이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
고차원 데이터를 분류하기 위해 특징 선택하기
이 예제에서는 고차원 데이터를 분류하기 위해 특징을 선택하는 방법을 보여줍니다. 더 구체적으로, 이 예제에서는 순차적 특징 선택을 수행하는 방법을 보여줍니다. 이는 가장 널리 사용되는 특징 선택 알고리즘 중 하나입니다. 또한, 홀드아웃 검증 및 교차 검증을 사용하여 선택한 특징의 성능을 평가하는 방법도 보여줍니다.
통계적 학습에서는 특징 개수(차원 수)를 줄이는 것이 중요합니다. 생물정보학 데이터처럼 특징의 수는 많고 관측값 수는 한정된 데이터 세트의 경우, 일반적으로 특징의 상당수가 원하는 학습 결과의 생성에 유용하지 않으며 한정된 관측값으로 인해 학습 알고리즘이 잡음에 과적합될 수 있습니다. 특징 개수를 줄이면 저장 공간과 계산 시간을 절약하고 설명력(comprehensibility)을 늘릴 수 있습니다.
특징 개수를 줄이는 주요 접근법으로는 특징 선택과 특징 변환 두 가지가 있습니다. 특징 선택 알고리즘은 원래 특징 집합에서 일부 특징을 선택하며, 특징 변환 방법은 원래의 고차원 특징 공간에서 축소된 차원의 새 공간으로 데이터를 변환합니다.
데이터 불러오기
혈청 단백체 패턴 진단은 질병에 걸린 환자와 질병에 걸리지 않은 환자의 관측값을 구별하는 데 사용될 수 있습니다. 프로파일 패턴은 SELDI(Surface-Enhanced Laser Desorption and Ionization) 단백질 질량 분석을 사용하여 생성됩니다. 이들 특징은 특정 질량/전하 값에서의 이온 강도 수준을 나타냅니다.
이 예제에서는 WCX2 단백질 배열을 사용하여 생성된 고해상도 난소암 데이터 세트를 사용합니다. Bioinformatics Toolbox™ Preprocessing Raw Mass Spectrometry Data (Bioinformatics Toolbox) 예제에서 설명한 것과 비슷한 전처리 과정을 거치면 이 데이터 세트는 obs 및 grp라는 두 개의 변수를 가지게 됩니다. obs 변수는 4000개 특징을 갖는 216개 관측값으로 구성됩니다. grp의 각 요소는 obs에서 대응하는 행이 속하는 그룹을 정의합니다.
load ovariancancer;
whosName Size Bytes Class Attributes grp 216x1 28512 cell obs 216x4000 3456000 single
데이터를 훈련 세트와 테스트 세트로 나누기
이 예제에서 사용하는 일부 함수는 MATLAB®의 난수 생성 함수를 호출합니다. 이 예제가 보여주는 결과를 정확히 재현할 수 있도록 아래 명령을 실행하여 난수 생성기를 알려진 상태로 설정하십시오. 이렇게 하지 않으면 다른 결과가 나올 수 있습니다.
rng(8000,'twister');훈련 데이터에 대한 성능(재대입 성능)은 독립적인 테스트 세트에 대한 모델의 성능을 추정하기에 좋은 척도가 아닙니다. 재대입 성능은 일반적으로 지나치게 낙관적입니다. 선택한 모델의 성능을 예측하려면 모델 생성에 사용하지 않은 다른 데이터 세트로 성능을 평가해야 합니다. 여기서는 cvpartition을 사용하여 크기가 160인 훈련 세트와 크기가 56인 테스트 세트로 데이터를 나눕니다. 훈련 세트와 테스트 세트 모두 그룹 비율이 grp와 거의 동일합니다. 훈련 데이터를 사용하여 특징을 선택하고 검정 데이터를 사용하여 선택한 특징의 성능을 판단합니다. 이를 대개 홀드아웃 검증이라고 합니다. 모델 평가와 선택에 널리 사용되는 또 다른 간단한 방법은 교차 검증입니다. 이 검증법은 예제의 뒷부분에서 설명하겠습니다.
