이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
trainAutoencoder
오토인코더 훈련
구문
설명
autoenc = trainAutoencoder(X,hiddenSize)hiddenSize인 오토인코더 autoenc를 반환합니다.
autoenc = trainAutoencoder(___,Name,Value)Name,Value 쌍 인수로 지정된 추가 옵션에 대해 오토인코더 autoenc를 반환합니다.
예를 들어, 희소성 비율이나 최대 훈련 반복 횟수를 지정할 수 있습니다.
예제
샘플 데이터를 불러옵니다.
X = abalone_dataset;
X는 전복 껍데기 4,177개의 8가지 특성, 즉 성별(M, F, I(미숙 객체)), 길이, 지름, 높이, 전체 중량, 속살 중량, 내장 중량, 껍데기 중량을 정의하는 8×4,177 행렬입니다. 이 데이터셋에 대한 자세한 내용을 보려면 명령줄에 help abalone_dataset을 입력하십시오.
디폴트 설정으로 희소 오토인코더를 훈련시킵니다.
autoenc = trainAutoencoder(X);
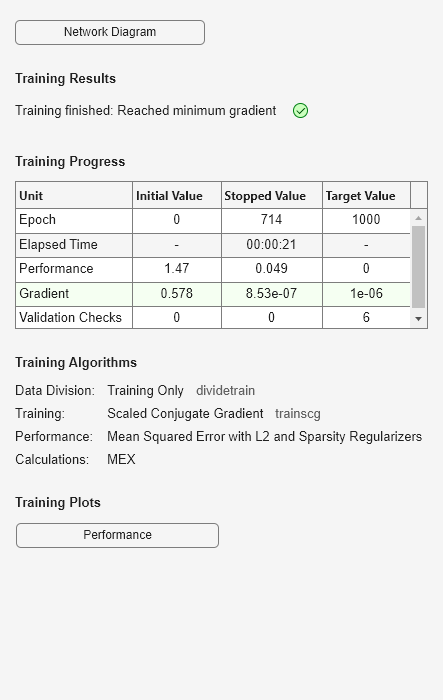
훈련된 오토인코더를 사용하여 전복 껍데기 나이테 데이터를 다시 생성합니다.
XReconstructed = predict(autoenc,X);
이 재구성에 대한 평균제곱오차를 계산합니다.
mseError = mse(X-XReconstructed)
mseError = 0.0167
샘플 데이터를 불러옵니다.
X = abalone_dataset;
X는 전복 껍데기 4,177개의 8가지 특성, 즉 성별(M, F, I(미숙 객체)), 길이, 지름, 높이, 전체 중량, 속살 중량, 내장 중량, 껍데기 중량을 정의하는 8×4,177 행렬입니다. 이 데이터셋에 대한 자세한 내용을 보려면 명령줄에 help abalone_dataset을 입력하십시오.
은닉 크기 4, 최대 Epoch 400회, 디코더에 대한 선형 전달 함수로 희소 오토인코더를 훈련시킵니다.
autoenc = trainAutoencoder(X,4,'MaxEpochs',400,... 'DecoderTransferFunction','purelin');

