범주 히스토그램 표시 제어하기
이 예제에서는 histogram을 사용하여 categorical형 데이터를 효과적으로 확인하는 방법을 보여줍니다. 이름-값 쌍 'NumDisplayBins', 'DisplayOrder', 'ShowOthers'를 사용하여 범주 히스토그램의 표시를 변경할 수 있습니다. 이러한 옵션은 데이터를 구성하고 플롯의 잡음을 줄이는 데 도움이 됩니다.
범주 히스토그램 생성하기
표본 파일 outages.csv에는 미국 내의 정전 기록을 나타내는 데이터가 들어 있습니다. 이 파일에는 Region, OutageTime, Loss, Customers, RestorationTime, Cause와 같은 6개 열이 포함되어 있습니다.
outages.csv 파일을 테이블로 읽어 들입니다. 'Format' 옵션을 사용하여 각 열에 포함되는 데이터 유형, 즉 categorical형('%C'), 부동 소수점 숫자형('%f') 또는 datetime형('%D')을 지정합니다. 처음 몇 개의 데이터 행에 들어 있는 요소를 참조하여 변수를 확인합니다.
data_formats = '%C%D%f%f%D%C'; C = readtable('outages.csv','Format',data_formats); first_few_rows = C(1:10,:)
first_few_rows=10×6 table
Region OutageTime Loss Customers RestorationTime Cause
_________ ________________ ______ __________ ________________ _______________
SouthWest 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 winter storm
SouthEast 2003-01-23 00:49 530.14 2.1204e+05 NaT winter storm
SouthEast 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 winter storm
West 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 equipment fault
MidWest 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 severe storm
West 2003-06-18 02:49 0 0 2003-06-18 10:54 attack
West 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 equipment fault
West 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 equipment fault
NorthEast 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 fire
MidWest 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 equipment fault
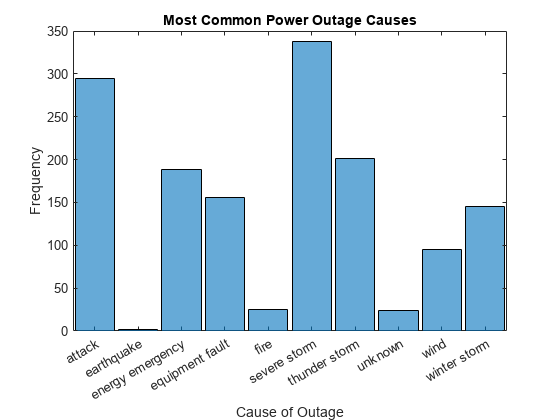
Cause 변수의 범주 히스토그램을 플로팅합니다. 출력 인수를 지정하여 histogram 객체에 대한 핸들을 반환합니다.
h = histogram(C.Cause); xlabel('Cause of Outage') ylabel('Frequency') title('Most Common Power Outage Causes')
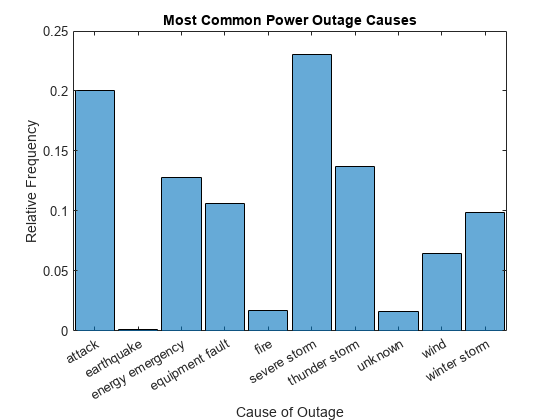
'probability' 정규화를 사용하도록 히스토그램의 정규화를 변경합니다. 이는 각 정전 원인의 상대 빈도를 표시합니다.