holdoutCVP = cvpartition(grp,'holdout',56)holdoutCVP =
Hold-out cross validation partition
NumObservations: 216
NumTestSets: 1
TrainSize: 160
TestSize: 56
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
dataTrain = obs(holdoutCVP.training,:); grpTrain = grp(holdoutCVP.training);
모든 특징을 사용하여 데이터를 분류할 때 발생하는 문제
특징의 수를 먼저 줄이지 않을 경우 특징의 개수가 관측값 개수보다 훨씬 더 크기 때문에 이 예제에 사용된 데이터 세트에서 일부 분류 알고리즘이 실패할 수 있습니다. 이 예제에서는 분류 알고리즘으로 2차 판별분석(QDA)을 사용합니다. 다음에 표시된 것처럼 모든 특징을 사용하여 데이터에 QDA를 적용할 경우 공분산 행렬을 추정하기에 충분한 표본이 각 그룹에 없으므로 오류가 발생합니다.
try yhat = classify(obs(test(holdoutCVP),:), dataTrain, grpTrain,'quadratic'); catch ME display(ME.message); end
The covariance matrix of each group in TRAINING must be positive definite.
단순 필터 접근법을 사용하여 특징 선택하기
우리의 목표는 뛰어난 분류 성능을 제공할 수 있는, 적은 수의 중요한 특징의 집합을 구해서 데이터의 차원을 줄이는 것입니다. 특징 선택 알고리즘은 대략적으로 두 가지 범주, 즉 필터 방법과 래퍼 방법으로 그룹화할 수 있습니다. 필터 방법은 선택한 학습 알고리즘(이 예제의 경우 QDA)을 사용하지 않고 데이터의 일반적인 특성을 기반으로 특징의 부분 집합을 평가하고 선택합니다. 래퍼 방법은 선택한 학습 알고리즘의 성능을 활용하여 각 후보 특징의 부분 집합을 평가합니다. 래퍼 방법은 선택한 학습 알고리즘에 더욱 잘 맞는 특징을 탐색하지만, 학습 알고리즘의 실행 시간이 길 경우 필터 방법보다 훨씬 느릴 수 있습니다. "필터" 및 "래퍼"라는 개념은 John G. Kohavi R. (1997) "Wrappers for feature subset selection", Artificial Intelligence, Vol.97, No.1-2, pp.272-324에 설명되어 있습니다. 이 예제에서는 필터 방법의 한 사례와 래퍼 방법의 한 사례를 보여줍니다.
필터는 간단하고 빠르기 때문에 전처리 과정에 일반적으로 사용됩니다. 생물정보학 데이터에 널리 사용하는 필터 방법은 특징 간에 상호 작용이 없다는 가정 하에 각 특징마다 개별적으로 일변량 기준을 적용합니다.
예를 들어, 각 특징에 t-검정을 적용하고 각 특징의 p-값(또는 t-통계량의 절댓값)을 비교하여 해당 특징이 얼마나 효과적으로 그룹을 분리하는지 측정할 수 있습니다.
dataTrainG1 = dataTrain(grp2idx(grpTrain)==1,:); dataTrainG2 = dataTrain(grp2idx(grpTrain)==2,:); [h,p,ci,stat] = ttest2(dataTrainG1,dataTrainG2,'Vartype','unequal');
두 그룹이 각 특징별로 얼마나 잘 분리되었는지를 개략적으로 파악하기 위해 p-값의 경험적 누적 분포 함수(CDF)를 플로팅하겠습니다.
ecdf(p); xlabel('P value'); ylabel('CDF value')
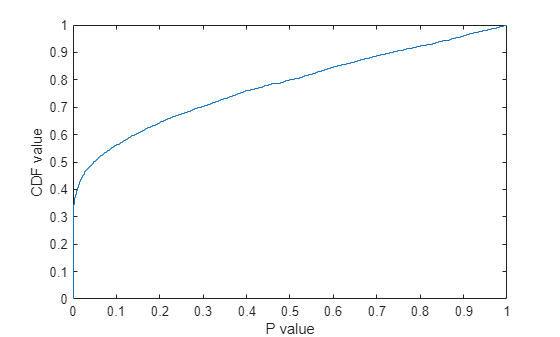
p-값이 0에 가까운 특징은 약 35%이고 p-값이 0.05보다 작은 특징은 50%가 넘습니다. 이는 5000개의 원래 특징 중 우수한 변별력을 가지는 특징이 2500개가 넘음을 의미합니다. p-값(또는 t-통계량의 절댓값)을 기준으로 이러한 특징을 정렬하고 정렬된 목록에서 일부 특징을 선택할 수 있습니다. 하지만 이 분야의 지식이 있거나 또는 고려할 수 있는 특징의 최대 개수가 외부 제약 조건에 의해 미리 정해져 있는 경우가 아니라면 얼마나 많은 특징이 필요할지 결정하기가 쉽지 않습니다.
