이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
독일어 텍스트 데이터 분석하기
이 예제에서는 토픽 모델을 사용하여 독일어 텍스트 데이터를 가져와서 준비하고 분석하는 방법을 보여줍니다.
독일어 텍스트 데이터가 클수록 통계 분석에 부정적 영향을 주는 잡음 데이터가 많이 들어 있을 수 있습니다. 예를 들어, 텍스트 데이터에 다음이 포함되어 있을 수 있습니다.
어형이 변형된 단어. 예를 들면 „rot“, „rote“, „roten“입니다.
잡음을 추가하는 단어. 예를 들면 „der“, „die“, „das“와 같은 불용어입니다.
문장 부호 및 특수 문자.
다음 워드 클라우드는 원시 텍스트 데이터에 단어 빈도 분석을 적용한 버전과 동일한 텍스트 데이터를 전처리한 버전을 나타낸 것입니다.

이 예제에서는 먼저 독일어 텍스트 데이터를 가져와서 준비하는 방법을 보여준 다음, LDA(잠재 디리클레 할당) 모델을 사용하여 텍스트 데이터를 분석하는 방법을 보여줍니다. LDA 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 토픽 모델입니다. 텍스트 데이터를 준비하고 모델을 피팅할 때 수행할 단계는 다음과 같습니다.
CSV 파일에서 텍스트 데이터를 가져오고 관련 데이터를 추출합니다.
표준 전처리 기법을 사용하여, 분석할 텍스트 데이터를 준비합니다.
토픽 모델을 피팅하고 결과를 시각화합니다.
데이터 가져오기
예제 데이터 "FabrikBerichte.csv"를 불러옵니다. 이 데이터에는 각 이벤트에 대한 독일어 텍스트 설명과 범주 레이블이 포함된 공장 보고서가 들어 있습니다.
readtable 함수를 사용하여 데이터를 읽어옵니다. 텍스트 유형을 string형으로 설정합니다. 열 제목 중 하나에 움라우트("Auflösung")가 포함되어 있습니다. 이 이름을 유지하려면 VariableNamingRule을 "preserve"로 설정합니다. 그렇지 않으면 MATLAB은 경고를 표시하고 열 제목에서 움라우트를 제거합니다.
filename = "FabrikBerichte.csv"; data = readtable(filename,TextType="string",VariableNamingRule="preserve"); head(data)
Beschreibung Kategorie Dringlichkeit Auflösung Kosten
__________________________________________________________________________________ _____________________ _____________ __________________________________ ______
"Im Inneren des Mixers ist ein lautes Rasseln zu hören." "Mechanischer Fehler" "Niedrig" "Zur Beobachtungsliste hinzufügen" 72
"Ein paar Tropfen Flüssigkeit zeigen sich unter dem Konstruktionsaggregat." "Leck" "Mittel" "Zur Beobachtungsliste hinzufügen" 63
"Einige Materialien, die vom Konstruktionsaggregat erzeugt werden, sind verdreht." "Mechanischer Fehler" "Niedrig" "Maschine neu einstellen" 44
"Eine Sicherung in der Controller-Montage ist durchgebrannt." "Elektrischer Fehler" "Niedrig" "Komponenten ersetzen" 348
"Im Mischer ist eine Sicherung durchgebrannt." "Elektrischer Fehler" "Niedrig" "Komponenten ersetzen" 441
"Es ist ein schlagendes Geräusch zu hören im Zylinder Konstruktionsaggregat." "Mechanischer Fehler" "Mittel" "Maschine neu einstellen" 35
"Der Scanner produziert seltsame elektrische Geräusche." "Elektrischer Fehler" "Niedrig" "Zur Beobachtungsliste hinzufügen" 80
"Abnormales Überhitzen der Sortieranlage." "Leck" "Hoch" "Vollständiger Ersatz" 9000
변수 Beschreibung(공장 이벤트에 대한 설명)에서 텍스트 데이터를 추출합니다.
textData = data.Beschreibung;
텍스트 데이터를 워드 클라우드로 시각화합니다.
figure wordcloud(textData);

