fscchi2
Univariate feature ranking for classification using chi-square tests
Syntax
Description
idx = fscchi2(Tbl,ResponseVarName)Tbl contains predictor variables and a response variable,
and ResponseVarName is the name of the response variable in
Tbl. The function returns idx, which contains
the indices of predictors ordered by predictor importance, meaning
idx(1) is the index of the most important predictor. You can use
idx to select important predictors for classification
problems.
idx = fscchi2(___,Name,Value)
Examples
Rank predictors in a numeric matrix and create a bar plot of predictor importance scores.
Load the sample data.
load ionosphereionosphere contains predictor variables (X) and a response variable (Y).
Rank the predictors using chi-square tests.
[idx,scores] = fscchi2(X,Y);
The values in scores are the negative logs of the p-values. If a p-value is smaller than eps(0), then the corresponding score value is Inf. Before creating a bar plot, determine whether scores includes Inf values.
find(isinf(scores))
ans = 1×0 empty double row vector
scores does not include Inf values. If scores includes Inf values, you can replace Inf by a large numeric number before creating a bar plot for visualization purposes. For details, see Rank Predictors in Table.
Create a bar plot of the predictor importance scores.
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score')
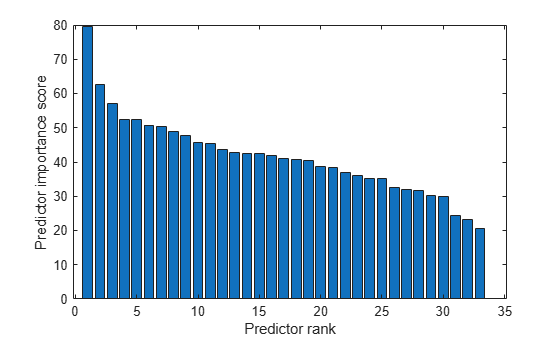
Select the top five most important predictors. Find the columns of these predictors in X.
idx(1:5)
ans = 1×5
5 7 3 8 6
The fifth column of X is the most important predictor of Y.
Rank predictors in a table and create a bar plot of predictor importance scores.
If your data is in a table and fscchi2 ranks a subset of the variables in the table, then the function indexes the variables using only the subset. Therefore, a good practice is to move the predictors that you do not want to rank to the end of the table. Move the response variable and observation weight vector as well. Then, the indexes of the output arguments are consistent with the indexes of the table.
Load the census1994 data set.
load census1994The table adultdata in census1994 contains demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year. Display the first three rows of the table.
head(adultdata,3)
age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
In the table adultdata, the third column fnlwgt is the weight of the samples, and the last column salary is the response variable. Move fnlwgt to the left of salary by using the movevars function.
adultdata = movevars(adultdata,'fnlwgt','before','salary'); head(adultdata,3)
age workClass education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country fnlwgt salary
___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______
39 State-gov Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States 77516 <=50K
50 Self-emp-not-inc Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States 83311 <=50K
38 Private HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States 2.1565e+05 <=50K
Rank the predictors in adultdata. Specify the column salary as a response variable, and specify the column fnlwgt as observation weights.
[idx,scores] = fscchi2(adultdata,'salary','Weights','fnlwgt');
The values in scores are the negative logs of the p-values. If a p-value is smaller than eps(0), then the corresponding score value is Inf. Before creating a bar plot, determine whether scores includes Inf values.
idxInf = find(isinf(scores))
idxInf = 1×8
1 3 4 5 6 7 10 12
scores includes eight Inf values.
Create a bar plot of predictor importance scores. Use the predictor names for the x-axis tick labels.
figure bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score') xticklabels(strrep(adultdata.Properties.VariableNames(idx),'_','\_')) xtickangle(45)
The bar function does not plot any bars for the Inf values. For the Inf values, plot bars that have the same length as the largest finite score.
hold on bar(scores(idx(length(idxInf)+1))*ones(length(idxInf),1)) legend('Finite Scores','Inf Scores') hold off
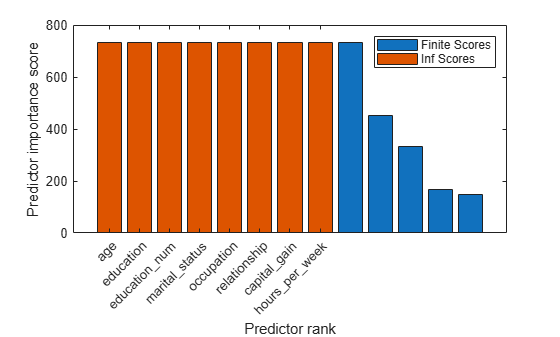
The bar graph displays finite scores and Inf scores using different colors.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
Version History
Introduced in R2020a