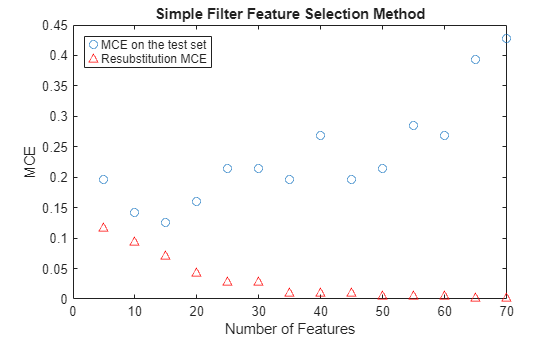
필요한 특징의 개수를 빠르게 구하는 한 방법은 테스트 세트의 MCE(오분류 오차, 즉 오분류된 관측값 개수를 전체 관측값 개수로 나눈 값)를 특징 개수에 대한 함수로 플로팅하는 것입니다. 훈련 세트에는 관측값이 160개만 있으므로 QDA를 적용할 특징의 최대 개수가 제한됩니다. 그렇지 않으면 각 그룹에 들어있는 표본이 공분산 행렬을 추정하기에 충분하지 않을 수 있습니다. 실제로, 이 예제에서 사용된 데이터의 경우 QDA를 적용할 특징의 최대 개수가 홀드아웃 분할 그리고 두 그룹의 크기에 의해 약 70개로 정해집니다. 이제, 특징 개수가 5개에서 70개 사이로 다양한 경우에 대한 MCE를 계산하여 특징 개수에 대한 함수로 플로팅해 보겠습니다. 선택한 모델의 성능을 적절하게 추정하기 위해 중요한 것은 160개 훈련 표본을 사용하여 QDA 모델을 피팅하고 56개 검정 관측값에 대한 MCE(아래 플롯에서 파란색 원 표시)를 계산하는 것입니다. 재대입 오차가 검정 오차에 대한 양호한 오차 추정값이 아닌 이유를 살펴보기 위해 빨간색 삼각형 표시를 사용하여 재대입 MCE도 표시하겠습니다.
[~,featureIdxSortbyP] = sort(p,2); % sort the features testMCE = zeros(1,14); resubMCE = zeros(1,14); nfs = 5:5:70; classf = @(xtrain,ytrain,xtest,ytest) ... sum(~strcmp(ytest,classify(xtest,xtrain,ytrain,'quadratic'))); resubCVP = cvpartition(length(grp),'resubstitution')
resubCVP =
Resubstitution (no partition of data)
NumObservations: 216
NumTestSets: 1
TrainSize: 216
TestSize: 216
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
for i = 1:14 fs = featureIdxSortbyP(1:nfs(i)); testMCE(i) = crossval(classf,obs(:,fs),grp,'partition',holdoutCVP)... /holdoutCVP.TestSize; resubMCE(i) = crossval(classf,obs(:,fs),grp,'partition',resubCVP)/... resubCVP.TestSize; end plot(nfs, testMCE,'o',nfs,resubMCE,'r^'); xlabel('Number of Features'); ylabel('MCE'); legend({'MCE on the test set' 'Resubstitution MCE'},'location','NW'); title('Simple Filter Feature Selection Method');
편의를 위해 classf는 익명 함수로 정의합니다. 이 함수는 주어진 훈련 세트에 대해 QDA를 피팅하고 주어진 테스트 세트에 대해 오분류된 표본의 수를 반환합니다. 고유한 분류 알고리즘을 직접 개발하는 중이라면 이 함수를 다음과 같이 별도의 파일에 넣을 수 있습니다.
