cost associated with transferring large quantities of data, it is recommended that you set up cloud resources for your deep learning applications using the same cloud provider and region that you use to store your data in the cloud.
To access data stored in the cloud from MATLAB, you must configure your machine with your access credentials. You can configure access from inside MATLAB using environment variables. For more information on how to set environment variables to access cloud data from your client MATLAB, see Work with Remote Data. For more information on how to set environment variables on parallel workers in a remote cluster, see Set Environment Variables on Workers (Parallel Computing Toolbox).
For examples showing how to upload data to the cloud and how to access that data from MATLAB, see Work with Deep Learning Data in AWS and Work with Deep Learning Data in Azure.
For more information about deep learning in the cloud, see Deep Learning in the Cloud.
See Also
trainnet | trainingOptions | dlnetwork | minibatchqueue