Exploring a Nucleotide Sequence Using the Sequence Viewer App
Overview of the Sequence Viewer
The Sequence Viewer integrates many of the sequence functions in the Bioinformatics Toolbox™ toolbox. Instead of entering commands in the MATLAB® Command Window, you can select and enter options using the app.
Importing a Sequence into the Sequence Viewer
The first step when analyzing a nucleotide or amino acid sequence is to import sequence information into the MATLAB environment. The Sequence Viewer can connect to Web databases such as NCBI and EMBL and read information into the MATLAB environment.
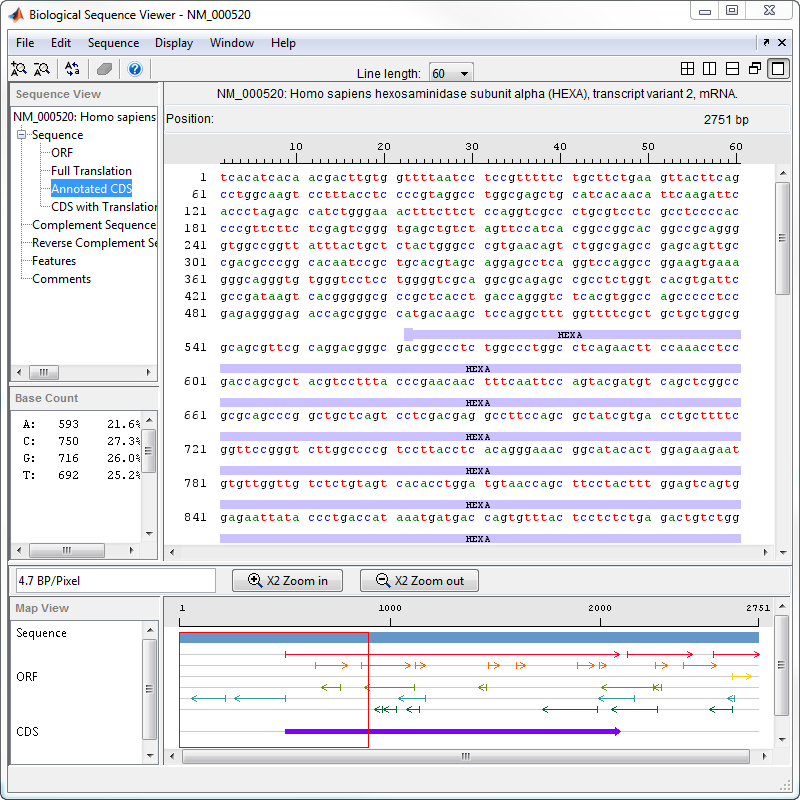
The following procedure illustrates how to retrieve sequence information from the NCBI database on the Web. This example uses the GenBank® accession number NM_000520, which is the human gene HEXA that is associated with Tay-Sachs disease.
Note
Data in public repositories is frequently curated and updated; therefore, the results of this example might be slightly different when you use up-to-date sequences.
In the MATLAB Command Window, type
seqviewer
Alternatively, click Sequence Viewer on the Apps tab.
The Sequence Viewer opens without a sequence loaded. Notice that the panes to the right and bottom are blank.
To retrieve a sequence from the NCBI database, select File > Download Sequence from > NCBI.
The Download Sequence from NCBI dialog box opens.

In the Enter Sequence box, type an accession number for an NCBI database entry, for example, NM_000520. Click the Nucleotide option button, and then click OK.
The MATLAB software accesses the NCBI database on the Web, loads nucleotide sequence information for the accession number you entered, and calculates some basic statistics.

Viewing Nucleotide Sequence Information
After you import a sequence into the Sequence Viewer app, you can read information stored with the sequence, or you can view graphic representations for ORFs and CDSs.
In the left pane tree, click Comments. The right pane displays general information about the sequence.
Now click Features. The right pane displays NCBI feature information, including index numbers for a gene and any CDS sequences.
Click ORF to show the search results for ORFs in the six reading frames.

Click Annotated CDS to show the protein coding part of a nucleotide sequence.
Searching for Words
You can also search for characteristic words or sequence patterns using regular
expressions. You can enter the IUB/IUPAC nucleotide and amino acid symbols that are
automatically converted to corresponding nucleotides and amino acids accordingly.
For details about how symbols are interpreted, see the Nucleotide Conversion and Amino Acid
Conversion tables of seq2regexp. For instance, if you
search for the word 'TAR' with the Regular
Expression box checked, the app highlights all the occurrences of
'TAA' and 'TAG' in the sequence since
R = [AG].
Select Sequence > Find Word.
In the Find Word dialog box, type a sequence word or pattern, for example, atg, and then click Find.

The Sequence Viewer searches and displays the location of the selected word.

Clear the display by clicking the Clear Word Selection button
 on the toolbar.
on the toolbar.
Exploring Open Reading Frames
The following procedure illustrates how to identify the protein coding part of a nucleotide sequence and copy it into a new view. Identifying coding sections of a nucleotide sequence is a common bioinformatics task. After locating the coding part of a sequence, you can copy it to a new view, translate it to an amino acid sequence, and continue with your analysis.
In the left pane, click ORF.
The Sequence Viewer displays the ORFs for the six reading frames in the lower-right pane. Hover the cursor over a frame to display information about it.

Click the longest ORF on reading frame 2.
The ORF is highlighted to indicate the part of the sequence that is selected.

Right-click the selected ORF and then select Export to Workspace. In the Export to MATLAB Workspace dialog box, type a variable name, for example, NM_000520_ORF_2, then click Export.

The NM_000520_ORF_2 variable is added to the MATLAB Workspace.
Select File > Import from Workspace. Type the name of a variable with an exported ORF, for example, NM_000520_ORF_2, and then click Import.
The Sequence Viewer adds a tab at the bottom for the new sequence while leaving the original sequence open.

In the left pane, click Full Translation. Select Display > Amino Acid Residue Display > One Letter Code.
The Sequence Viewer displays the amino acid sequence below the nucleotide sequence.

Closing the Sequence Viewer
Close the Sequence Viewer from the MATLAB command line using the following syntax:
seqviewer('close')