텍스트 데이터 토큰화하기
tokenizedDocument 함수를 사용하여 토큰화된 문서로 구성된 배열을 만듭니다.
documents = tokenizedDocument(textData); documents(1:10)
ans =
10×1 tokenizedDocument:
11 tokens: Im Inneren des Mixers ist ein lautes Rasseln zu hören .
10 tokens: Ein paar Tropfen Flüssigkeit zeigen sich unter dem Konstruktionsaggregat .
12 tokens: Einige Materialien , die vom Konstruktionsaggregat erzeugt werden , sind verdreht .
8 tokens: Eine Sicherung in der Controller-Montage ist durchgebrannt .
7 tokens: Im Mischer ist eine Sicherung durchgebrannt .
11 tokens: Es ist ein schlagendes Geräusch zu hören im Zylinder Konstruktionsaggregat .
7 tokens: Der Scanner produziert seltsame elektrische Geräusche .
5 tokens: Abnormales Überhitzen der Sortieranlage .
6 tokens: Akustisches elektrisches Geräusch im Arbeitsagenten .
12 tokens: Nach der Installation der Software ist keine Verbindung zum Netzwerk möglich .
품사 태그 가져오기
addPartOfSpeechDetails 함수를 사용하여 품사 세부 정보를 추가합니다.
documents = addPartOfSpeechDetails(documents);
토큰 세부 정보를 가져온 다음 처음 몇 개 토큰에 대한 세부 정보를 표시합니다.
tdetails = tokenDetails(documents); head(tdetails)
Token DocumentNumber SentenceNumber LineNumber Type Language PartOfSpeech
_________ ______________ ______________ __________ _______ ________ ____________
"In" 1 1 1 letters de adposition
"dem" 1 1 1 letters de determiner
"Inneren" 1 1 1 letters de noun
"des" 1 1 1 letters de determiner
"Mixers" 1 1 1 letters de noun
"ist" 1 1 1 letters de verb
"ein" 1 1 1 letters de determiner
"lautes" 1 1 1 letters de adjective
테이블의 PartOfSpeech 변수에는 토큰의 품사 태그가 포함되어 있습니다. 모두 명사로만 구성된 워드 클라우드와 모두 형용사로만 구성된 워드 클라우드를 각각 만듭니다.
figure idx = tdetails.PartOfSpeech == "noun"; tokens = tdetails.Token(idx); subplot(1,2,1) wordcloud(tokens); title("Nouns") idx = tdetails.PartOfSpeech == "adjective"; tokens = tdetails.Token(idx); subplot(1,2,2) wordcloud(tokens); title("Adjectives")

분석할 텍스트 데이터 준비하기
tokenizedDocument를 사용하여 텍스트를 토큰화한 다음 처음 몇 개 문서를 표시합니다.
documentsRaw = tokenizedDocument(textData); documents = documentsRaw; documents(1:10)
ans =
10×1 tokenizedDocument:
11 tokens: Im Inneren des Mixers ist ein lautes Rasseln zu hören .
10 tokens: Ein paar Tropfen Flüssigkeit zeigen sich unter dem Konstruktionsaggregat .
12 tokens: Einige Materialien , die vom Konstruktionsaggregat erzeugt werden , sind verdreht .
8 tokens: Eine Sicherung in der Controller-Montage ist durchgebrannt .
7 tokens: Im Mischer ist eine Sicherung durchgebrannt .
11 tokens: Es ist ein schlagendes Geräusch zu hören im Zylinder Konstruktionsaggregat .
7 tokens: Der Scanner produziert seltsame elektrische Geräusche .
5 tokens: Abnormales Überhitzen der Sortieranlage .
6 tokens: Akustisches elektrisches Geräusch im Arbeitsagenten .
12 tokens: Nach der Installation der Software ist keine Verbindung zum Netzwerk möglich .
불용어를 제거합니다.
documents = removeStopWords(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
6 tokens: Inneren Mixers lautes Rasseln hören .
6 tokens: paar Tropfen Flüssigkeit zeigen Konstruktionsaggregat .
8 tokens: Einige Materialien , Konstruktionsaggregat erzeugt , verdreht .
4 tokens: Sicherung Controller-Montage durchgebrannt .
4 tokens: Mischer Sicherung durchgebrannt .
6 tokens: schlagendes Geräusch hören Zylinder Konstruktionsaggregat .
6 tokens: Scanner produziert seltsame elektrische Geräusche .
4 tokens: Abnormales Überhitzen Sortieranlage .
5 tokens: Akustisches elektrisches Geräusch Arbeitsagenten .
6 tokens: Installation Software Verbindung Netzwerk möglich .
normalizeWords 함수를 사용하여 텍스트를 정규화합니다.
documents = normalizeWords(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
6 tokens: inn mix laut rasseln hor .
6 tokens: paar tropf flussig zeig konstruktionsaggregat .
8 tokens: einig materiali , konstruktionsaggregat erzeugt , verdreht .
4 tokens: sicher controller-montag durchgebrannt .
4 tokens: misch sicher durchgebrannt .
6 tokens: schlagend gerausch hor zylind konstruktionsaggregat .
6 tokens: scann produziert seltsam elektr gerausch .
4 tokens: abnormal uberhitz sortieranlag .
5 tokens: akust elektr gerausch arbeitsagent .
6 tokens: installation softwar verbind netzwerk moglich .
erasePunctuation 함수를 사용하여 문장 부호를 지웁니다.
documents = erasePunctuation(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
5 tokens: inn mix laut rasseln hor
5 tokens: paar tropf flussig zeig konstruktionsaggregat
5 tokens: einig materiali konstruktionsaggregat erzeugt verdreht
3 tokens: sicher controllermontag durchgebrannt
3 tokens: misch sicher durchgebrannt
5 tokens: schlagend gerausch hor zylind konstruktionsaggregat
5 tokens: scann produziert seltsam elektr gerausch
3 tokens: abnormal uberhitz sortieranlag
4 tokens: akust elektr gerausch arbeitsagent
5 tokens: installation softwar verbind netzwerk moglich
원시 데이터와 정리된 데이터를 워드 클라우드로 시각화합니다.
figure subplot(1,2,1) wordcloud(documentsRaw); title("Raw Data") subplot(1,2,2) wordcloud(documents); title("Cleaned Data")

