이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
음성 전사(Speech Transcription) 및 합성
Audio Toolbox™는 소용량 어휘(small-vocabulary) 인식 및 사운드 합성에 대한 예제를 제공합니다. 사전 훈련된 모델을 사용하면 speech2text 및 text2speech를 사용하여 일반적인 음성-텍스트 전사 및 텍스트-음성 합성을 수행할 수 있습니다. 널리 사용되는 타사 API에 대한 인터페이스를 통해 텍스트-음성 변환 및 음성-텍스트 변환을 위한 Audio Toolbox 확장 기능을 File Exchange에서 다운로드할 수 있습니다. 지원되는 API에는 Google®, IBM® Watson, Microsoft® Azure, Amazon® 등이 있습니다.
신호 레이블 지정기 앱에서 음성-텍스트 변환 기능과 시각적으로 상호 작용하여 음성 영역에 빠르게 레이블을 지정할 수 있습니다.
앱
| 신호 레이블 지정기 | 관심 있는 신호 특성, 신호 영역 및 신호 지점에 레이블 지정하기 |
함수
speech2text | Transcribe speech signal to text (R2022b 이후) |
text2speech | Synthesize speech from text (R2022b 이후) |
speechClient | Interface with pretrained model or third-party speech service (R2022b 이후) |
identifyLanguage | Identify languages in speech signals (R2024b 이후) |
도움말 항목
- Label Spoken Words in Audio Signals
Use Signal Labeler to label spoken words in an audio signal.
- Speaker Diarization Using Pretrained AI Models
Use the
speakerEmbeddingsfunction to extract compact speaker representations and perform speaker diarization. (R2024b 이후)
추천 예제
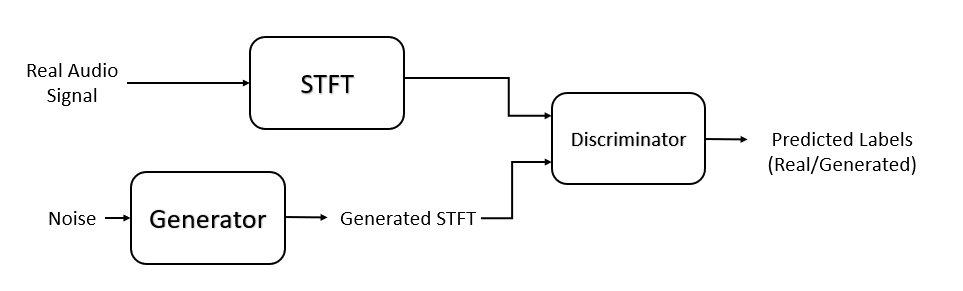
Train Generative Adversarial Network (GAN) for Sound Synthesis
Train and use a generative adversarial network (GAN) to generate sounds.

LPC Analysis and Synthesis of Speech
Use the Levinson-Durbin and Time-Varying Lattice Filter blocks for low-bandwidth transmission of speech using linear predictive coding.