% function err = classf(xtrain,ytrain,xtest,ytest) % yfit = classify(xtest,xtrain,ytrain,'quadratic'); % err = sum(~strcmp(ytest,yfit));
재대입 MCE는 지나치게 낙관적입니다. 재대입 MCE는 더 많은 특징이 사용될수록 지속적으로 감소하며 60개가 넘는 특징이 사용되면 0으로 떨어집니다. 그러나 재대입 오차가 계속 감소하는데도 검정 오차가 증가한다면 과적합이 발생했을 수 있습니다. 이 단순 필터 특징 선택 방법은 특징을 15개 사용했을 때 테스트 세트에 대한 MCE가 가장 작습니다. 플롯을 보면 특징을 20개 이상 사용할 때부터 과적합이 발생하기 시작함을 알 수 있습니다. 테스트 세트에 대한 최저 MCE는 12.5%입니다.
testMCE(3)
ans = 0.1250
다음은 최소 MCE를 달성하는 첫 15개의 특징입니다.
featureIdxSortbyP(1:15)
ans = 1×15
2814 2813 2721 2720 2452 2645 2644 2642 2650 2643 2731 2638 2730 2637 2398
순차적 특징 선택 적용하기
위에서 살펴본 특징 선택 알고리즘은 특징 간의 상호 작용을 고려하지 않았습니다. 게다가 목록에서 순위를 기준으로 선택된 특징에는 중복된 정보가 포함될 수도 있기 때문에 모든 특징이 필요하지는 않습니다. 예를 들어, 첫 번째 선택된 특징(열 2814)과 두 번째 선택된 특징(열 2813) 사이의 선형 상관 계수는 거의 0.95입니다.
corr(dataTrain(:,featureIdxSortbyP(1)),dataTrain(:,featureIdxSortbyP(2)))
ans = single
0.9447
이처럼 단순하게 특징을 선택하는 절차는 빠르기 때문에 일반적으로 전처리 과정으로 사용됩니다. 더 정교한 특징 선택 알고리즘은 성능을 향상시킵니다. 순차적 특징 선택은 가장 널리 사용되는 기법 중 하나입니다. 순차적 특징 선택은 특정 중지 조건이 충족될 때까지 특징을 순차적으로 추가(순방향 탐색)하거나 제거(역방향 탐색)하는 방식으로 특징의 부분 집합을 선택합니다.
이 예제에서는 래퍼 방식으로 순방향 순차적 특징 선택을 사용하여 중요한 특징을 찾아 보겠습니다. 더 구체적으로 말하면 분류의 목적은 일반적으로 MCE를 최소화하는 것입니다. 따라서 특징 선택 절차는 각 후보 특징의 부분 집합에 대해 순차적 탐색을 수행하면서 학습 알고리즘 QDA의 MCE를 그 부분 집합에 대한 성능 표시자로 사용합니다. 훈련 세트는 특징을 선택하고 QDA 모델을 피팅하는 데 사용하고, 테스트 세트는 최종 선택된 특징의 성능을 평가하는 데 사용합니다. 특징 선택 절차를 수행하는 동안 각 후보 특징의 부분 집합의 성능을 평가, 비교하기 위해 훈련 세트에 층화된 10겹 교차 검증을 적용해 보겠습니다. 훈련 세트에 교차 검증을 적용하는 것이 왜 중요한지에 대해서는 나중에 살펴보겠습니다.
먼저, 훈련 세트에 대한 층화된 10겹 분할을 생성합니다.
tenfoldCVP = cvpartition(grpTrain,'kfold',10)tenfoldCVP =
K-fold cross validation partition
NumObservations: 160
NumTestSets: 10
TrainSize: [144 144 144 144 144 144 144 144 144 144]
TestSize: [16 16 16 16 16 16 16 16 16 16]
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
그런 다음, 앞 섹션에서 전처리 과정을 통해 얻은 필터 결과를 사용하여 특징을 선택합니다. 예를 들어, 여기서는 150개 특징을 선택하겠습니다.
fs1 = featureIdxSortbyP(1:150);
이 150개 특징에 대해 순방향 순차적 특징 선택을 적용합니다. 함수 sequentialfs는 필요한 특징 개수를 결정할 수 있는 간단한 방법(디폴트 옵션)입니다. 이 함수는 교차 검증 MCE의 첫 번째 국소 최솟값을 구하면 중지합니다.
fsLocal = sequentialfs(classf,dataTrain(:,fs1),grpTrain,'cv',tenfoldCVP);선택된 특징은 다음과 같습니다.
fs1(fsLocal)
ans = 1×3
2337 864 3288
이 세 개의 특징을 가지고 선택한 모델의 성능을 평가하기 위해 56개 검정 표본에 대한 MCE를 계산합니다.
testMCELocal = crossval(classf,obs(:,fs1(fsLocal)),grp,'partition',... holdoutCVP)/holdoutCVP.TestSize
testMCELocal = 0.0714
세 개의 특징만 선택했을 때의 MCE는 단순 필터 특징 선택 방법을 사용한 최소 MCE의 절반을 조금 넘는 수준입니다.
