이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
robustfit
로버스트 선형 회귀 피팅
설명
예제
다중 선형 모델의 로버스트 회귀 계수를 추정합니다.
carsmall 데이터 세트를 불러옵니다. 차량 중량과 마력을 예측 변수로 지정하고 갤런당 주행 거리를 응답 변수로 지정합니다.
load carsmall
x1 = Weight;
x2 = Horsepower;
X = [x1 x2];
y = MPG;로버스트 회귀 계수를 계산합니다.
b = robustfit(X,y)
b = 3×1
47.1975
-0.0068
-0.0333
피팅된 모델을 플로팅합니다.
x1fit = linspace(min(x1),max(x1),20); x2fit = linspace(min(x2),max(x2),20); [X1FIT,X2FIT] = meshgrid(x1fit,x2fit); YFIT = b(1) + b(2)*X1FIT + b(3)*X2FIT; mesh(X1FIT,X2FIT,YFIT)
데이터를 플로팅합니다.
hold on scatter3(x1,x2,y,'filled') hold off xlabel('Weight') ylabel('Horsepower') zlabel('MPG') legend('Model','Data') view(50,10) axis tight
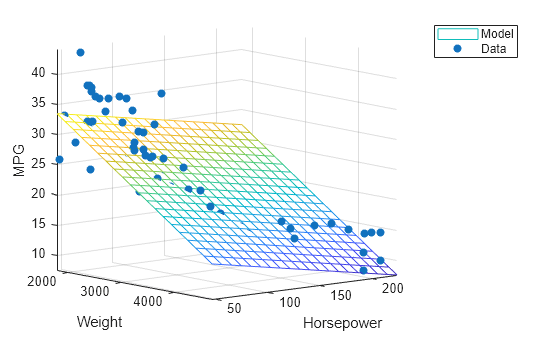
서로 다른 조율 상수를 사용하여 로버스트 회귀의 가중치 함수를 조정합니다.
추세 로 데이터를 생성한 다음, 하나의 값을 변경하여 이상값을 시뮬레이션합니다.
x = (1:10)'; rng ('default') % For reproducibility y = 10 - 2*x + randn(10,1); y(10) = 0;
세 가지 다른 조율 상수에 대해 바이스퀘어 가중치 함수를 사용하여 로버스트 회귀 잔차를 계산합니다. 디폴트 조율 상수는 4.685입니다.
tune_const = [3 4.685 6]; for i = 1:length(tune_const) [~,stats] = robustfit(x,y,'bisquare',tune_const(i)); resids(:,i) = stats.resid; end
잔차에 대한 플롯을 생성합니다.
scatter(x,resids(:,1),'b','filled') hold on plot(resids(:,2),'rx','MarkerSize',10,'LineWidth',2) scatter(x,resids(:,3),'g','filled') plot([min(x) max(x)],[0 0],'--k') hold off grid on xlabel('x') ylabel('Residuals') legend('tune = 3','tune = 4.685','tune = 6','Location','best')
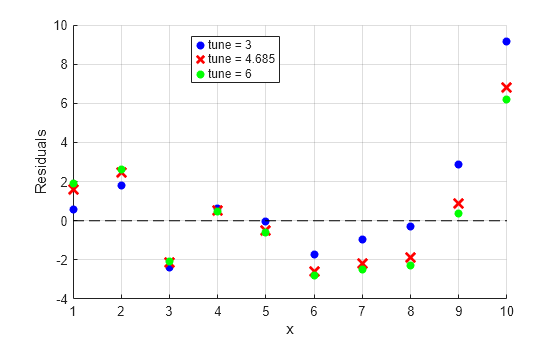
세 가지 다른 조율 상수에 대해 잔차의 RMSE(평균제곱근오차)를 계산합니다.
rmse = sqrt(mean(resids.^2))
rmse = 1×3
3.2577 2.7576 2.7099
조율 상수를 높이면 이상값에 할당된 비중강하 값이 낮아지므로, 조율 상수가 높아지면 RMSE가 낮아집니다.
추세 로 데이터를 생성한 다음, 하나의 값을 변경하여 이상값을 시뮬레이션합니다.
x = (1:10)'; rng('default') % For reproducibility y = 10 - 2*x + randn(10,1); y(10) = 0;
보통최소제곱 회귀를 사용하여 직선을 피팅합니다. 상수항을 갖는 모델의 계수 추정값을 계산하기 위해 x에 1로 구성된 열을 포함합니다.
bls = regress(y,[ones(10,1) x])
bls = 2×1
7.8518
-1.3644
로버스트 회귀 분석을 사용하여 직선 피팅을 추정합니다. robustfit은 기본적으로 모델에 상수항을 추가합니다.