전처리 함수 만들기
전처리를 수행하는 함수를 만들면 서로 다른 텍스트 데이터 모음을 동일한 방식으로 준비하는 데 유용할 수 있습니다. 예를 들어, 함수를 사용하여 훈련 데이터와 동일한 단계로 새 데이터를 전처리할 수 있습니다.
분석에 사용할 텍스트 데이터를 토큰화하고 전처리하는 함수를 만듭니다. 이 예제의 마지막에 나오는 함수 preprocessGermanText는 다음 단계를 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.removeStopWords를 사용하여 불용어 목록(예: „der“, „die“, „das“)을 제거합니다.normalizeWords를 사용하여 단어를 정규화합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.
removeEmptyDocuments 함수를 사용하여, 전처리한 후의 빈 문서를 제거합니다. 별도의 배열에 저장된 관련 데이터(예: 타임스탬프 또는 레이블)가 있는 경우에는 그에 대응하는 요소도 제거합니다. 제거할 요소의 인덱스를 얻기 위해 제거된 문서의 인덱스도 반환합니다.
이 예제에서는 전처리 함수 preprocessGermanText(예제 끝에 나와 있음)를 사용하여 텍스트 데이터를 준비합니다.
documents = preprocessGermanText(textData); documents(1:5)
ans =
5×1 tokenizedDocument:
5 tokens: inn mix laut rasseln hor
5 tokens: paar tropf flussig zeig konstruktionsaggregat
5 tokens: einig materiali konstruktionsaggregat erzeugt verdreht
3 tokens: sicher controllermontag durchgebrannt
3 tokens: misch sicher durchgebrannt
removeEmptyDocuments 함수를 사용하여 빈 문서를 제거합니다.
documents = removeEmptyDocuments(documents);
토픽 모델 피팅하기
데이터에 LDA(잠재 디리클레 할당) 토픽 모델을 피팅합니다. LDA 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정합니다.
데이터에 LDA 모델을 피팅하려면 먼저 bag-of-words 모델을 만들어야 합니다. bag-of-words 모델(단어 빈도 카운터라고도 함)은 단어가 문서 모음의 각 문서에서 나타나는 횟수를 기록합니다. bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents);
bag-of-words 모델에서 빈 문서를 제거합니다.
bag = removeEmptyDocuments(bag);
fitlda를 사용하여 7개 토픽으로 LDA 모델을 피팅합니다. 세부 정보가 출력되지 않도록 하려면 'Verbose'를 0으로 설정하십시오.
numTopics = 7; mdl = fitlda(bag,numTopics,Verbose=0);
워드 클라우드를 사용하여 처음 4개 토픽을 시각화합니다.
figure for i = 1:4 subplot(2,2,i) wordcloud(mdl,i); title("Topic " + i) end

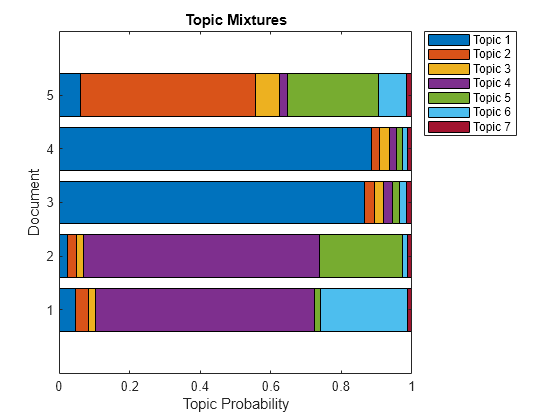
누적형 막대 차트를 사용하여 여러 토픽 혼합을 시각화합니다. 무작위로 5개의 입력 문서를 표시하고 해당하는 토픽 혼합을 시각화합니다.
numDocuments = numel(documents); idx = randperm(numDocuments,5); documents(idx)
ans =
5×1 tokenizedDocument:
4 tokens: seltsam rasseln intern misch
4 tokens: ausstoss konstruktionsaggregat sammelt flussig
3 tokens: abnormal uberhitz sortieranlag
4 tokens: roboterarm gibt schwarz rauch
3 tokens: misch schaltet manchmal
topicMixtures = transform(mdl,documents(idx)); figure barh(topicMixtures(1:5,:),"stacked") xlim([0 1]) title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend("Topic " + string(1:numTopics),Location="northeastoutside")
예제 전처리 함수
함수 preprocessGermanText는 다음 단계를 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.removeStopWords를 사용하여 불용어 목록(예: „der“, „die“, „das“)을 제거합니다.normalizeWords를 사용하여 단어를 정규화합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.
function documents = preprocessGermanText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Remove a list of stop words. documents = removeStopWords(documents); % Normalize the words. documents = normalizeWords(documents); % Erase the punctuation. documents = erasePunctuation(documents); end
참고 항목
tokenizedDocument | removeStopWords | stopWords | addPartOfSpeechDetails | tokenDetails | normalizeWords