이 알고리즘은 중도에 중지되었을 수 있습니다. 경우에 따라 적절한 특징 개수 범위 내에서 교차 검증 MCE의 최솟값을 구함으로써 더 작은 MCE를 얻을 수도 있습니다. 예를 들어, 최대 50개 특징에 대해, 교차 검증 MCE를 특징 개수에 대한 함수로 플로팅해 보겠습니다.
[fsCVfor50,historyCV] = sequentialfs(classf,dataTrain(:,fs1),grpTrain,... 'cv',tenfoldCVP,'Nf',50); plot(historyCV.Crit,'o'); xlabel('Number of Features'); ylabel('CV MCE'); title('Forward Sequential Feature Selection with cross-validation');

교차 검증 MCE는 10개의 특징을 사용했을 때 최솟값에 도달하며 이 곡선은 특징 개수가 10개에서 35개인 범위에서 평평하게 이어집니다. 또한, 이 곡선은 특징을 35개 넘게 사용했을 때 상승하며, 이는 과적합이 발생했음을 의미합니다.
일반적으로 더 적은 개수의 특징을 사용하는 것이 좋으므로 여기서는 10개의 특징을 선택하겠습니다.
fsCVfor10 = fs1(historyCV.In(10,:))
fsCVfor10 = 1×10
2814 2721 2720 2452 2650 2731 2337 2658 864 3288
순차적 순방향 절차에서 선택된 순서대로 이 10개의 특징을 표시하기 위해 historyCV 출력값에서 가장 먼저 true가 되는 행을 찾습니다.
[orderlist,ignore] = find( [historyCV.In(1,:); diff(historyCV.In(1:10,:) )]' ); fs1(orderlist)
ans = 1×10
2337 864 3288 2721 2814 2658 2452 2731 2650 2720
이 10개 특징을 평가하기 위해 테스트 세트에 대한 QDA의 MCE를 계산해 보겠습니다. 지금까지 구한 MCE 값 중 가장 작은 값을 얻었습니다.
testMCECVfor10 = crossval(classf,obs(:,fsCVfor10),grp,'partition',... holdoutCVP)/holdoutCVP.TestSize
testMCECVfor10 = 0.0357
테스트 세트에 대한 재대입 MCE 값, 즉 특징 선택 절차 중에 교차 검증을 수행하지 않은 MCE 값을 특징 개수에 대한 함수로 플로팅해서 살펴보면 흥미로운 점이 있습니다.
[fsResubfor50,historyResub] = sequentialfs(classf,dataTrain(:,fs1),... grpTrain,'cv','resubstitution','Nf',50); plot(1:50, historyCV.Crit,'bo',1:50, historyResub.Crit,'r^'); xlabel('Number of Features'); ylabel('MCE'); legend({'10-fold CV MCE' 'Resubstitution MCE'},'location','NE');

여기서도 재대입 MCE 값이 지나치게 낙관적입니다. 대부분의 값이 교차 검증 MCE 값보다 작으며, 16개 특징을 사용했을 때 재대입 MCE가 0이 됩니다. 테스트 세트에 대해 이러한 16개 특징의 MCE 값을 계산하여 실제 성능을 확인할 수 있습니다.
fsResubfor16 = fs1(historyResub.In(16,:)); testMCEResubfor16 = crossval(classf,obs(:,fsResubfor16),grp,'partition',... holdoutCVP)/holdoutCVP.TestSize
testMCEResubfor16 = 0.0714
테스트 세트에 대한 이 16개 특징(특징 선택 절차 도중 재대입으로 선택된 특징)의 성능을 나타내는 testMCEResubfor16은 테스트 세트에 대한 10개 특징(특징 선택 절차 도중 10겹 교차 검증으로 선택된 특징)의 성능을 나타내는 testMCECVfor10의 약 두 배에 해당합니다. 재대입 오차가 일반적으로 특징의 평가와 선택에 사용하기에 양호한 성능 추정값이 아님을 다시 한번 확인할 수 있습니다. 따라서 재대입 오차는 최종 평가 단계뿐 아니라 특징 선택 절차에서도 사용하지 않는 것이 좋습니다.