비선형 로지스틱 회귀
이 예제에서는 비선형 로지스틱 회귀 모델을 피팅하는 두 가지 방법을 보여줍니다. 첫 번째 방법에서는 ML(최대가능도)을 사용하고, 두 번째 방법에서는 Statistics and Machine Learning Toolbox™의 함수 fitnlm을 통해 GLS(일반화 최소제곱)를 사용합니다.
문제 설명
로지스틱 회귀는 특정 항목에 대한 확률을 다른 변수의 함수로 모델링하는 것을 목표로 하는, 회귀의 특별한 유형입니다. 예측 변수 벡터의 세트 이 있다고 가정해 보겠습니다. 여기서 은 관측값 개수이고, 는 번째 관측값에 대한 개 예측 변수의 값이 포함된 열 벡터입니다. 에 대한 응답 변수는 입니다. 여기서 는 시행 횟수에 해당하는 모수 과 시행 에 대한 성공 확률에 해당하는 모수 를 포함한 이항 확률 변수를 나타냅니다. 정규화된 응답 변수는 으로, 관측값 에 대해 번 시행 시의 성공 확률입니다. 응답 변수 는 에 대해 독립적이라고 가정합니다. 각 에 대해 다음과 같습니다.
.
를 예측 변수 의 함수로 모델링한다고 가정해 보겠습니다.
선형 로지스틱 회귀에서는 다음과 같이 함수 fitglm을 사용하여 를 의 함수로 모델링할 수 있습니다.
이때 는 의 예측 변수에 곱하는 계수 집합을 나타냅니다. 그러나 다음과 같이 우변이 비선형 함수여야 하는 경우가 있을 수 있습니다.
Statistics and Machine Learning Toolbox™에는 비선형 회귀 모델을 피팅하는 함수가 있지만 이들 함수는 비선형 로지스틱 회귀 모델은 피팅하지 못합니다. 이 예제에서는 툴박스 함수를 사용하여 그러한 모델을 피팅하는 방법을 보여줍니다.
직접 ML(최대가능도)
ML 접근법은 관측된 데이터의 로그 가능도를 최대화합니다. 가능도는 binopdf 함수로 계산된 이항 확률 (또는 밀도) 함수를 사용하여 쉽게 계산됩니다.
GLS(일반화 최소제곱)
함수 fitnlm을 사용하여 비선형 로지스틱 회귀 모델을 추정할 수 있습니다. fitnlm이 이항분포 또는 어떠한 연결 함수도 수용하지 못한다는 것을 생각하면 처음에는 이 점이 의외로 여겨질 수 있습니다. 그러나 응답 변수의 평균과 분산을 지정할 경우 fitnlm은 GLS(일반화 최소제곱)를 사용하여 모델을 추정할 수 있습니다. GLS가 수렴되는 경우 ML과 마찬가지로 동일한 세트의 비선형 방정식에 대해 해를 구하여 를 추정합니다. 또한 GLS를 사용하여 일반화 선형 모델의 준가능도를 추정할 수 있습니다. 다시 말해서, GLS와 ML로부터 동일한 혹은 동등한 해를 구할 수 있습니다. GLS 추정을 구현하려면, 피팅할 비선형 함수와 이항분포에 대한 분산 함수를 제공하십시오.
평균 함수 또는 모델 함수
모델 함수는 가 에 따라 어떻게 변하는지 설명합니다. fitnlm을 사용할 경우 모델 함수는 다음과 같습니다.
가중치 함수
fitnlm은 'Weights' 이름-값 쌍의 인수를 사용하여 관측값 가중치를 함수 핸들로 받습니다. 이 옵션을 사용할 경우 fitnlm은 모델을 다음과 같이 가정합니다.
여기서 응답 변수 는 독립 변수로 간주되고, 는 를 받고 관측값 가중치를 반환하는 사용자 지정 함수 핸들입니다. 즉, 가중치는 응답 변수 분산에 반비례합니다. 로지스틱 회귀 모델에 사용할 이항분포에 대해 가중치 함수를 다음과 같이 생성하십시오.
fitnlm은 응답 변수 의 분산을 로 모델링합니다. 여기서 는 GLS 추정에는 있지만, 로지스틱 회귀 모델에는 없는 추가 모수입니다. 그러나 이 모수는 대개 추정에 영향을 미치지 않으며, 값이 이항분포를 갖는다는 가정을 확인하기 위한 "산포 모수"를 제공합니다.
직접 ML과 비교하여 fitnlm을 사용할 때의 이점은 가설검정을 수행할 수 있고 모델 계수에 대한 신뢰구간을 계산할 수 있다는 점입니다.
예제 데이터 생성하기
ML 피팅과 GLS 피팅의 차이점을 살펴보기 위해 예제 데이터를 생성합니다. 는 1차원이라고 가정하고, 비선형 로지스틱 회귀 모델에서 실제 함수 는 벡터 로 모수화된 Michaelis-Menten 모델이라고 가정하겠습니다.
myf = @(beta,x) beta(1)*x./(beta(2) + x);
와 간의 관계를 지정하는 모델 함수를 만듭니다.
mymodelfun = @(beta,x) 1./(1 + exp(-myf(beta,x)));
1차원 예측 변수로 구성된 벡터와 실제 계수 벡터 를 만듭니다.
rng(300,'twister');
x = linspace(-1,1,200)';
beta = [10;2];각 예측 변수에 대한 값으로 구성된 벡터를 계산합니다.
mu = mymodelfun(beta,x);
성공 확률 및 시행 횟수 인 이항분포에서 응답 변수 를 생성합니다.
n = 50; z = binornd(n,mu);
응답 변수를 정규화합니다.
y = z./n;
ML 접근법
ML 접근법은 음의 로그 가능도를 벡터의 함수로 정의한 다음, 이 로그 가능도를 fminsearch와 같은 최적화 함수를 사용하여 최소화합니다. beta0를 의 시작 값으로 지정합니다.
mynegloglik = @(beta) -sum(log(binopdf(z,n,mymodelfun(beta,x))));
beta0 = [3;3];
opts = optimset('fminsearch');
opts.MaxFunEvals = Inf;
opts.MaxIter = 10000;
betaHatML = fminsearch(mynegloglik,beta0,opts)betaHatML = 2×1
9.9259
1.9720
betaHatML에 있는 추정된 계수가 실제 값인 [10;2]에 가깝습니다.
