강화 학습 워크플로
강화 학습을 사용한 에이전트 훈련의 일반적인 워크플로는 다음 단계로 구성됩니다.
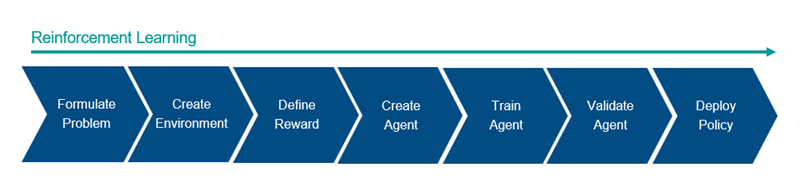
문제 정식화 — 에이전트와 환경의 상호 작용 방식, 에이전트가 완수해야 할 주요 목표와 부수 목표 등 에이전트가 학습할 작업을 정의합니다.
환경 만들기 — 에이전트와 환경, 환경 동특성 모델 간의 인터페이스를 포함하여 에이전트가 동작할 환경을 정의합니다. 자세한 내용은 Reinforcement Learning Environments 항목을 참조하십시오.
보상 정의 — 에이전트가 작업 목표와 비교해 성능을 측정하기 위해 사용하는 보상 신호를 지정하고, 환경에서 이 신호를 계산하는 방법을 지정합니다. 자세한 내용은 Define Observation and Reward Signals in Custom Environments 항목을 참조하십시오.
에이전트 만들기 — 에이전트를 만듭니다. 디폴트 내장 에이전트를 만들거나, 사용자 지정 actor 객체와 critic 객체를 가진 내장 에이전트를 만들 수 있습니다. 자세한 내용은 Create Actors, Critics, and Policy Objects 항목과 강화 학습 에이전트 항목을 참조하십시오.
에이전트 훈련 — 정의된 환경과 보상, 에이전트 학습 알고리즘을 사용하여 에이전트 근사기를 훈련시킵니다. 자세한 내용은 강화 학습 에이전트 훈련시키기 항목을 참조하십시오.
에이전트 시뮬레이션 — 에이전트와 환경을 함께 시뮬레이션하여, 훈련된 에이전트의 성능을 평가합니다. 자세한 내용은 강화 학습 에이전트 훈련시키기 항목을 참조하십시오.
정책 배포 — 훈련된 정책 근사기를 생성된 GPU 코드 등을 사용하여 배포합니다. 자세한 내용은 Generate Code from Trained Reinforcement Learning Policies 항목을 참조하십시오.
강화 학습을 사용해 에이전트를 훈련시키는 작업은 반복 과정입니다. 후반 단계에서의 결정과 결과에 따라 학습 워크플로의 초기 단계로 되돌아가야 할 수도 있습니다. 예를 들어 훈련 과정이 적절한 시간 내에 최적의 정책으로 수렴하지 않으면, 에이전트를 다시 훈련시키기 전에 다음 중 일부를 업데이트해야 할 수 있습니다.
훈련 설정
학습 알고리즘 구성
정책 및 가치 함수(액터 및 크리틱) 근사기
보상 신호 정의
행동 및 관측값 신호
환경 동특성