훈련된 오토인코더를 사용하여 전복 껍데기 나이테 데이터를 다시 생성합니다.
XReconstructed = predict(autoenc,X);
이 재구성에 대한 평균제곱오차를 계산합니다.
mseError = mse(X-XReconstructed)
mseError = 0.0048
훈련 데이터를 생성합니다.
rng(0,'twister'); % For reproducibility n = 1000; r = linspace(-10,10,n)'; x = 1 + r*5e-2 + sin(r)./r + 0.2*randn(n,1);
훈련 데이터를 사용하여 오토인코더를 훈련시킵니다.
hiddenSize = 25; autoenc = trainAutoencoder(x',hiddenSize,... 'EncoderTransferFunction','satlin',... 'DecoderTransferFunction','purelin',... 'L2WeightRegularization',0.01,... 'SparsityRegularization',4,... 'SparsityProportion',0.10);
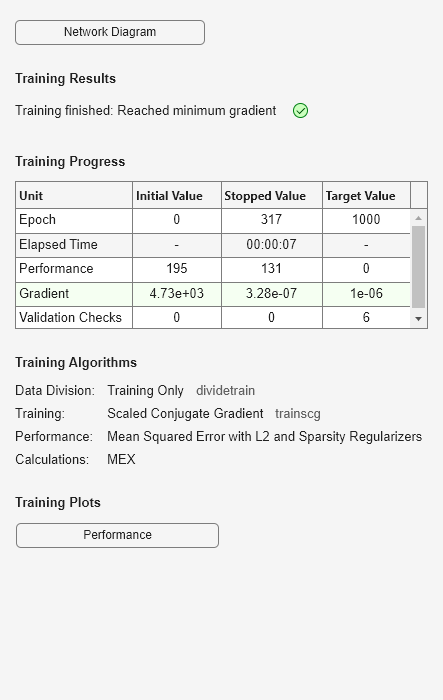
테스트 데이터를 생성합니다.
n = 1000; r = sort(-10 + 20*rand(n,1)); xtest = 1 + r*5e-2 + sin(r)./r + 0.4*randn(n,1);
훈련된 오토인코더 autoenc를 사용하여 테스트 데이터를 예측합니다.
xReconstructed = predict(autoenc,xtest');
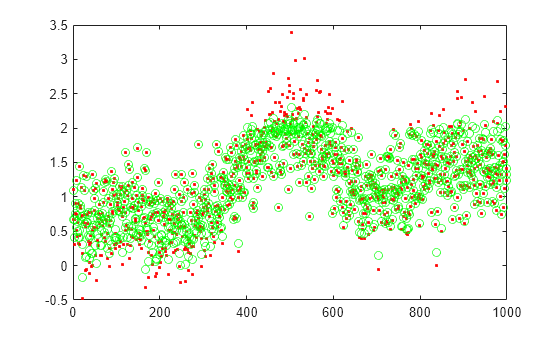
실제 테스트 데이터와 예측값을 플로팅합니다.
figure; plot(xtest,'r.'); hold on plot(xReconstructed,'go');
훈련 데이터를 불러옵니다.
XTrain = digitTrainCellArrayData;
훈련 데이터는 각 셀에 손으로 쓴 숫자를 표현한 합성 영상을 나타내는 28×28 행렬이 있는 1×5,000 셀형 배열입니다.
25개의 뉴런을 포함하는 은닉 계층 1개를 갖는 오토인코더를 훈련시킵니다.
hiddenSize = 25; autoenc = trainAutoencoder(XTrain,hiddenSize,... 'L2WeightRegularization',0.004,... 'SparsityRegularization',4,... 'SparsityProportion',0.15);
테스트 데이터를 불러옵니다.
XTest = digitTestCellArrayData;
테스트 데이터는 각 셀에 손으로 쓴 숫자를 표현한 합성 영상을 나타내는 28×28 행렬이 있는 1×5,000 셀형 배열입니다.
훈련된 오토인코더 autoenc를 사용하여 테스트 영상 데이터를 재생성합니다.
xReconstructed = predict(autoenc,XTest);
실제 테스트 데이터를 표시합니다.
figure; for i = 1:20 subplot(4,5,i); imshow(XTest{i}); end

재생성한 테스트 데이터를 표시합니다.
figure; for i = 1:20 subplot(4,5,i); imshow(xReconstructed{i}); end

입력 인수
이름-값 인수
출력 인수
세부 정보
참고 문헌
[1] Moller, M. F. “A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning”, Neural Networks, Vol. 6, 1993, pp. 525–533.
[2] Olshausen, B. A. and D. J. Field. “Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1.” Vision Research, Vol.37, 1997, pp.3311–3325.
버전 내역
R2015b에 개발됨