GLS 접근법
GLS 접근법은 앞에서 설명한 fitnlm에 대한 가중치 함수를 생성합니다.
wfun = @(xx) n./(xx.*(1-xx));
사용자 지정 평균 함수와 가중치 함수를 사용하여 fitnlm을 호출합니다. beta0를 의 시작 값으로 지정합니다.
nlm = fitnlm(x,y,mymodelfun,beta0,'Weights',wfun)nlm =
Nonlinear regression model:
y ~ F(beta,x)
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ __________
b1 9.926 0.83135 11.94 4.193e-25
b2 1.972 0.16438 11.996 2.8182e-25
Number of observations: 200, Error degrees of freedom: 198
Root Mean Squared Error: 1.16
R-Squared: 0.995, Adjusted R-Squared 0.995
F-statistic vs. zero model: 1.88e+04, p-value = 2.04e-226
피팅된 NonLinearModel 객체 nlm에서 의 추정값을 구합니다.
betaHatGLS = nlm.Coefficients.Estimate
betaHatGLS = 2×1
9.9260
1.9720
ML 방법에서와 마찬가지로, betaHatGLS에 있는 추정된 계수가 실제 값인 [10;2]에 가깝습니다. 과 둘 다 p-값이 작은 것은 두 계수가 과 현저히 다르다는 것을 나타냅니다.
ML 접근법과 GLS 접근법 비교하기
의 추정값을 비교합니다.
max(abs(betaHatML - betaHatGLS))
ans = 1.1460e-05
ML과 GLS를 사용하여 피팅된 값을 비교합니다.
yHatML = mymodelfun(betaHatML ,x); yHatGLS = mymodelfun(betaHatGLS,x); max(abs(yHatML - yHatGLS))
ans = 1.2746e-07
ML 접근법과 GLS 접근법이 유사한 해를 생성합니다.
ML과 GLS를 사용하여 피팅된 값 플로팅하기
figure plot(x,y,'g','LineWidth',1) hold on plot(x,yHatML ,'b' ,'LineWidth',1) plot(x,yHatGLS,'m--','LineWidth',1) legend('Data','ML','GLS','Location','Best') xlabel('x') ylabel('y and fitted values') title('Data y along with ML and GLS fits.')
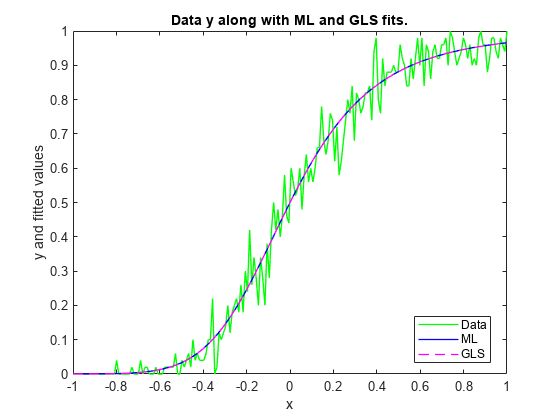
ML과 GLS가 유사한 피팅값을 생성합니다.
ML과 GLS를 사용하여 추정된 비선형 함수 플로팅하기
에 대한 실제 모델을 플로팅합니다. 을 사용하여 의 초기 추정값에 대한 플롯을 추가하고, ML과 GLS를 기반으로 한 추정값에 대한 플롯을 추가합니다.
figure plot(x,myf(beta,x),'r','LineWidth',1) hold on plot(x,myf(beta0,x),'k','LineWidth',1) plot(x,myf(betaHatML,x),'c--','LineWidth',1) plot(x,myf(betaHatGLS,x),'b-.','LineWidth',1) legend('True f','Initial f','Estimated f with ML', ... 'Estimated f with GLS','Location','Best') xlabel('x') ylabel('True and estimated f') title('Comparison of true f with estimated f using ML and GLS.')
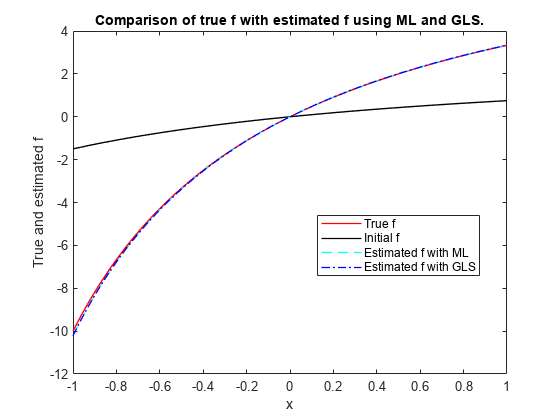
ML 방법과 GLS 방법을 사용하여 추정한 비선형 함수 가 둘 다 실제 비선형 함수 에 근접합니다. 이와 비슷한 기법을 사용하여 비선형 푸아송 회귀 같은 다른 비선형 일반화 선형 모델을 피팅할 수 있습니다.