h.Normalization = 'probability'; ylabel('Relative Frequency')
디스플레이 순서 변경하기
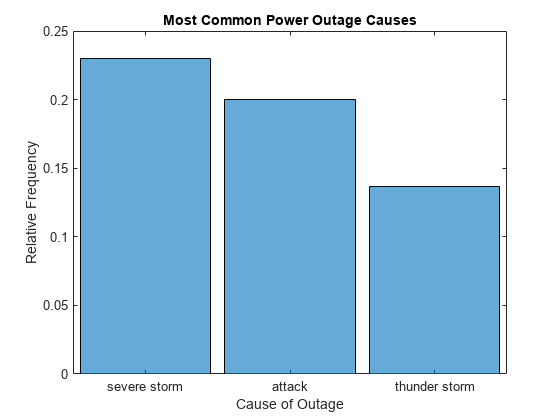
'DisplayOrder' 옵션을 사용하여 Bin을 가장 큰 값부터 가장 작은 값 순서로 정렬합니다.
h.DisplayOrder = 'descend';
표시되는 막대 개수 줄이기
'NumDisplayBins' 옵션을 사용하여 플롯에 막대를 3개만 표시합니다. 표시되지 않은 데이터도 여전히 정규화 계산에 포함되므로 표시된 확률의 합이 더 이상 1이 아닙니다.
h.NumDisplayBins = 3;
배제된 데이터 요약하기
표시된 확률의 합이 다시 1이 되도록 'ShowOthers' 옵션을 사용하여 모든 제외된 막대를 요약합니다.
h.ShowOthers = 'on';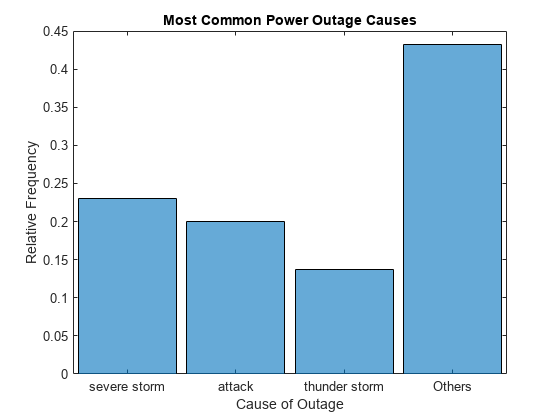
정규화를 표시되는 데이터로 제한하기
R2017a 이전에서는 histogram 함수와 histcounts 함수가 정규화를 계산할 때 비닝(Binning)된 데이터만 사용했습니다. 이 동작은 데이터 중 Bin 범위를 벗어난 데이터는 정규화 계산에서 무시되었음을 의미합니다. 하지만 MATLAB® R2017a에서는 항상 입력 데이터의 총 요소 개수를 사용하여 정규화하도록 이 동작이 변경되었습니다. 새로운 동작이 더 직관적이지만 사용자가 이전 동작을 선호한다면, 정규화를 비닝된 데이터로만 제한하도록 몇 가지 특별한 단계를 수행해야 합니다.
모든 입력 데이터를 정규화하는 대신, 확률 정규화를 히스토그램에 표시된 데이터로 제한할 수 있습니다. 다른 범주를 제거하도록 histogram 객체의 Data 속성을 업데이트하기만 하면 됩니다. Categories 속성은 히스토그램에 표시된 범주를 반영합니다. setdiff를 사용하여 두 속성값을 비교하고 Categories에 없는 범주를 Data에서 제거합니다. 그런 다음, 결과로 생성된 모든 undefined categorical형 요소를 데이터에서 제거하여, 표시된 범주에 있는 요소만 남깁니다.
h.ShowOthers = 'off';
cats_to_remove = setdiff(categories(h.Data),h.Categories);
h.Data = removecats(h.Data,cats_to_remove);
h.Data = rmmissing(h.Data);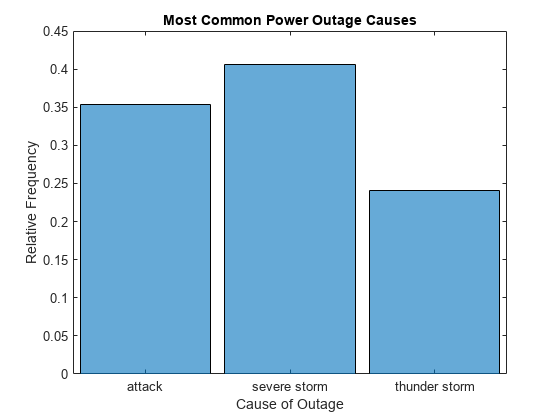
이제 남아있는 3개 범주만 사용하여 정규화되므로 3개 막대 높이의 합이 1이 됩니다.