[brob,stats] = robustfit(x,y); brob
brob = 2×1
8.4504
-1.5278
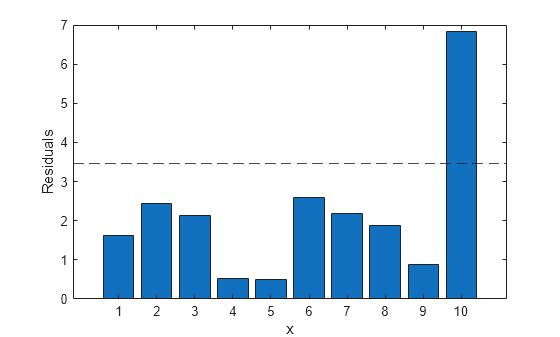
잔차를 잔차의 중앙값절대편차와 비교하여 잠재적 이상값을 식별합니다.
outliers_ind = find(abs(stats.resid)>stats.mad_s);
로버스트 회귀 분석에 대한 잔차의 막대 그래프를 플로팅합니다.
bar(abs(stats.resid)) hold on yline(stats.mad_s,'k--') hold off xlabel('x') ylabel('Residuals')
데이터에 대한 산점도 플롯을 생성합니다.
scatter(x,y,'filled')이상값을 플로팅합니다.
hold on plot(x(outliers_ind),y(outliers_ind),'mo','LineWidth',2)
최소제곱 및 로버스트 피팅을 플로팅합니다.
plot(x,bls(1)+bls(2)*x,'r') plot(x,brob(1)+brob(2)*x,'g') hold off xlabel('x') ylabel('y') legend('Data','Outlier','Ordinary Least Squares','Robust Regression') grid on
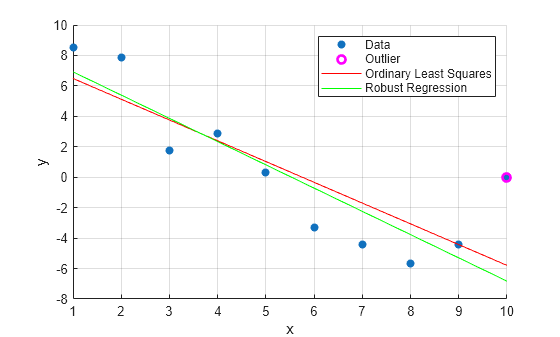
이상값은 최소제곱 피팅보다 로버스트 피팅에 미치는 영향이 적습니다.
입력 인수
출력 인수
세부 정보
알고리즘
robustfit은 반복 재가중 최소제곱을 사용하여 계수b를 구합니다. 입력wfun이 가중치를 지정합니다.robustfit은inv(X'*X)*stats.s^2식을 사용하여 계수 추정값의 분산-공분산 행렬stats.covb를 추정합니다. 이 추정을 통해 계수 표준 오차stats.se와 상관stats.coeffcorr이 구해집니다.선형 모델에서
y의 관측값과 그 잔차는 확률 변수입니다. 잔차는 평균이 0이지만 예측 변수의 여러 값에서 다른 분산을 갖는 정규분포를 가집니다. 잔차를 비교 가능한 스케일로 만들기 위해robustfit은 잔차를 “스튜던트화”합니다. 즉,robustfit은 잔차 값과는 독립적인 표준편차 추정값으로 잔차를 나눕니다. 스튜던트화 잔차는 알려진 자유도를 갖는 t-분포를 가집니다.robustfit은 스튜던트화된 잔차를stats.rstud로 반환합니다.
대체 기능
robustfit은 단순히 함수의 출력 인수가 필요하거나 루프에서 모델을 여러 차례 반복 피팅하는 경우에 유용합니다. 로버스트 피팅 회귀 모델을 추가로 조사하려면 fitlm을 사용하여 선형 회귀 모델 객체 LinearModel을 생성하십시오. 이름-값 쌍 인수 'RobustOpts'의 값을 'on'으로 설정합니다.
참고 문헌
[1] DuMouchel, W. H., and F. L. O'Brien. “Integrating a Robust Option into a Multiple Regression Computing Environment.” Computer Science and Statistics: Proceedings of the 21st Symposium on the Interface. Alexandria, VA: American Statistical Association, 1989.
[2] Holland, P. W., and R. E. Welsch. “Robust Regression Using Iteratively Reweighted Least-Squares.” Communications in Statistics: Theory and Methods, A6, 1977, pp. 813–827.
[3] Huber, P. J. Robust Statistics. Hoboken, NJ: John Wiley & Sons, Inc., 1981.
[4] Street, J. O., R. J. Carroll, and D. Ruppert. “A Note on Computing Robust Regression Estimates via Iteratively Reweighted Least Squares.” The American Statistician. Vol. 42, 1988, pp. 152–154.
버전 내역
R2006a 이전에 개발됨